Rethinking the Intermediate Features in Adversarial Attacks: Misleading Robotic Models via Adversarial Distillation
作者: Ke Zhao, Huayang Huang, Miao Li, Yu Wu
分类: cs.LG, cs.AI, cs.RO
发布日期: 2024-11-21
💡 一句话要点
提出基于对抗蒸馏的对抗提示攻击,用于欺骗语言条件机器人模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗攻击 机器人学习 语言条件 对抗蒸馏 中间特征 自注意力 安全性
📋 核心要点
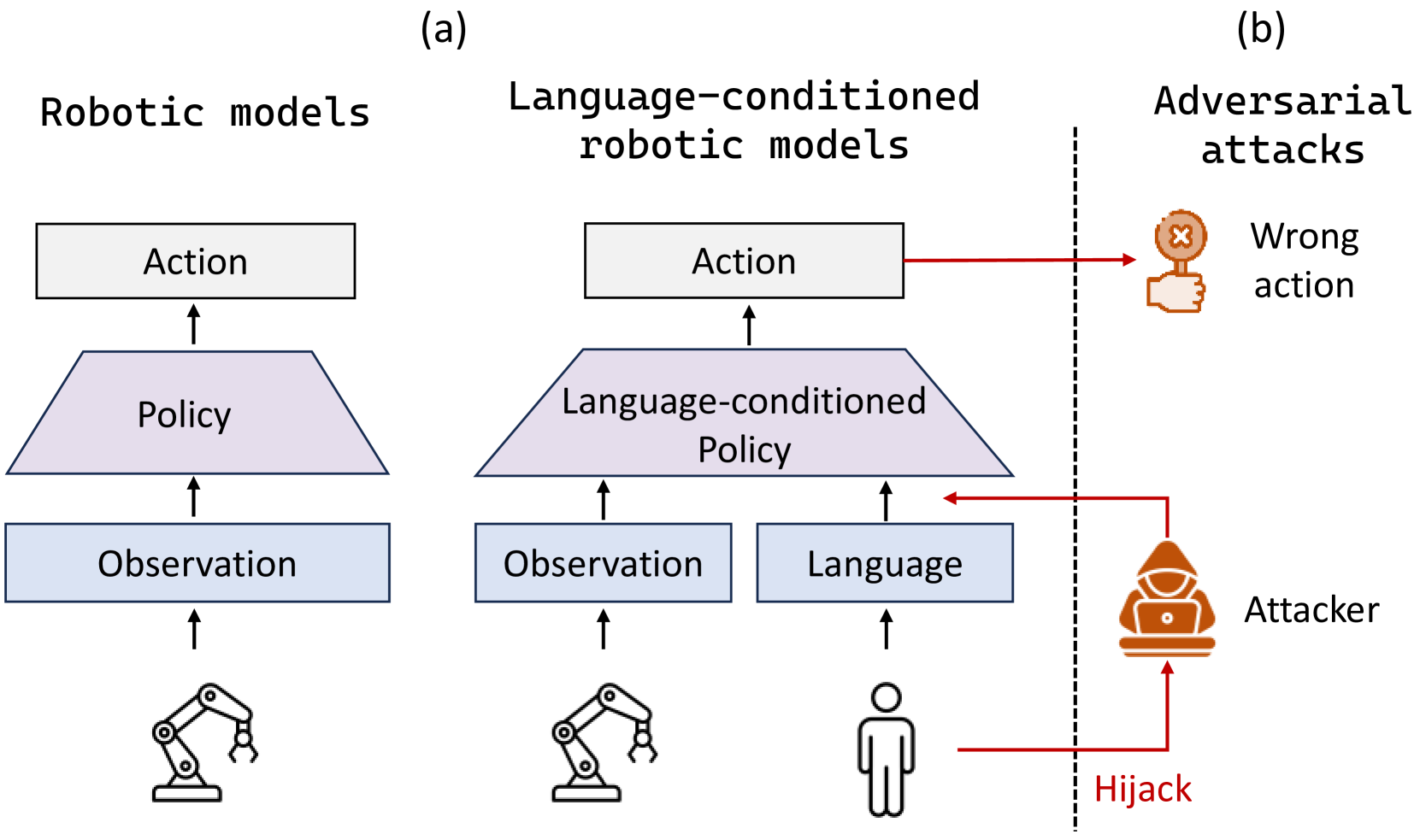
- 语言条件机器人学习通过使单个模型能够响应口头命令执行各种任务,从而显著提高了机器人适应性,但该领域的安全性漏洞尚未得到充分探索。
- 该论文提出了一种对抗提示攻击,通过优化连续动作空间的对抗前缀,并利用中间自注意力特征的负梯度来增强攻击效果。
- 在VIMA模型上进行的实验表明,该方法在13个机器人操作任务中优于现有方法,并具有良好的模型迁移性。
📝 摘要(中文)
本文提出了一种新颖的对抗提示攻击,专门针对语言条件机器人模型。该方法通过构造一个通用的对抗前缀,添加到任何原始提示时,都会诱导模型执行非预期动作。由于离散化机器人动作空间的固有鲁棒性,直接将现有的对抗技术迁移到机器人领域效果有限。为了解决这个问题,本文提出基于连续动作表示优化对抗前缀,绕过离散化过程。此外,本文还发现中间特征对对抗攻击有益,并利用中间自注意力特征的负梯度来进一步提高攻击效果。在13个机器人操作任务的VIMA模型上的大量实验验证了该方法优于现有方法,并证明了其在不同模型变体中的可迁移性。
🔬 方法详解
问题定义:现有对抗攻击方法在语言条件机器人模型上效果不佳,主要是因为机器人动作空间通常是离散的,这使得直接应用对抗攻击难以奏效。此外,如何有效地利用模型内部的特征信息来增强攻击效果也是一个挑战。
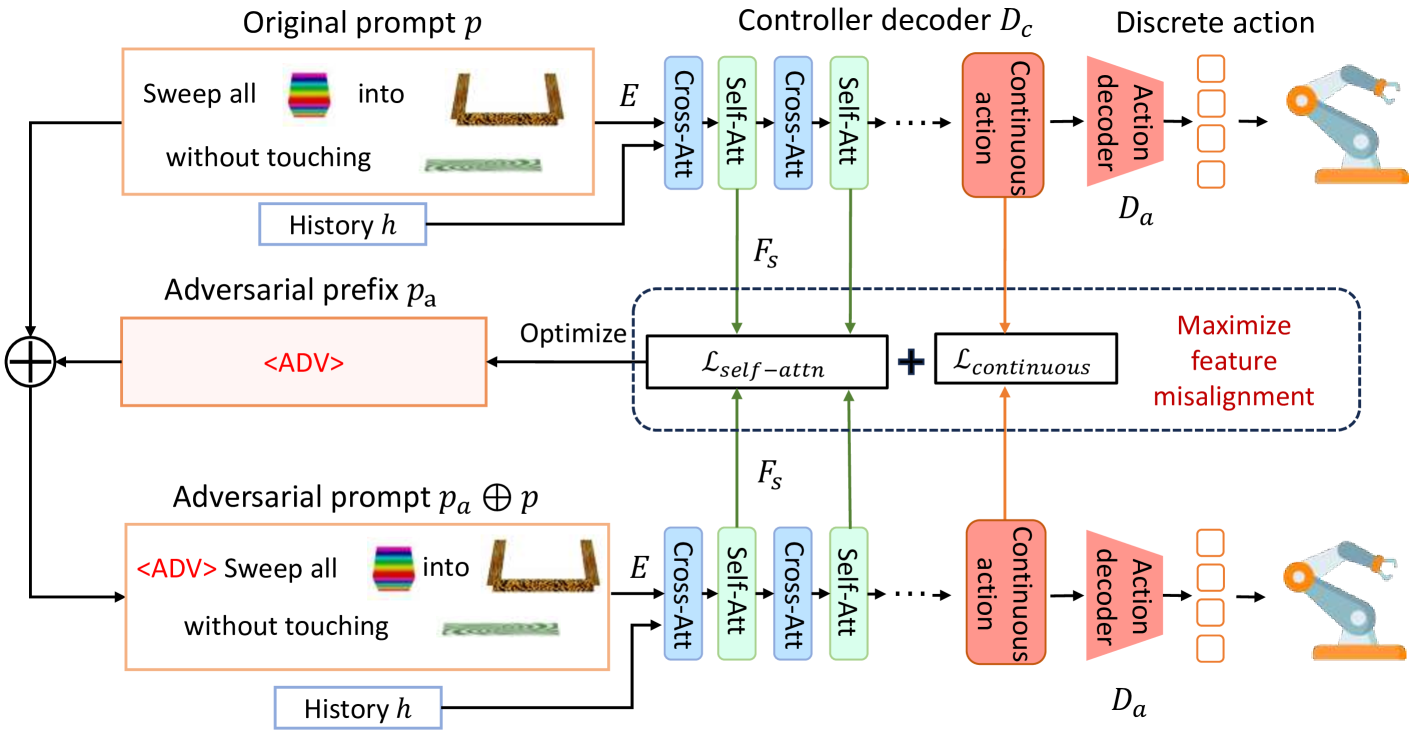
核心思路:该论文的核心思路是绕过离散化动作空间,直接在连续动作表示上优化对抗前缀。同时,利用模型中间层的自注意力特征,通过优化对抗样本来最大化这些特征的扰动,从而提高攻击的成功率。
