BitMoD: Bit-serial Mixture-of-Datatype LLM Acceleration
作者: Yuzong Chen, Ahmed F. AbouElhamayed, Xilai Dai, Yang Wang, Marta Andronic, George A. Constantinides, Mohamed S. Abdelfattah
分类: cs.LG, cs.AR
发布日期: 2024-11-18 (更新: 2025-04-26)
备注: HPCA 2025
💡 一句话要点
BitMoD:一种面向低精度LLM加速的混合数据类型位串行算法-硬件协同设计方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 低精度量化 混合数据类型 位串行处理 算法硬件协同设计
📋 核心要点
- 现有LLM部署受限于其巨大的内存占用,低精度量化是降低内存需求的有效方法,但精度损失是关键挑战。
- BitMoD通过细粒度数据类型自适应量化权重,并结合位串行硬件设计,在低精度下保持LLM的性能。
- 实验表明,BitMoD在判别任务和生成任务上均优于现有量化方法,并实现了显著的加速效果。
📝 摘要(中文)
大型语言模型(LLM)在各种机器学习任务中表现出了卓越的性能。然而,LLM庞大的内存占用严重阻碍了它们的部署。本文提出了BitMoD,一种算法-硬件协同设计解决方案,通过低权重精度实现高效的LLM加速,从而提高LLM的可访问性。在算法方面,BitMoD引入了细粒度数据类型自适应,使用不同的数值数据类型来量化一组权重(例如,128个权重)。通过精心设计这些新的数据类型,BitMoD能够将LLM权重量化到非常低的精度(例如,4位和3位),同时保持高精度。在硬件方面,BitMoD采用位串行处理单元,可以轻松支持多种数值精度和数据类型;我们的硬件设计包括两个关键创新:首先,它采用统一的表示来处理不同的权重数据类型,从而降低了硬件成本。