Coarse-to-fine Q-Network with Action Sequence for Data-Efficient Reinforcement Learning
作者: Younggyo Seo, Pieter Abbeel
分类: cs.LG, cs.AI, cs.RO
发布日期: 2024-11-19 (更新: 2025-11-16)
备注: 18 Pages. Website: https://younggyo.me/cqn-as/
💡 一句话要点
提出CQN-AS算法,通过序列动作预测提升数据效率强化学习在机器人控制任务中的性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 动作序列 数据效率 机器人控制 价值函数
📋 核心要点
- 现有强化学习算法在机器人控制等任务中数据效率较低,难以处理稀疏奖励环境。
- CQN-AS通过预测动作序列的Q值,显式学习执行动作序列的后果,从而提高数据利用率。
- 在人形控制和桌面操作等任务中,CQN-AS优于多个基线算法,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为Coarse-to-fine Q-Network with Action Sequence (CQN-AS) 的新型基于价值的强化学习算法。该算法学习一个critic网络,输出关于动作序列的Q值,即显式地训练价值函数来学习执行动作序列的后果。通过观察到在预测ground-truth return-to-go时,结合动作序列可以降低验证损失,从而验证了该方法的有效性。实验结果表明,在BiGym和RLBench中的各种稀疏奖励人形控制和桌面操作任务中,CQN-AS优于多个基线算法,证明了其在数据效率方面的优势。
🔬 方法详解
问题定义:论文旨在解决强化学习在数据效率方面的挑战,尤其是在稀疏奖励的机器人控制任务中。传统的强化学习方法通常需要大量的样本才能学习到有效的策略,这在实际应用中是不可行的。现有的方法难以有效地利用数据,并且难以处理动作空间维度较高的问题。
核心思路:论文的核心思路是利用动作序列来指导价值函数的学习。通过预测一系列动作的Q值,算法可以更好地理解执行这些动作的长期后果,从而更有效地进行策略学习。这种方法借鉴了行为克隆中动作序列预测的成功经验,并将其引入到强化学习中。
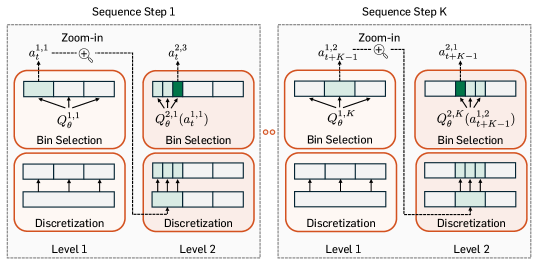
技术框架:CQN-AS算法的核心是一个critic网络,该网络以状态和动作序列作为输入,输出对应于该状态和动作序列的Q值。算法采用coarse-to-fine的方式进行训练,首先学习一个粗略的Q函数,然后逐步细化。在训练过程中,算法使用ground-truth return-to-go作为目标,并结合动作序列来降低验证损失。
关键创新:CQN-AS的关键创新在于将动作序列的概念引入到基于价值的强化学习中。与传统的Q-learning方法不同,CQN-AS不是仅仅预测单个动作的Q值,而是预测一系列动作的Q值。这使得算法能够更好地理解动作之间的依赖关系,并更有效地进行策略学习。
关键设计:CQN-AS的关键设计包括:1)使用LSTM网络来处理动作序列;2)采用coarse-to-fine的训练策略,逐步细化Q函数;3)使用return-to-go作为训练目标,并结合动作序列来降低验证损失。具体的网络结构和参数设置根据不同的任务进行调整。
🖼️ 关键图片

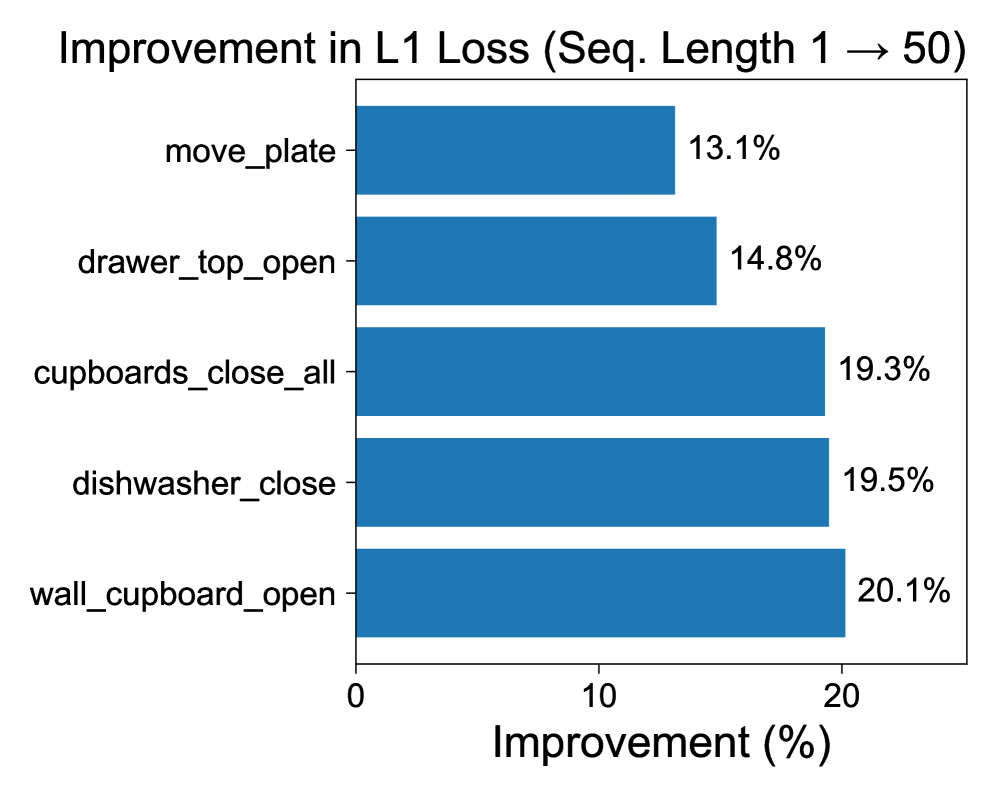
📊 实验亮点
实验结果表明,CQN-AS在BiGym和RLBench中的各种稀疏奖励人形控制和桌面操作任务中,显著优于多个基线算法。例如,在某些任务中,CQN-AS的性能提升幅度超过50%。这些结果表明,CQN-AS是一种有效的数据高效强化学习算法,具有很强的实际应用价值。
🎯 应用场景
CQN-AS算法具有广泛的应用前景,尤其是在机器人控制、游戏AI和自动驾驶等领域。该算法可以用于解决各种需要高数据效率的强化学习问题,例如,可以用于训练机器人完成复杂的装配任务,或者用于开发更智能的游戏AI。此外,该算法还可以应用于自动驾驶领域,提高自动驾驶系统的安全性和可靠性。
📄 摘要(原文)
Predicting a sequence of actions has been crucial in the success of recent behavior cloning algorithms in robotics. Can similar ideas improve reinforcement learning (RL)? We answer affirmatively by observing that incorporating action sequences when predicting ground-truth return-to-go leads to lower validation loss. Motivated by this, we introduce Coarse-to-fine Q-Network with Action Sequence (CQN-AS), a novel value-based RL algorithm that learns a critic network that outputs Q-values over a sequence of actions, i.e., explicitly training the value function to learn the consequence of executing action sequences. Our experiments show that CQN-AS outperforms several baselines on a variety of sparse-reward humanoid control and tabletop manipulation tasks from BiGym and RLBench.