AutoMixQ: Self-Adjusting Quantization for High Performance Memory-Efficient Fine-Tuning
作者: Changhai Zhou, Shiyang Zhang, Yuhua Zhou, Zekai Liu, Shichao Weng
分类: cs.LG, cs.AI
发布日期: 2024-11-21
💡 一句话要点
AutoMixQ:一种自适应量化框架,用于高性能、内存高效的大模型微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 量化 剪枝 低秩适应 模型压缩 资源受限 自适应量化
📋 核心要点
- 现有方法在组合剪枝和量化时,由于层间关系复杂,采用统一量化策略导致性能下降。
- AutoMixQ提出一种端到端优化框架,为每个模型层自适应选择最佳量化配置,平衡内存和性能。
- 实验表明,AutoMixQ在降低内存消耗的同时,显著提升了模型性能,优于LoRA和LoftQ等方法。
📝 摘要(中文)
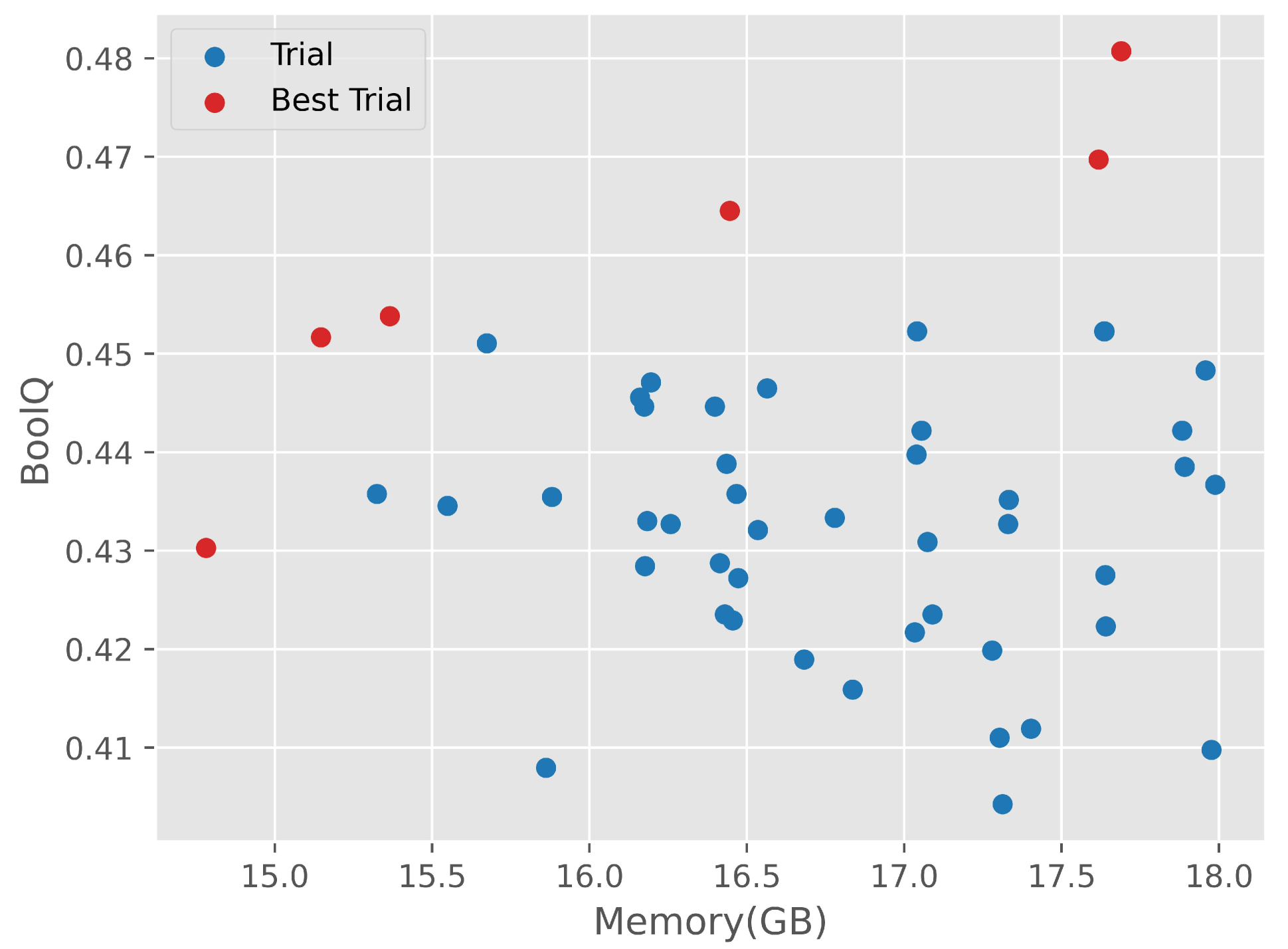
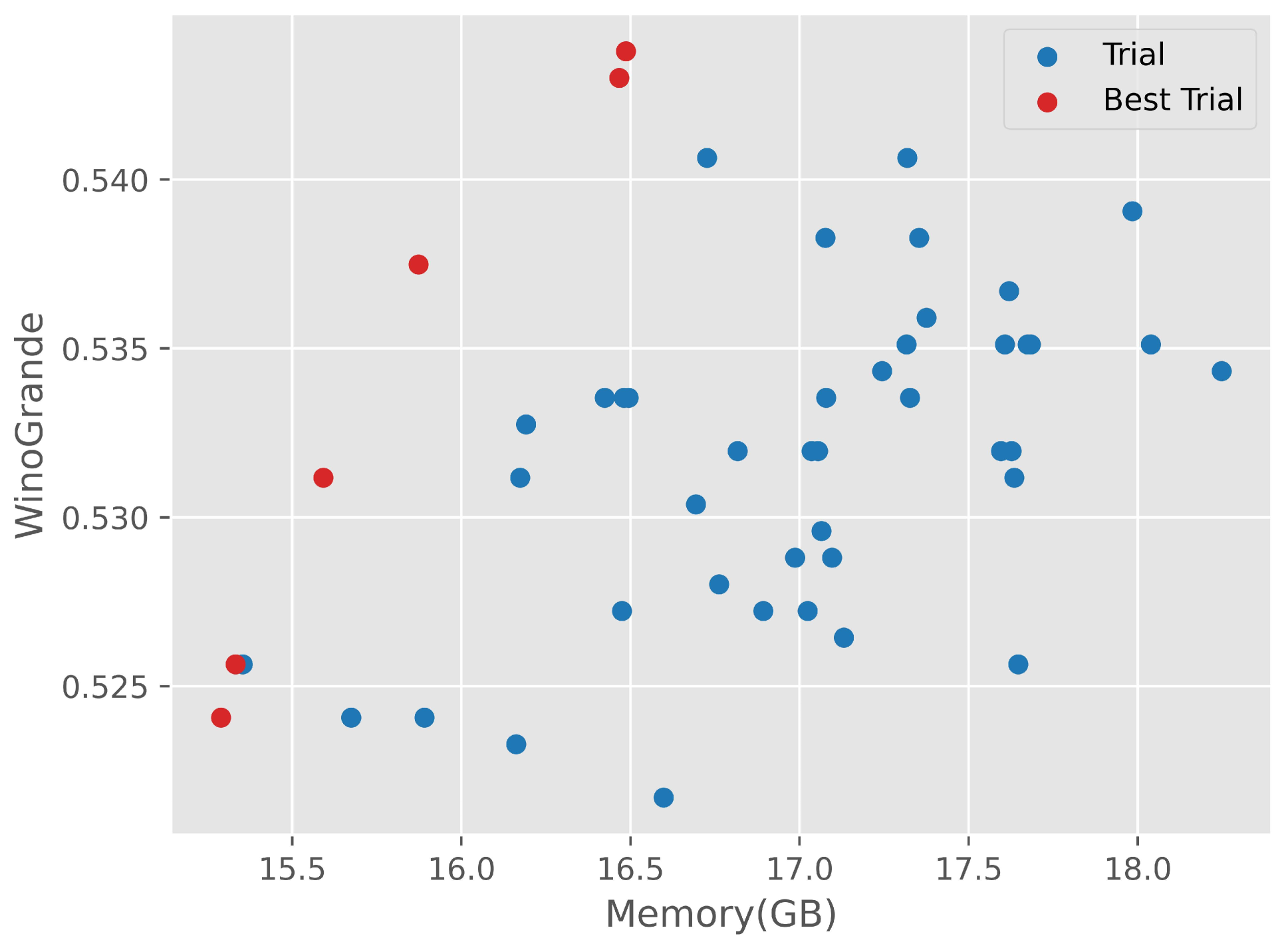
在大模型(LLM)微调中,资源约束是一个重要的挑战。低秩适应(LoRA)、剪枝和量化都是提高资源效率的有效方法。然而,直接组合这些方法通常会导致次优性能,尤其是在所有模型层上采用统一量化时。这是由于剪枝引入了复杂的、不均匀的层间关系,需要更精细的量化策略。为了解决这个问题,我们提出了AutoMixQ,一个端到端优化框架,可以为每个LLM层选择最佳量化配置。AutoMixQ利用轻量级的性能模型来指导选择过程,与穷举搜索方法相比,显著减少了时间和计算资源。通过结合帕累托最优性,AutoMixQ平衡了内存使用和性能,在严格的资源约束下接近模型能力的上限。在广泛使用的基准测试中,我们的实验表明AutoMixQ降低了内存消耗,同时实现了卓越的性能。例如,在LLaMA-7B中,30%的剪枝率下,AutoMixQ在BoolQ上达到了66.21%,而LoRA为62.45%,LoftQ为58.96%,同时与LoRA相比,内存消耗降低了35.5%,与LoftQ相比降低了27.5%。
🔬 方法详解
问题定义:论文旨在解决大语言模型微调过程中,在资源受限情况下,如何有效地结合剪枝和量化技术,避免因简单地应用统一量化策略而导致性能下降的问题。现有方法如LoRA和LoftQ在结合剪枝时,未充分考虑剪枝引入的层间依赖关系,导致量化效果不佳。
核心思路:AutoMixQ的核心思路是为大语言模型的每一层自适应地选择最佳量化配置,而不是采用全局统一的量化方案。通过这种方式,可以更好地适应剪枝后模型各层之间的复杂依赖关系,从而在保证模型性能的同时,降低内存占用。