其次,它采用位串行反量化单元,以最小的硬件开销重新缩放每组的偏和。在六个代表性LLM上的评估表明,BitMoD显著优于最先进的LLM量化和加速方法。对于判别任务,BitMoD可以将LLM权重量化到4位,平均精度损失小于0.5%。对于生成任务,BitMoD能够将LLM权重量化到3位,同时实现比以前的LLM量化方案更好的困惑度。结合卓越的模型性能和高效的加速器设计,BitMoD相比之前的LLM加速器ANT和OliVe,分别实现了平均1.69倍和1.48倍的加速。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)部署时内存占用过大的问题。现有的低精度量化方法虽然可以降低内存需求,但往往会导致显著的精度损失,影响模型性能。因此,如何在保证模型性能的前提下,进一步降低LLM的权重精度,是本研究要解决的核心问题。
核心思路:BitMoD的核心思路是采用混合数据类型量化(Mixture-of-Datatype)和位串行处理(Bit-Serial Processing)的算法-硬件协同设计。通过对不同的权重组采用不同的数据类型进行量化,可以在保证整体精度的同时,进一步降低平均权重精度。同时,采用位串行硬件设计可以高效地支持多种数据类型,降低硬件开销。
技术框架:BitMoD的技术框架主要包括两个部分:算法侧的混合数据类型量化和硬件侧的位串行加速器。算法侧,首先将权重分组,然后为每个组选择合适的数据类型进行量化。硬件侧,采用位串行处理单元进行计算,并设计了统一的数据表示和位串行反量化单元,以支持不同的数据类型。
关键创新:BitMoD的关键创新在于:1) 细粒度的数据类型自适应量化,允许不同的权重组使用不同的数据类型,从而在精度和存储之间取得更好的平衡;2) 位串行硬件设计,可以高效地支持多种数据类型,降低硬件开销;3) 统一的数据表示和位串行反量化单元,进一步降低了硬件成本。
