CodeSAM: Source Code Representation Learning by Infusing Self-Attention with Multi-Code-View Graphs
作者: Alex Mathai, Kranthi Sedamaki, Debeshee Das, Noble Saji Mathews, Srikanth Tamilselvam, Sridhar Chimalakonda, Atul Kumar
分类: cs.SE, cs.LG
发布日期: 2024-11-21
💡 一句话要点
CodeSAM:通过多代码视图图增强自注意力机制,提升源代码表示学习能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 源代码表示学习 自注意力机制 代码视图 抽象语法树 数据流图 控制流图 Transformer模型 软件工程
📋 核心要点
- 现有方法难以有效融合源代码的结构化信息(如AST、DFG、CFG)到Transformer模型中,限制了代码表示学习的性能。
- CodeSAM通过创建自注意力掩码,将多个代码视图灵活地注入到Transformer模型中,从而增强模型对代码结构和语义的理解。
- 实验表明,CodeSAM在语义代码搜索、代码克隆检测和程序分类等任务上,优于GraphCodeBERT和CodeBERT等基线模型。
📝 摘要(中文)
软件工程(SE)中的机器学习(ML)因其显著增强各种SE应用性能的能力而日益重要。这一进展主要归功于通用源代码表示的发展,这些表示有效地捕捉了代码的句法和语义特征。近年来,受自然语言处理(NLP)启发的预训练Transformer模型在SE任务中表现出色。然而,源代码包含嵌入在其语法中的结构和语义属性,这些属性可以从结构化的代码视图中提取,如抽象语法树(AST)、数据流图(DFG)和控制流图(CFG)。这些代码视图可以补充NLP技术,进一步改进SE任务。不幸的是,目前缺乏灵活的框架来有效地将任意代码视图注入到现有的Transformer模型中。因此,本文提出了CodeSAM,一种新颖的可扩展框架,通过创建自注意力掩码将多个代码视图注入到Transformer模型中。我们使用CodeSAM在语义代码搜索、代码克隆检测和程序分类等下游SE任务上微调小型语言模型(SLM),如CodeBERT。实验结果表明,与GraphCodeBERT和CodeBERT等SLM相比,通过使用该技术,在微调期间利用单个代码视图或代码视图的组合,我们提高了所有三个任务的下游性能。我们认为这些结果表明,像CodeSAM这样的技术可以帮助创建紧凑但高性能的代码SLM,适用于资源受限的环境。
🔬 方法详解
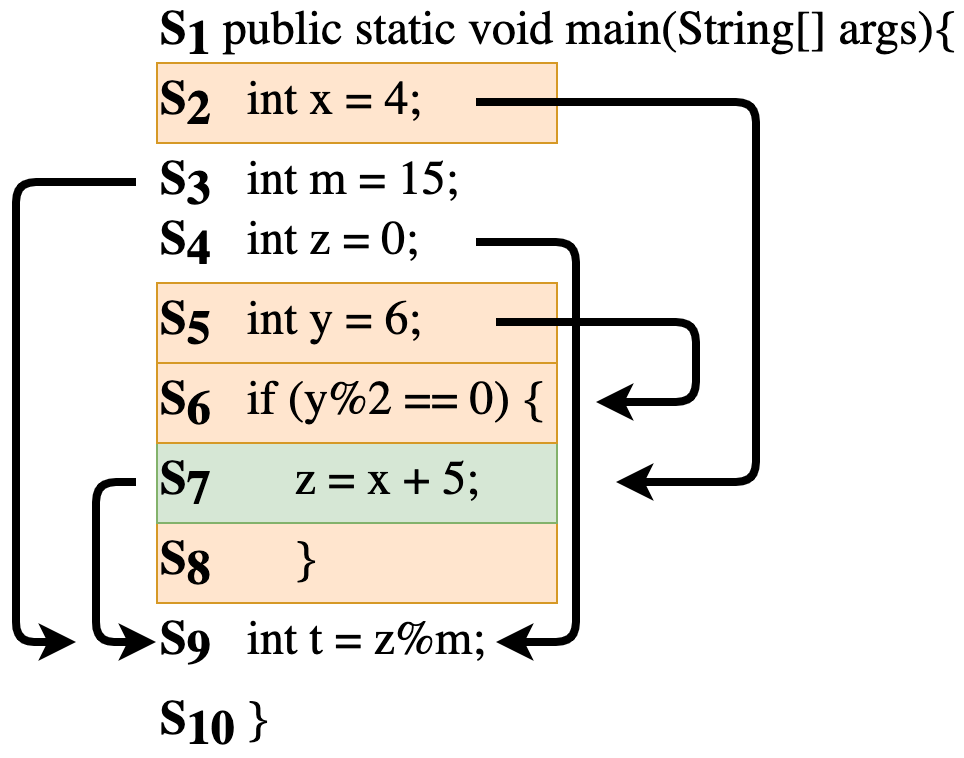
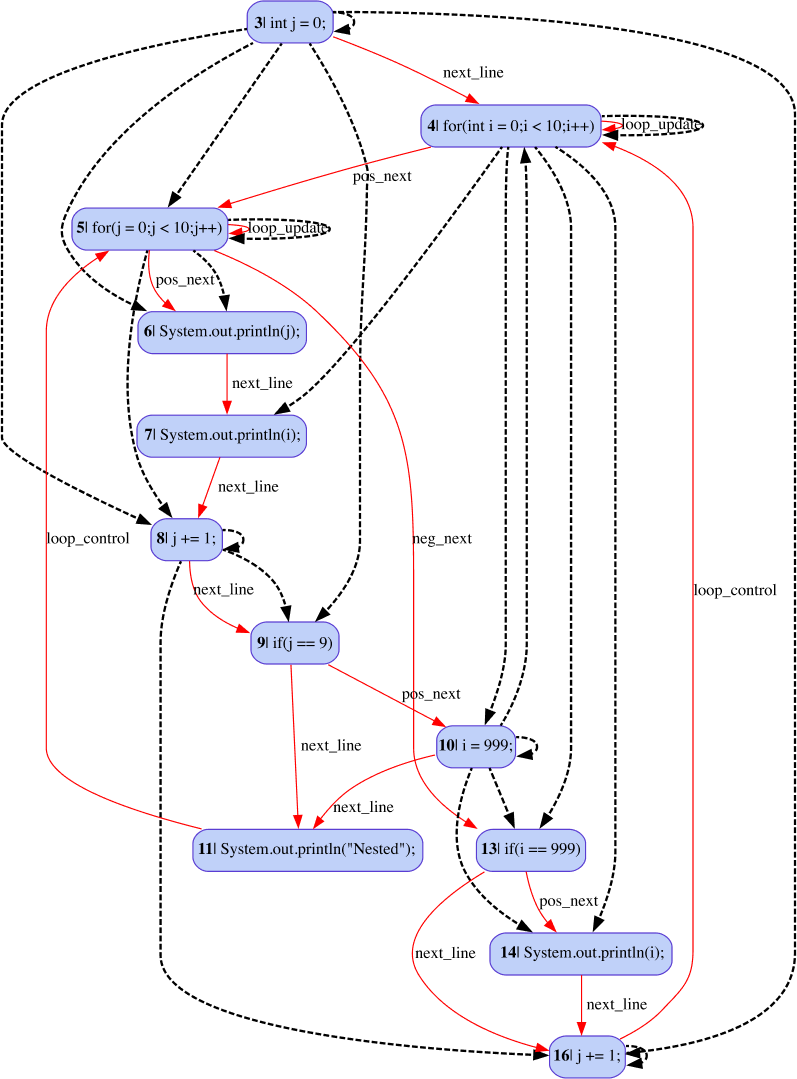
问题定义:论文旨在解决如何将源代码的多种结构化视图(如AST、DFG、CFG)有效融入到基于Transformer的预训练模型中,以提升代码表示学习的性能。现有方法要么难以灵活地融合多种代码视图,要么无法充分利用这些视图中蕴含的结构化信息,导致模型在下游任务中的表现受限。
