Learning to Cooperate with Humans using Generative Agents
作者: Yancheng Liang, Daphne Chen, Abhishek Gupta, Simon S. Du, Natasha Jaques
分类: cs.LG, cs.AI, cs.MA
发布日期: 2024-11-21
💡 一句话要点
提出GAMMA,利用生成模型学习人类合作策略,提升人机协作性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人机协作 多智能体强化学习 生成模型 零样本学习 Overcooked 潜在变量模型 后验采样
📋 核心要点
- 现有方法难以模拟真实人类的多样化合作策略,导致训练出的协作智能体与真人配合效果不佳。
- GAMMA通过学习人类伙伴的生成模型,捕捉人类策略的潜在变量表示,从而生成多样化的合作对象。
- 实验表明,GAMMA在Overcooked游戏中与真人协作时,性能得到持续提升,尤其是在少量人类数据辅助下。
📝 摘要(中文)
多智能体强化学习(MARL)的关键任务是训练能够与人类进行零样本协作的智能体。现有算法侧重于训练模拟的人类伙伴策略,然后用这些策略来训练协作智能体。模拟人类通常通过行为克隆人类合作行为数据集或使用MARL创建模拟智能体群体来生成。然而,这些方法难以产生能与真人良好协作的智能体,因为模拟人类无法覆盖真实世界中人类所采用的多样化策略和风格。本文提出学习人类伙伴的生成模型可以有效解决这个问题。该模型学习人类的潜在变量表示,可以被视为编码了人类独特的策略、意图、经验或风格。该生成模型可以灵活地从任何(人类或神经策略)智能体交互数据中进行训练。通过从潜在空间采样,我们可以使用生成模型来生成不同的伙伴来训练协作智能体。我们在Overcooked上评估了我们的方法——用于多智能体适应的生成智能体建模(GAMMA)。我们进行了与真实人类队友的评估,结果表明,无论生成模型是在模拟群体还是人类数据集上训练,GAMMA都能持续提高性能。此外,我们提出了一种从生成模型中进行后验采样的方法,该方法偏向于人类数据,使我们能够仅用少量昂贵的人类交互数据来有效地提高性能。
🔬 方法详解
问题定义:论文旨在解决多智能体强化学习中,智能体与人类进行零样本协作的问题。现有方法主要依赖于模拟人类伙伴,但这些模拟伙伴无法充分捕捉真实人类行为的多样性,导致训练出的协作智能体在与真人交互时表现不佳。现有方法的痛点在于模拟人类策略的泛化能力不足。
核心思路:论文的核心思路是学习一个人类伙伴的生成模型。该模型通过学习人类交互数据的潜在变量表示,捕捉人类策略、意图、经验或风格。通过从该生成模型中采样,可以生成多样化的虚拟人类伙伴,用于训练协作智能体。这种方法旨在提高协作智能体对不同人类行为的适应能力。
技术框架:GAMMA的整体框架包含以下几个主要模块:1) 人类交互数据收集模块:收集人类或其他智能体在协作环境中的交互数据。2) 生成模型训练模块:使用收集到的数据训练人类伙伴的生成模型,该模型学习人类策略的潜在变量表示。3) 协作智能体训练模块:通过与从生成模型中采样的虚拟人类伙伴进行交互,训练协作智能体。4) 后验采样优化模块:利用少量真实人类交互数据,对生成模型进行后验采样优化,使生成的虚拟伙伴更贴近真实人类行为。
关键创新:GAMMA最重要的技术创新点在于使用生成模型来建模人类伙伴。与传统的行为克隆或多智能体训练方法相比,生成模型能够捕捉人类策略的潜在变量表示,从而生成更加多样化和泛化的虚拟人类伙伴。此外,后验采样优化方法能够有效地利用少量真实人类数据,进一步提高协作智能体的性能。
关键设计:生成模型可以使用变分自编码器(VAE)等模型实现,潜在变量的维度需要根据具体任务进行调整。损失函数通常包括重构损失和KL散度损失,用于保证生成模型的生成质量和潜在空间的平滑性。后验采样可以采用重要性采样等方法,根据真实人类数据的相似度对采样结果进行加权。
🖼️ 关键图片

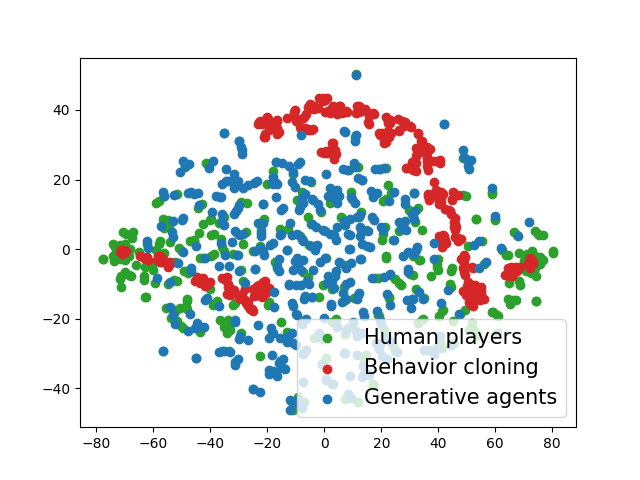
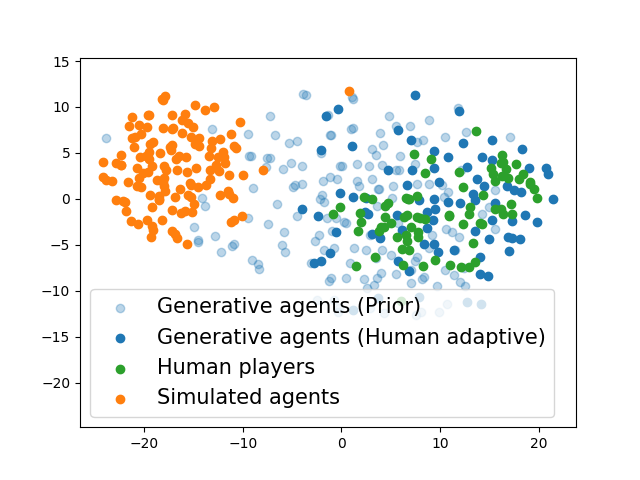
📊 实验亮点
实验结果表明,GAMMA在Overcooked游戏中与真人协作时,性能得到显著提升。与基线方法相比,GAMMA能够更好地适应不同人类队友的策略,从而实现更高的协作效率。特别是在少量人类数据辅助下,通过后验采样优化,GAMMA能够快速提高性能,证明了其在实际应用中的潜力。
