Parameter Efficient Mamba Tuning via Projector-targeted Diagonal-centric Linear Transformation
作者: Seokil Ham, Hee-Seon Kim, Sangmin Woo, Changick Kim
分类: cs.LG, cs.AI
发布日期: 2024-11-21 (更新: 2025-03-24)
备注: accepted in CVPR 2025
💡 一句话要点
提出ProDiaL,一种针对Mamba投影层的参数高效微调方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Mamba模型 参数高效微调 迁移学习 投影层优化 对角中心线性变换
📋 核心要点
- 现有Mamba模型的参数高效微调方法研究不足,限制了其在资源受限场景的应用。
- ProDiaL通过对角中心线性变换,仅优化Mamba模型的投影层,实现高效的任务迁移。
- 实验表明,ProDiaL使用不到1%的参数,在视觉和语言任务上均表现出强大的性能。
📝 摘要(中文)
尽管Mamba架构作为Transformer架构的潜在替代品越来越受到关注,但针对Mamba的参数高效微调(PEFT)方法仍未得到充分探索。本研究提出了两种关键洞察驱动的Mamba架构PEFT策略:(1)虽然状态空间模型(SSM)被认为是Mamba架构的基石,并被期望在迁移学习中发挥主要作用,但我们的研究结果表明,投影层(Projectors)而非SSM是迁移学习的主要贡献者。(2)基于此观察,我们提出了一种专门针对Mamba架构的新型PEFT方法:面向投影层的对角中心线性变换(ProDiaL)。ProDiaL专注于通过对角中心线性变换矩阵优化预训练的投影层以适应新任务,而无需直接微调投影层的权重。这种有针对性的方法能够实现高效的任务适应,使用的参数不到总参数的1%,并在视觉和语言Mamba模型中表现出强大的性能,突显了其通用性和有效性。
🔬 方法详解
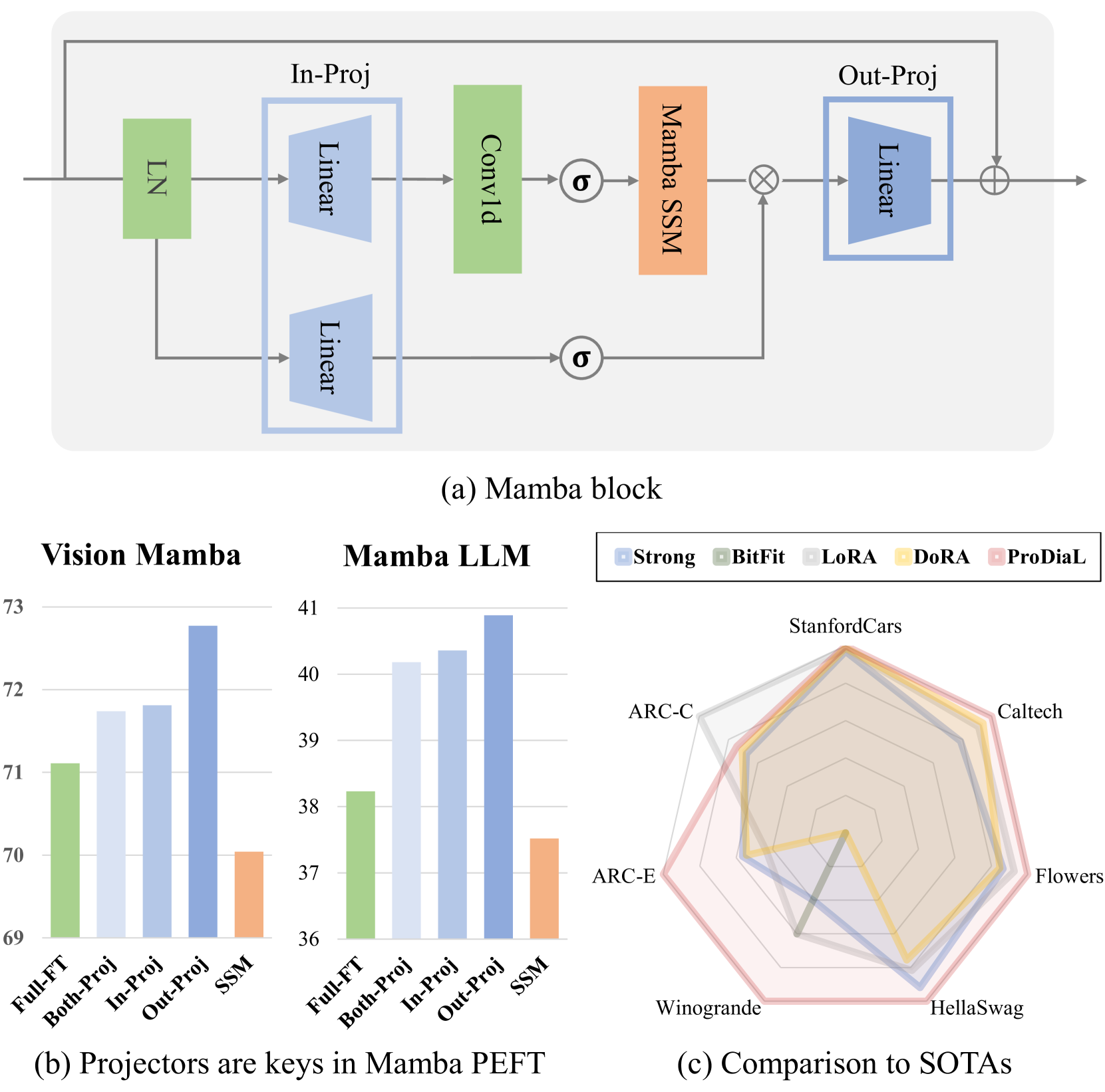
问题定义:论文旨在解决Mamba模型在迁移学习中参数效率低下的问题。现有方法通常直接微调整个Mamba模型,导致参数量巨大,计算成本高昂,难以在资源受限的场景下应用。论文发现,Mamba模型中的投影层在迁移学习中起着关键作用,而现有PEFT方法并未充分利用这一特性。