核心思路:论文的核心思路是利用自注意力机制的灵活性,通过构建自注意力掩码,将不同代码视图的信息注入到Transformer模型中。这种方法允许模型在学习代码表示时,同时考虑代码的文本信息和结构化信息,从而更全面地理解代码的语义。
技术框架:CodeSAM框架主要包含以下几个阶段:1) 从源代码中提取不同的代码视图(AST、DFG、CFG等);2) 根据每个代码视图构建相应的自注意力掩码,这些掩码指示了代码元素之间的依赖关系;3) 将构建的自注意力掩码注入到Transformer模型的自注意力层中,指导模型学习代码表示;4) 在下游任务上微调模型,评估其性能。
关键创新:CodeSAM的关键创新在于提出了一种通用的、可扩展的框架,能够将任意代码视图的信息融入到Transformer模型中。与以往的方法相比,CodeSAM更加灵活,可以根据不同的任务和代码特点选择合适的代码视图,并将其有效地整合到模型中。此外,CodeSAM通过自注意力掩码的方式注入代码视图信息,避免了对模型结构的过度修改,保持了模型的通用性。
关键设计:CodeSAM的关键设计包括:1) 自注意力掩码的构建方式,如何根据不同的代码视图定义代码元素之间的依赖关系;2) 如何将自注意力掩码有效地注入到Transformer模型的自注意力层中,例如,可以通过修改注意力权重的方式实现;3) 在下游任务上微调模型时,需要选择合适的损失函数和优化器,以充分利用代码视图的信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CodeSAM在语义代码搜索、代码克隆检测和程序分类等任务上,显著优于GraphCodeBERT和CodeBERT等基线模型。例如,在代码克隆检测任务中,CodeSAM的F1值比CodeBERT提高了2-3个百分点。这些结果表明,CodeSAM能够有效地利用代码的结构化信息,提升代码表示学习的性能。
🎯 应用场景
CodeSAM具有广泛的应用前景,可用于提升软件工程领域的各种任务,如代码搜索、代码克隆检测、程序分类、代码生成、程序修复等。通过更有效地利用代码的结构化信息,CodeSAM可以帮助开发人员更高效地理解、分析和维护代码,从而提高软件开发的效率和质量。
📄 摘要(原文)
Machine Learning (ML) for software engineering (SE) has gained prominence due to its ability to significantly enhance the performance of various SE applications. This progress is largely attributed to the development of generalizable source code representations that effectively capture the syntactic and semantic characteristics of code. In recent years, pre-trained transformer-based models, inspired by natural language processing (NLP), have shown remarkable success in SE tasks. However, source code contains structural and semantic properties embedded within its grammar, which can be extracted from structured code-views like the Abstract Syntax Tree (AST), Data-Flow Graph (DFG), and Control-Flow Graph (CFG). These code-views can complement NLP techniques, further improving SE tasks. Unfortunately, there are no flexible frameworks to infuse arbitrary code-views into existing transformer-based models effectively. Therefore, in this work, we propose CodeSAM, a novel scalable framework to infuse multiple code-views into transformer-based models by creating self-attention masks. We use CodeSAM to fine-tune a small language model (SLM) like CodeBERT on the downstream SE tasks of semantic code search, code clone detection, and program classification. Experimental results show that by using this technique, we improve downstream performance when compared to SLMs like GraphCodeBERT and CodeBERT on all three tasks by utilizing individual code-views or a combination of code-views during fine-tuning. We believe that these results are indicative that techniques like CodeSAM can help create compact yet performant code SLMs that fit in resource constrained settings.