Quantized symbolic time series approximation
作者: Erin Carson, Xinye Chen, Cheng Kang
分类: cs.LG, eess.SP, stat.ML
发布日期: 2024-11-20 (更新: 2025-04-09)
💡 一句话要点
提出QABBA:一种量化的符号时间序列近似方法,提升存储效率并保持精度,应用于时间序列回归。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列分析 符号近似 量化 ABBA 大型语言模型 时间序列回归 存储效率
📋 核心要点
- 现有符号时间序列近似方法在存储效率方面仍有提升空间,尤其是在高性能低比特硬件普及的背景下。
- QABBA通过量化ABBA的符号表示,在保证速度和精度的前提下,显著降低了存储需求,提升了效率。
- 实验表明,QABBA在时间序列回归任务中,结合大型语言模型,取得了新的state-of-the-art结果,并验证了其通用性。
📝 摘要(中文)
时间序列在众多科学和工程领域中普遍存在。符号时间序列表示因其存储效率和降维能力,已被验证在各种工程应用中的有效性。最新的符号聚合近似技术ABBA已被证明可以保留时间序列的基本形状信息,并改善下游应用,例如神经网络在时间序列预测和异常检测方面的推理。受高性能硬件的兴起推动,该硬件能够为低比特宽度表示进行高效计算,我们提出了一种新的基于量化的ABBA符号近似技术QABBA,它在保持原始符号重建速度和准确性的同时,提高了存储效率。我们证明了量化产生的误差的上限,并讨论了如何选择比特数以平衡这种误差与其他误差。此外,还介绍了QABBA与大型语言模型(LLM)在时间序列回归中的应用,并研究了其效用。通过表示时间序列上的符号链模式,QABBA不仅避免了从头开始训练嵌入,而且在Monash回归数据集上实现了新的最先进水平。时间序列的符号近似为在包含各种应用领域的时间序列回归任务上微调LLM提供了一种更有效的方法。我们进一步展示了一组在各种已建立的数据集上进行的广泛实验,以证明QABBA方法在符号近似方面的优势。
🔬 方法详解
问题定义:论文旨在解决时间序列符号近似的存储效率问题。现有的ABBA方法虽然在精度和速度上表现良好,但其符号表示仍然占用一定的存储空间,尤其是在处理大规模时间序列数据时,存储成本不可忽视。
核心思路:论文的核心思路是对ABBA生成的符号表示进行量化,即使用更少的比特数来表示每个符号。通过量化,可以显著降低存储空间,同时尽量保持原始符号表示所蕴含的时间序列形状信息。
技术框架:QABBA方法基于ABBA算法,首先使用ABBA将时间序列转换为符号序列。然后,对符号序列中的每个符号进行量化,将其映射到更低比特宽度的表示。最后,可以使用量化后的符号序列进行后续的时间序列分析任务,例如时间序列回归。