核心思路:论文的核心思路是,通过专注于优化Mamba模型中的投影层,实现参数高效的迁移学习。具体而言,论文提出了一种新的PEFT方法,称为Projector-targeted Diagonal-centric Linear Transformation (ProDiaL),该方法通过对角中心线性变换矩阵来调整预训练的投影层,而无需直接微调投影层的权重。
技术框架:ProDiaL方法主要包含以下步骤:1) 冻结Mamba模型中除投影层之外的所有参数;2) 为每个投影层引入一个对角中心线性变换矩阵;3) 使用目标任务的数据集,仅优化这些线性变换矩阵的参数;4) 将优化后的线性变换矩阵应用于预训练的投影层,从而实现任务适应。
关键创新:ProDiaL的关键创新在于,它首次揭示了Mamba模型中投影层在迁移学习中的重要性,并提出了一种专门针对投影层的参数高效微调方法。与现有方法相比,ProDiaL无需微调整个Mamba模型,而是通过对角中心线性变换矩阵来调整预训练的投影层,从而大大减少了需要优化的参数量。
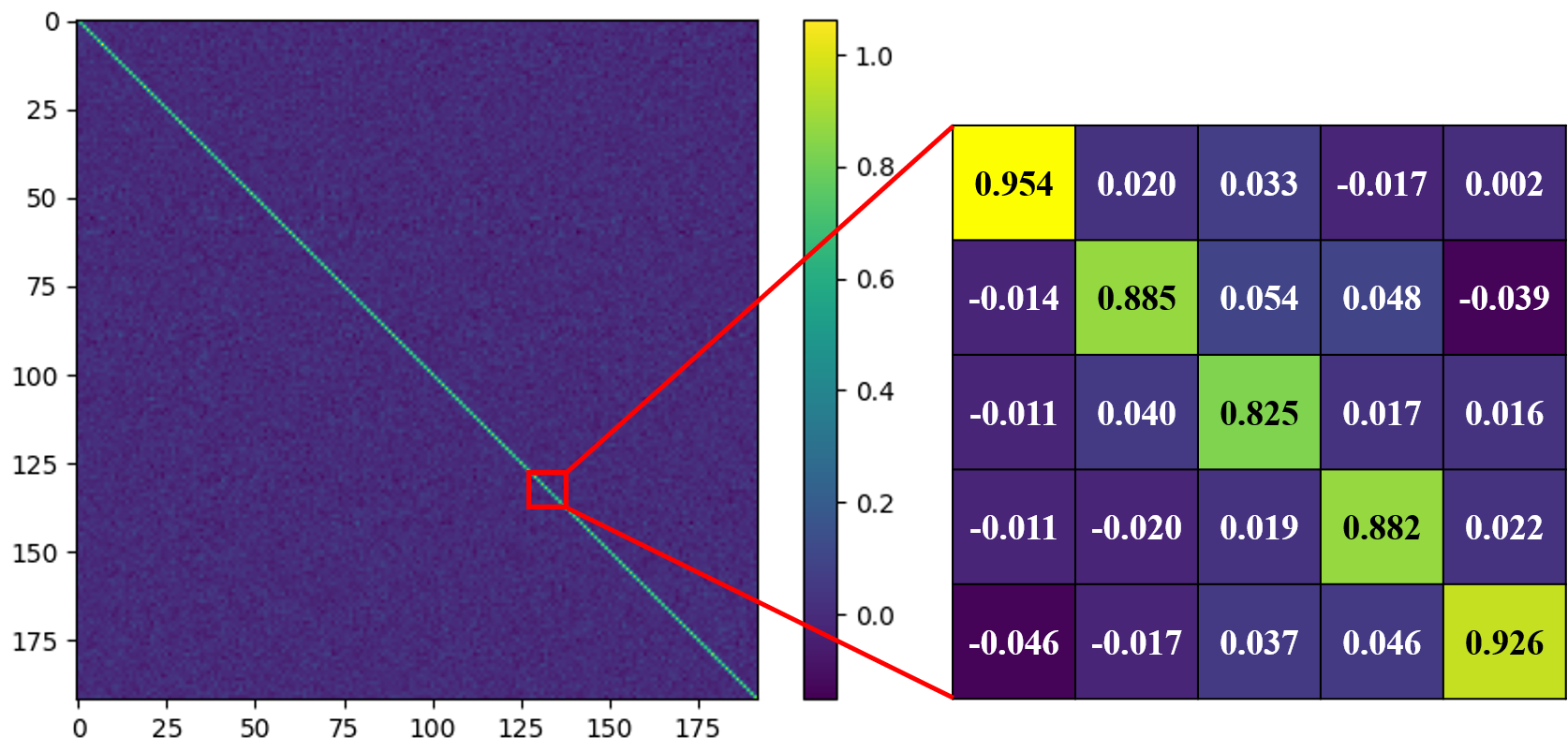
关键设计:ProDiaL的关键设计包括:1) 使用对角中心线性变换矩阵,以确保变换后的投影层权重不会偏离原始预训练权重太远,从而保持模型的泛化能力;2) 仅优化线性变换矩阵的参数,而冻结其他参数,以实现参数高效的微调;3) 针对不同的任务和数据集,可以调整线性变换矩阵的维度和学习率等超参数,以获得最佳性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ProDiaL方法使用不到1%的参数,在视觉和语言Mamba模型上均取得了显著的性能提升。例如,在图像分类任务中,ProDiaL方法在保持甚至超过全参数微调性能的同时,参数量减少了99%以上。此外,ProDiaL方法在各种不同的任务和数据集上都表现出良好的通用性。
🎯 应用场景
ProDiaL方法可应用于各种需要高效迁移学习的场景,例如:在计算资源有限的边缘设备上部署Mamba模型;快速适应新的视觉或语言任务;在数据量较小的场景下进行模型微调。该方法有望推动Mamba模型在实际应用中的普及。
📄 摘要(原文)
Despite the growing interest in Mamba architecture as a potential replacement for Transformer architecture, parameter-efficient fine-tuning (PEFT) approaches for Mamba remain largely unexplored. In our study, we introduce two key insights-driven strategies for PEFT in Mamba architecture: (1) While state-space models (SSMs) have been regarded as the cornerstone of Mamba architecture, then expected to play a primary role in transfer learning, our findings reveal that Projectors -- not SSMs -- are the predominant contributors to transfer learning. (2) Based on our observation, we propose a novel PEFT method specialized to Mamba architecture: Projector-targeted Diagonal-centric Linear Transformation (ProDiaL). ProDiaL focuses on optimizing only the pretrained Projectors for new tasks through diagonal-centric linear transformation matrices, without directly fine-tuning the Projector weights. This targeted approach allows efficient task adaptation, utilizing less than 1% of the total parameters, and exhibits strong performance across both vision and language Mamba models, highlighting its versatility and effectiveness.