Towards Knowledge Checking in Retrieval-augmented Generation: A Representation Perspective
作者: Shenglai Zeng, Jiankun Zhang, Bingheng Li, Yuping Lin, Tianqi Zheng, Dante Everaert, Hanqing Lu, Hui Liu, Hui Liu, Yue Xing, Monica Xiao Cheng, Jiliang Tang
分类: cs.LG, cs.CL
发布日期: 2024-11-21
💡 一句话要点
提出基于表征的知识检查方法,提升检索增强生成系统的可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 知识检查 大型语言模型 表征学习 知识过滤
📋 核心要点
- RAG系统面临有效整合外部知识的挑战,容易引入误导性信息,降低生成质量。
- 论文提出基于LLM表征的知识检查方法,通过表征分类器过滤噪声知识,提升RAG系统的可靠性。
- 实验结果表明,即使在噪声知识库下,该方法也能显著提升RAG性能,验证了其有效性。
📝 摘要(中文)
检索增强生成(RAG)系统在提升大型语言模型(LLM)性能方面展现了潜力。然而,这些系统在有效整合外部知识与LLM内部知识时面临挑战,常常导致误导性或无用信息的问题。本文旨在对RAG系统中的知识检查进行系统性研究。我们对LLM的表征行为进行了全面分析,并论证了在知识检查中使用表征的重要性。受此启发,我们进一步开发了基于表征的分类器用于知识过滤。实验表明,即使在处理噪声知识库时,我们的方法也能显著提升RAG性能。这项研究为利用LLM表征来增强RAG系统的可靠性和有效性提供了新的见解。
🔬 方法详解
问题定义:RAG系统在检索到的知识中可能包含错误或不相关的信息,导致LLM生成不准确或误导性的内容。现有方法难以有效区分和过滤这些噪声知识,影响了RAG系统的整体性能。因此,需要一种有效的知识检查机制来确保RAG系统使用的知识是可靠的。
核心思路:论文的核心思路是利用LLM的内部表征来判断检索到的知识是否可靠。LLM在处理信息时会形成内部表征,这些表征包含了对信息的理解和判断。通过分析这些表征,可以识别出与LLM已有知识冲突或不一致的信息,从而过滤掉噪声知识。这种方法避免了直接比较知识内容,而是从LLM的认知角度进行判断。
技术框架:该方法主要包含以下几个阶段:1) 使用检索模块从外部知识库中检索相关知识;2) 将检索到的知识输入LLM,获取LLM的内部表征;3) 使用基于表征的分类器对表征进行分类,判断知识是否可靠;4) 将可靠的知识输入LLM进行生成,从而提高生成质量。整体流程旨在利用LLM的表征能力,在生成之前过滤掉潜在的噪声知识。
关键创新:该方法最重要的创新点在于利用LLM的内部表征进行知识检查。与传统的基于文本匹配或规则的方法不同,该方法能够从LLM的认知角度判断知识的可靠性,从而更有效地过滤噪声知识。这种方法充分利用了LLM的语义理解能力,提高了知识检查的准确性和鲁棒性。
关键设计:论文设计了基于表征的分类器,用于判断知识的可靠性。分类器的输入是LLM的内部表征,输出是知识的可靠性概率。分类器可以使用各种机器学习模型,如逻辑回归、支持向量机或神经网络。论文可能还涉及如何选择合适的LLM表征层、如何训练分类器以及如何平衡准确率和召回率等技术细节。具体的损失函数和网络结构等细节需要在论文中进一步查找。
🖼️ 关键图片

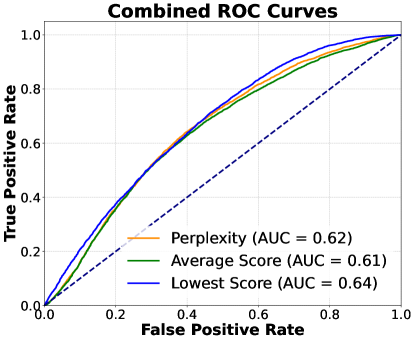
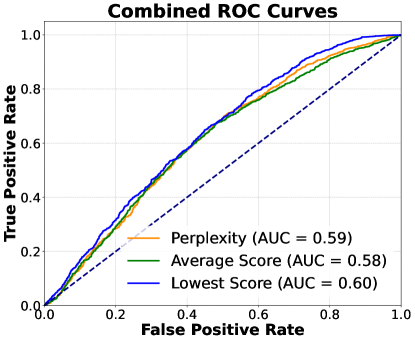
📊 实验亮点
论文通过实验验证了基于表征的知识检查方法的有效性。实验结果表明,即使在噪声知识库下,该方法也能显著提升RAG系统的性能。具体的性能提升幅度需要在论文中查找,例如,可以对比使用该方法和不使用该方法时,RAG系统在准确率、召回率或F1值等指标上的表现。
🎯 应用场景
该研究成果可应用于各种需要利用外部知识的LLM应用场景,如问答系统、对话生成、内容创作等。通过提高RAG系统的可靠性,可以减少LLM生成错误或误导性信息的风险,提升用户体验。未来,该方法可以进一步扩展到处理更复杂的知识类型和更广泛的应用领域。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) systems have shown promise in enhancing the performance of Large Language Models (LLMs). However, these systems face challenges in effectively integrating external knowledge with the LLM's internal knowledge, often leading to issues with misleading or unhelpful information. This work aims to provide a systematic study on knowledge checking in RAG systems. We conduct a comprehensive analysis of LLM representation behaviors and demonstrate the significance of using representations in knowledge checking. Motivated by the findings, we further develop representation-based classifiers for knowledge filtering. We show substantial improvements in RAG performance, even when dealing with noisy knowledge databases. Our study provides new insights into leveraging LLM representations for enhancing the reliability and effectiveness of RAG systems.