关键创新:QABBA的关键创新在于引入了量化技术来压缩ABBA的符号表示,从而在存储效率和精度之间取得平衡。论文还提供了量化误差的理论上限,并讨论了如何选择合适的比特数以最小化量化误差。
关键设计:论文的关键设计包括:1) 量化方案的选择,需要考虑量化误差和计算复杂度;2) 比特数的选择,需要在存储效率和精度之间进行权衡;3) 与大型语言模型结合,探索QABBA在时间序列回归任务中的应用。论文还针对Monash回归数据集进行了实验,并取得了state-of-the-art的结果。
🖼️ 关键图片
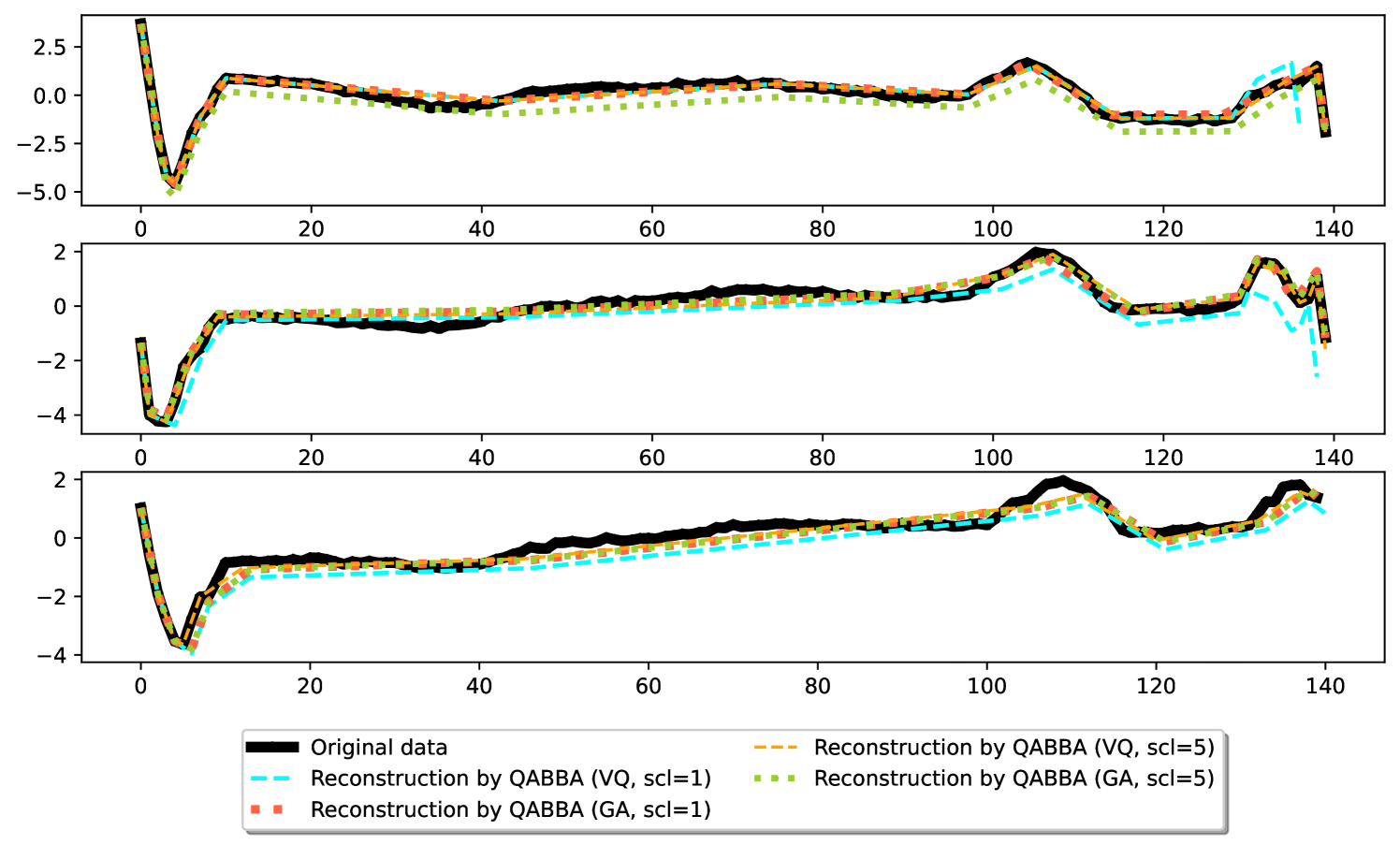
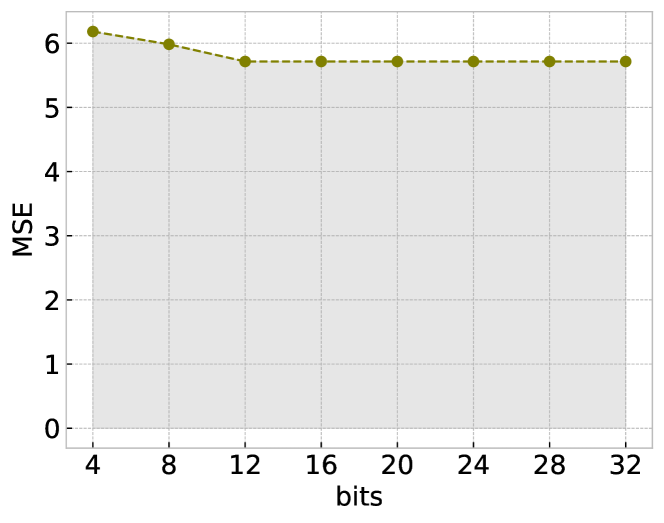
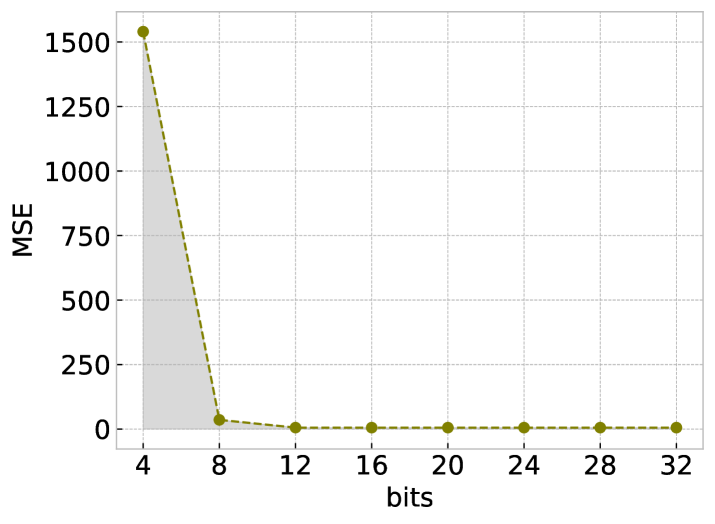
📊 实验亮点
QABBA在Monash回归数据集上实现了新的state-of-the-art结果,证明了其在时间序列回归任务中的有效性。实验结果表明,QABBA在降低存储成本的同时,能够保持较高的精度。此外,论文还提供了量化误差的理论上限,为QABBA的应用提供了理论指导。
🎯 应用场景
QABBA具有广泛的应用前景,包括但不限于:金融时间序列分析、医疗健康监测、工业设备故障诊断、物联网传感器数据处理等。通过降低存储成本,QABBA使得大规模时间序列数据的实时分析和处理成为可能。此外,QABBA与大型语言模型的结合,为时间序列分析提供了一种新的思路,有望推动时间序列智能的发展。
📄 摘要(原文)
Time series are ubiquitous in numerous science and engineering domains, e.g., signal processing, bioinformatics, and astronomy. Previous work has verified the efficacy of symbolic time series representation in a variety of engineering applications due to its storage efficiency and numerosity reduction. The most recent symbolic aggregate approximation technique, ABBA, has been shown to preserve essential shape information of time series and improve downstream applications, e.g., neural network inference regarding prediction and anomaly detection in time series. Motivated by the emergence of high-performance hardware which enables efficient computation for low bit-width representations, we present a new quantization-based ABBA symbolic approximation technique, QABBA, which exhibits improved storage efficiency while retaining the original speed and accuracy of symbolic reconstruction. We prove an upper bound for the error arising from quantization and discuss how the number of bits should be chosen to balance this with other errors. An application of QABBA with large language models (LLMs) for time series regression is also presented, and its utility is investigated. By representing the symbolic chain of patterns on time series, QABBA not only avoids the training of embedding from scratch, but also achieves a new state-of-the-art on Monash regression dataset. The symbolic approximation to the time series offers a more efficient way to fine-tune LLMs on the time series regression task which contains various application domains. We further present a set of extensive experiments performed across various well-established datasets to demonstrate the advantages of the QABBA method for symbolic approximation.