From RNNs to Foundation Models: An Empirical Study on Commercial Building Energy Consumption
作者: Shourya Bose, Yijiang Li, Amy Van Sant, Yu Zhang, Kibaek Kim
分类: cs.LG
发布日期: 2024-11-21 (更新: 2024-11-26)
备注: NeurIPS 2024 Workshop on Time Series in the Age of Large Models
💡 一句话要点
研究数据集异构性对商业建筑能耗预测模型性能的影响,并探索了基础模型微调的潜力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 商业建筑能耗预测 时间序列预测 数据集异构性 基础模型微调 深度学习 智能电网 ComStock数据集
📋 核心要点
- 商业建筑能耗预测面临数据异构性挑战,不同建筑类型的数据差异影响模型泛化能力。
- 通过控制数据集大小和区域,改变建筑类型多样性,研究异构性对模型性能的影响。
- 实验表明,数据集异构性和模型架构比参数量更重要,微调基础模型表现出竞争力。
📝 摘要(中文)
精确的商业建筑短期能耗预测对于智能电网运营至关重要。虽然智能电表和深度学习模型能够利用来自多个建筑的历史数据进行预测,但来自不同建筑的数据异构性会降低模型性能。本文研究了在数据集大小和模型保持不变的情况下,时间序列预测中增加数据集异构性的影响。我们使用ComStock数据集,该数据集提供了美国商业建筑的合成能耗数据。通过两个大小和区域相同但建筑类型多样性不同的子集,评估了各种时间序列预测模型的性能,包括微调的开源基础模型(FMs)。结果表明,数据集异构性和模型架构对训练后的预测性能的影响大于参数数量。此外,尽管计算成本较高,但微调的基础模型表现出与从头开始训练的基础模型相比具有竞争力的性能。
🔬 方法详解
问题定义:论文旨在解决商业建筑能耗预测中,由于不同建筑类型数据差异导致的模型性能下降问题。现有方法通常忽略数据集异构性带来的影响,导致模型在实际应用中泛化能力不足。
核心思路:论文的核心思路是通过控制数据集的大小和区域,改变建筑类型多样性,从而量化数据集异构性对模型性能的影响。同时,探索微调预训练基础模型在解决该问题上的潜力。
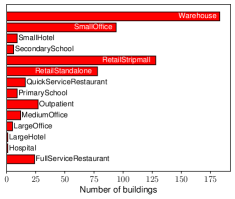
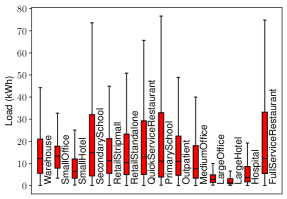
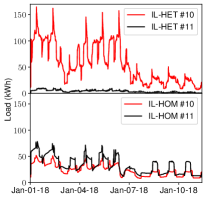
技术框架:论文使用ComStock数据集,构建了两个子集:一个具有较低的建筑类型多样性,另一个具有较高的建筑类型多样性。然后,在这些子集上训练和评估各种时间序列预测模型,包括RNNs和微调的开源基础模型。评估指标包括预测精度等。
关键创新:论文的关键创新在于量化了数据集异构性对商业建筑能耗预测模型性能的影响,并验证了微调预训练基础模型在处理异构数据方面的有效性。这为未来开发更鲁棒的能耗预测模型提供了新的思路。
关键设计:论文的关键设计包括:1) 精心设计的实验方案,控制数据集大小和区域,只改变建筑类型多样性;2) 选择了多种时间序列预测模型,包括RNNs和微调的开源基础模型;3) 使用了合适的评估指标来衡量模型性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,数据集异构性对模型性能的影响显著,高异构性数据集会导致模型预测精度下降。同时,微调的开源基础模型在异构数据集上表现出与从头训练的模型相当甚至更好的性能,尽管计算成本较高。这表明基础模型具有一定的泛化能力,可以通过微调适应不同的建筑类型。
🎯 应用场景
该研究成果可应用于智能电网的优化运行、商业建筑的能源管理和节能策略制定。通过更准确的能耗预测,可以提高能源利用效率,降低能源成本,并为可持续发展做出贡献。未来,该方法可以推广到其他领域的时间序列预测问题,例如交通流量预测和金融市场预测。
📄 摘要(原文)
Accurate short-term energy consumption forecasting for commercial buildings is crucial for smart grid operations. While smart meters and deep learning models enable forecasting using past data from multiple buildings, data heterogeneity from diverse buildings can reduce model performance. The impact of increasing dataset heterogeneity in time series forecasting, while keeping size and model constant, is understudied. We tackle this issue using the ComStock dataset, which provides synthetic energy consumption data for U.S. commercial buildings. Two curated subsets, identical in size and region but differing in building type diversity, are used to assess the performance of various time series forecasting models, including fine-tuned open-source foundation models (FMs). The results show that dataset heterogeneity and model architecture have a greater impact on post-training forecasting performance than the parameter count. Moreover, despite the higher computational cost, fine-tuned FMs demonstrate competitive performance compared to base models trained from scratch.