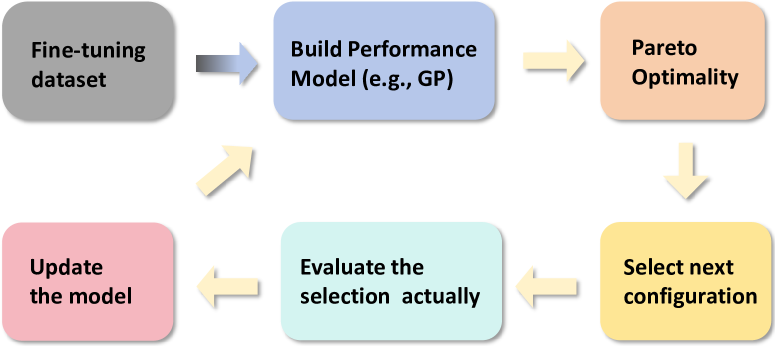
技术框架:AutoMixQ是一个端到端的优化框架,主要包含以下几个阶段:1) 性能模型构建:构建轻量级的性能模型,用于预测不同量化配置下的模型性能。2) 量化配置搜索:利用性能模型指导量化配置的搜索过程,避免了昂贵的穷举搜索。3) 帕累托最优选择:通过帕累托最优性,在内存占用和模型性能之间进行权衡,选择最佳的量化配置组合。4) 模型微调:使用选择的量化配置对模型进行微调,以进一步提升模型性能。
关键创新:AutoMixQ的关键创新在于其自适应的量化配置选择机制,以及利用轻量级性能模型指导搜索过程。与现有方法相比,AutoMixQ能够更好地适应剪枝后模型的层间依赖关系,从而在保证模型性能的同时,显著降低内存占用。此外,AutoMixQ采用端到端的优化方式,避免了手动调整量化配置的繁琐过程。
关键设计:AutoMixQ的关键设计包括:1) 轻量级性能模型:采用参数量较小的神经网络作为性能模型,以降低计算成本。2) 帕累托最优性:使用帕累托最优性来平衡内存占用和模型性能,允许用户根据实际需求选择不同的配置。3) 搜索算法:采用高效的搜索算法,如遗传算法或贝叶斯优化,来搜索最佳的量化配置组合。4) 量化粒度:支持不同的量化粒度,如按层量化或按块量化,以适应不同的模型结构和资源约束。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AutoMixQ在LLaMA-7B模型上,30%剪枝率下,在BoolQ数据集上达到了66.21%的准确率,相比LoRA(62.45%)和LoftQ(58.96%)有显著提升。同时,AutoMixQ相比LoRA降低了35.5%的内存消耗,相比LoftQ降低了27.5%的内存消耗。这些结果表明AutoMixQ在降低内存消耗的同时,能够有效提升模型性能。
🎯 应用场景
AutoMixQ适用于资源受限场景下的大语言模型微调,例如移动设备、边缘计算设备等。该技术可以帮助开发者在有限的计算资源下,高效地微调大模型,从而实现更广泛的应用,例如智能助手、机器翻译、文本生成等。未来,AutoMixQ可以扩展到其他模型压缩技术,如知识蒸馏和结构化剪枝,以进一步提升资源效率。
📄 摘要(原文)
Fine-tuning large language models (LLMs) under resource constraints is a significant challenge in deep learning. Low-Rank Adaptation (LoRA), pruning, and quantization are all effective methods for improving resource efficiency. However, combining them directly often results in suboptimal performance, especially with uniform quantization across all model layers. This is due to the complex, uneven interlayer relationships introduced by pruning, necessitating more refined quantization strategies. To address this, we propose AutoMixQ, an end-to-end optimization framework that selects optimal quantization configurations for each LLM layer. AutoMixQ leverages lightweight performance models to guide the selection process, significantly reducing time and computational resources compared to exhaustive search methods. By incorporating Pareto optimality, AutoMixQ balances memory usage and performance, approaching the upper bounds of model capability under strict resource constraints. Our experiments on widely used benchmarks show that AutoMixQ reduces memory consumption while achieving superior performance. For example, at a 30\% pruning rate in LLaMA-7B, AutoMixQ achieved 66.21\% on BoolQ compared to 62.45\% for LoRA and 58.96\% for LoftQ, while reducing memory consumption by 35.5\% compared to LoRA and 27.5\% compared to LoftQ.