Preserving Expert-Level Privacy in Offline Reinforcement Learning
作者: Navodita Sharma, Vishnu Vinod, Abhradeep Thakurta, Alekh Agarwal, Borja Balle, Christoph Dann, Aravindan Raghuveer
分类: cs.CR, cs.LG
发布日期: 2024-11-18 (更新: 2025-11-23)
备注: Top 10% submission at TMLR (J2C Certification)
💡 一句话要点
提出一种共识专家级差分隐私离线强化学习方法,保护专家隐私。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 差分隐私 专家隐私 共识学习 隐私保护 强化学习
📋 核心要点
- 离线强化学习面临专家隐私泄露风险,现有方法难以在保护专家个体选择信息的同时保证策略性能。
- 论文提出基于共识的专家级差分隐私方法,通过在训练过程中引入噪声,保护每个专家的行为数据。
- 实验表明,该方法在经典RL环境中实现了显著的隐私保护,并在多个任务上优于自然基线。
📝 摘要(中文)
离线强化学习(RL)旨在从一个或多个行为策略(专家)收集的历史数据中学习最优策略,并通过与环境交互来实现。然而,个体专家可能对隐私敏感,因为学习到的策略可能会保留关于他们精确选择的信息。在个性化检索、广告和医疗保健等领域,专家选择被认为是敏感数据。为了可靠地保护这些专家的隐私,我们提出了一种新颖的基于共识的专家级差分隐私离线RL训练方法,该方法与任何现有的离线RL算法兼容。我们证明了严格的差分隐私保证,同时保持了强大的经验性能。与现有的差分隐私RL工作不同,我们用经典RL环境中具有大型连续状态空间的的概念验证实验来补充该理论,展示了在多个任务中相对于自然基线的显著改进。
🔬 方法详解
问题定义:论文旨在解决离线强化学习中专家隐私保护的问题。现有方法在保护专家隐私方面存在不足,学习到的策略可能泄露专家的敏感信息,例如在医疗领域,患者的治疗方案选择。这使得在利用专家数据进行策略学习时面临隐私泄露的风险。
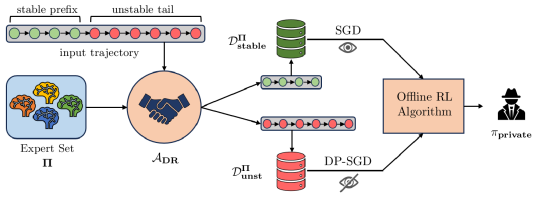
核心思路:论文的核心思路是采用差分隐私(Differential Privacy, DP)机制,在训练过程中对每个专家的贡献进行扰动,从而防止模型记住单个专家的具体行为。通过共识机制,确保扰动后的模型仍然能够学习到有效的策略。
技术框架:整体框架包含以下几个主要阶段:1) 数据收集:从多个专家处收集历史数据。2) 隐私扰动:对每个专家的贡献进行差分隐私扰动。3) 共识学习:利用扰动后的数据进行离线强化学习,学习一个能够达成共识的策略。4) 策略评估:评估学习到的策略的性能和隐私保护程度。
关键创新:该方法的核心创新在于将差分隐私应用于专家级别的离线强化学习,而不是传统的样本级别。这意味着隐私保护的粒度更细,能够更好地保护专家的个体选择。此外,共识机制的设计保证了在隐私保护的同时,策略的性能不会受到太大影响。
关键设计:论文的关键设计包括:1) 差分隐私机制的选择和参数设置,例如隐私预算epsilon和delta。2) 共识机制的具体实现,例如如何聚合来自不同专家的信息。3) 离线强化学习算法的选择,该方法可以与任何现有的离线强化学习算法兼容。4) 损失函数的设计,需要考虑隐私保护和策略性能之间的平衡。
🖼️ 关键图片

📊 实验亮点
论文在经典RL环境中进行了实验,结果表明,该方法在保证差分隐私的前提下,显著优于自然基线。具体而言,在多个任务上,该方法在隐私保护程度和策略性能之间取得了良好的平衡,证明了其有效性和实用性。
🎯 应用场景
该研究成果可应用于个性化推荐、广告投放、医疗决策等领域,在这些领域中,用户或专家的行为数据包含敏感信息。通过该方法,可以在利用这些数据进行策略学习的同时,保护用户的隐私,促进数据共享和合作。
📄 摘要(原文)
The offline reinforcement learning (RL) problem aims to learn an optimal policy from historical data collected by one or more behavioural policies (experts) by interacting with an environment. However, the individual experts may be privacy-sensitive in that the learnt policy may retain information about their precise choices. In some domains like personalized retrieval, advertising and healthcare, the expert choices are considered sensitive data. To provably protect the privacy of such experts, we propose a novel consensus-based expert-level differentially private offline RL training approach compatible with any existing offline RL algorithm. We prove rigorous differential privacy guarantees, while maintaining strong empirical performance. Unlike existing work in differentially private RL, we supplement the theory with proof-of-concept experiments on classic RL environments featuring large continuous state spaces, demonstrating substantial improvements over a natural baseline across multiple tasks.