🎯 应用场景
该研究成果可应用于人机协作机器人、智能助手、自动驾驶等领域。通过学习人类行为模式,智能体能够更好地理解人类意图,从而实现更高效、更自然的协作。例如,在医疗领域,协作机器人可以辅助医生进行手术;在工业领域,机器人可以与工人协同完成装配任务。
📄 摘要(原文)
Training agents that can coordinate zero-shot with humans is a key mission in multi-agent reinforcement learning (MARL). Current algorithms focus on training simulated human partner policies which are then used to train a Cooperator agent. The simulated human is produced either through behavior cloning over a dataset of human cooperation behavior, or by using MARL to create a population of simulated agents. However, these approaches often struggle to produce a Cooperator that can coordinate well with real humans, since the simulated humans fail to cover the diverse strategies and styles employed by people in the real world. We show \emph{learning a generative model of human partners} can effectively address this issue. Our model learns a latent variable representation of the human that can be regarded as encoding the human's unique strategy, intention, experience, or style. This generative model can be flexibly trained from any (human or neural policy) agent interaction data. By sampling from the latent space, we can use the generative model to produce different partners to train Cooperator agents. We evaluate our method -- \textbf{G}enerative \textbf{A}gent \textbf{M}odeling for \textbf{M}ulti-agent \textbf{A}daptation (GAMMA) -- on Overcooked, a challenging cooperative cooking game that has become a standard benchmark for zero-shot coordination. We conduct an evaluation with real human teammates, and the results show that GAMMA consistently improves performance, whether the generative model is trained on simulated populations or human datasets. Further, we propose a method for posterior sampling from the generative model that is biased towards the human data, enabling us to efficiently improve performance with only a small amount of expensive human interaction data.