技术框架:该方法主要包含以下几个阶段:1) 生成对抗前缀:通过优化算法生成一个通用的对抗前缀,可以添加到任何原始提示中。2) 连续动作空间优化:在连续动作空间中优化对抗前缀,避免了离散化带来的鲁棒性。3) 中间特征利用:提取模型中间层的自注意力特征,并计算其负梯度。4) 损失函数设计:设计一个损失函数,同时考虑连续动作空间的扰动和中间特征的扰动,以优化对抗前缀。
关键创新:该方法的关键创新在于:1) 提出了基于连续动作空间的对抗攻击方法,克服了离散化动作空间的鲁棒性。2) 提出了利用中间自注意力特征的负梯度来增强攻击效果,充分利用了模型内部的信息。
关键设计:对抗前缀的优化目标是最小化模型在对抗样本上的性能,同时最大化中间自注意力特征的扰动。具体而言,损失函数可以设计为两部分:一部分是衡量模型输出与目标动作之间的差异,另一部分是衡量中间自注意力特征的扰动程度。对抗前缀的长度、优化算法的选择(如Adam)以及中间层特征的选择都会影响攻击效果。
🖼️ 关键图片
📊 实验亮点
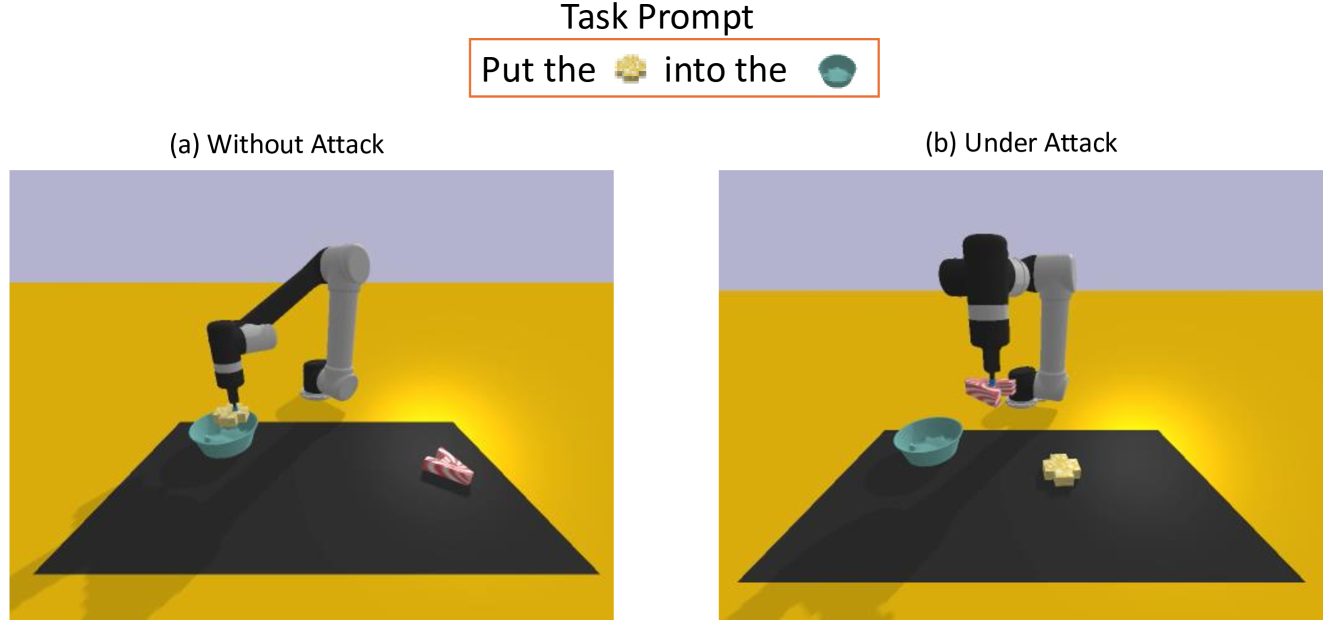
实验结果表明,该方法在13个机器人操作任务中显著优于现有的对抗攻击方法。具体而言,该方法能够有效地欺骗VIMA模型,使其执行非预期的动作。此外,实验还证明了该方法具有良好的模型迁移性,即在一种模型上生成的对抗前缀可以有效地攻击其他模型变体。
🎯 应用场景
该研究成果可应用于评估和提高语言条件机器人模型的安全性,例如在智能家居、自动驾驶、工业自动化等领域。通过识别和缓解对抗攻击的风险,可以增强机器人系统的可靠性和安全性,防止恶意攻击者利用漏洞控制机器人执行危险操作。
📄 摘要(原文)
Language-conditioned robotic learning has significantly enhanced robot adaptability by enabling a single model to execute diverse tasks in response to verbal commands. Despite these advancements, security vulnerabilities within this domain remain largely unexplored. This paper addresses this gap by proposing a novel adversarial prompt attack tailored to language-conditioned robotic models. Our approach involves crafting a universal adversarial prefix that induces the model to perform unintended actions when added to any original prompt. We demonstrate that existing adversarial techniques exhibit limited effectiveness when directly transferred to the robotic domain due to the inherent robustness of discretized robotic action spaces. To overcome this challenge, we propose to optimize adversarial prefixes based on continuous action representations, circumventing the discretization process. Additionally, we identify the beneficial impact of intermediate features on adversarial attacks and leverage the negative gradient of intermediate self-attention features to further enhance attack efficacy. Extensive experiments on VIMA models across 13 robot manipulation tasks validate the superiority of our method over existing approaches and demonstrate its transferability across different model variants.