关键设计:在算法侧,关键在于如何选择每个权重组的数据类型。论文可能采用了一种搜索算法或启发式方法来确定每个组的最佳数据类型。在硬件侧,关键在于位串行处理单元的设计,以及统一数据表示和位串行反量化单元的实现。具体的参数设置、损失函数和网络结构等细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
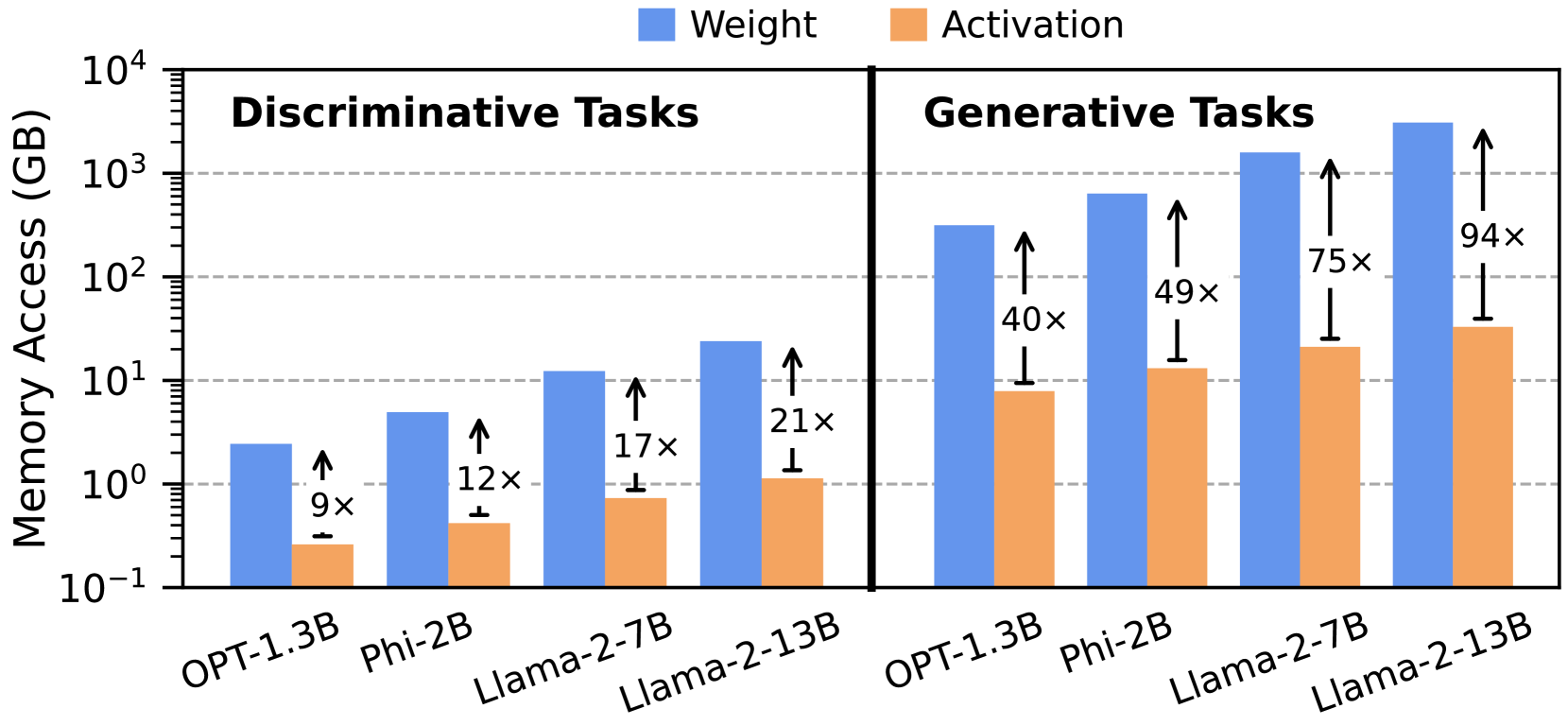
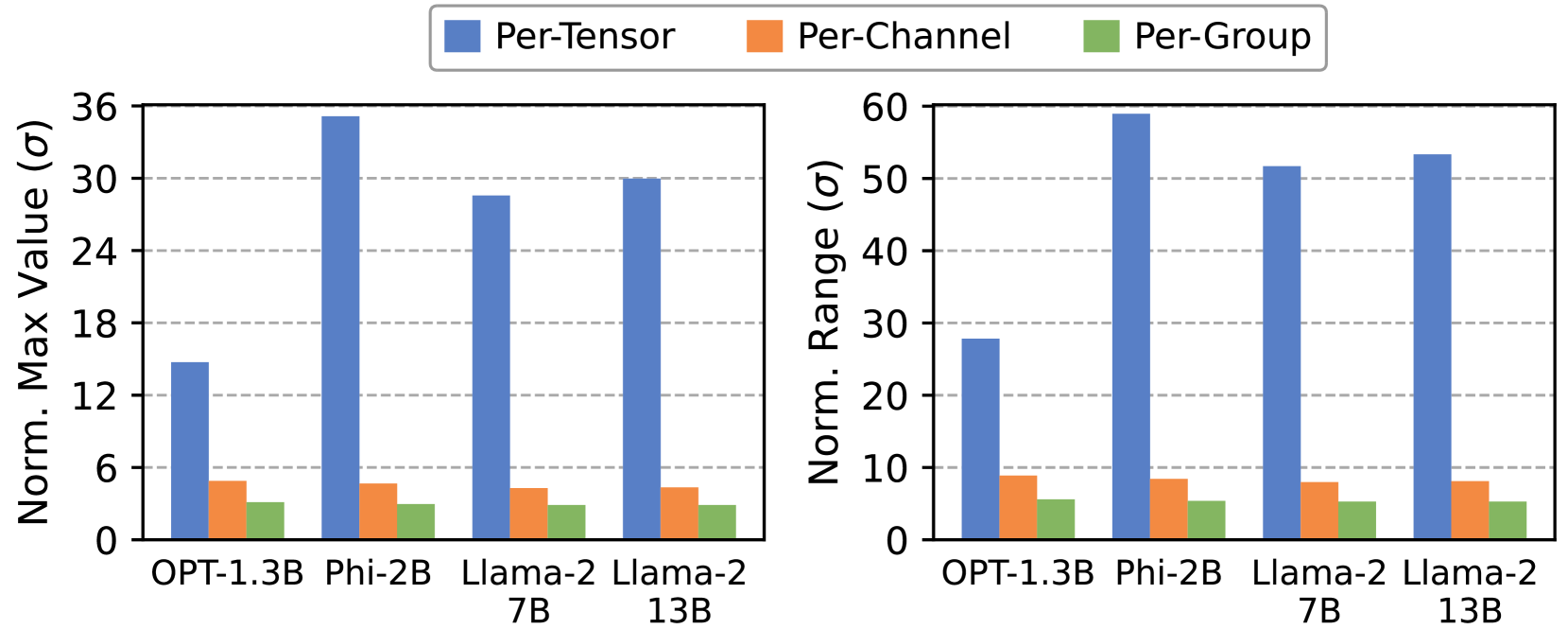
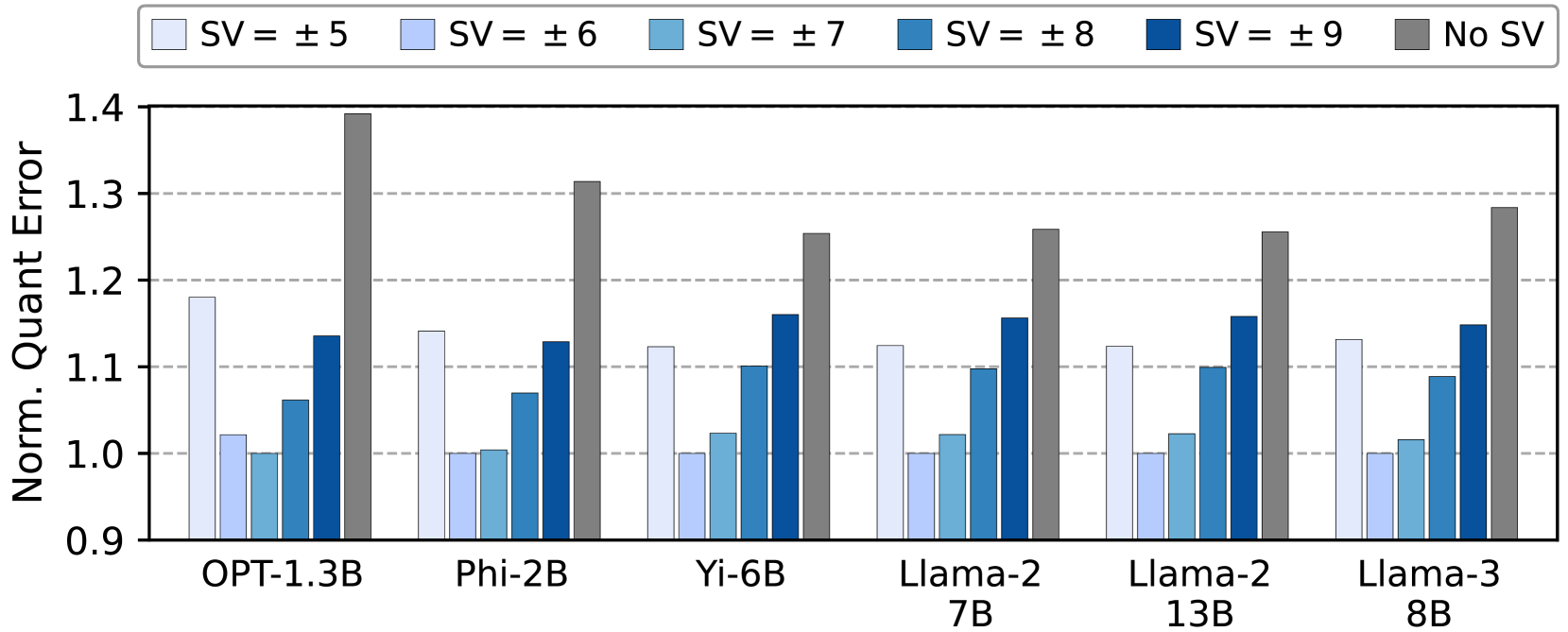
📊 实验亮点
BitMoD在六个代表性LLM上的评估表明,其性能显著优于现有的LLM量化和加速方法。对于判别任务,BitMoD可以将LLM权重量化到4位,平均精度损失小于0.5%。对于生成任务,BitMoD能够将LLM权重量化到3位,同时实现比以前的LLM量化方案更好的困惑度。与之前的LLM加速器ANT和OliVe相比,BitMoD分别实现了平均1.69倍和1.48倍的加速。
🎯 应用场景
BitMoD具有广泛的应用前景,可用于在资源受限的设备上部署大型语言模型,例如移动设备、嵌入式系统和边缘计算设备。该研究可以降低LLM的部署成本,提高其可访问性,并促进LLM在各个领域的应用,例如智能助手、自然语言处理和机器翻译。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable performance across various machine learning tasks. Yet the substantial memory footprint of LLMs significantly hinders their deployment. In this paper, we improve the accessibility of LLMs through BitMoD, an algorithm-hardware co-design solution that enables efficient LLM acceleration at low weight precision. On the algorithm side, BitMoD introduces fine-grained data type adaptation that uses a different numerical data type to quantize a group of (e.g., 128) weights. Through the careful design of these new data types, BitMoD is able to quantize LLM weights to very low precision (e.g., 4 bits and 3 bits) while maintaining high accuracy. On the hardware side, BitMoD employs a bit-serial processing element to easily support multiple numerical precisions and data types; our hardware design includes two key innovations: First, it employs a unified representation to process different weight data types, thus reducing the hardware cost. Second, it adopts a bit-serial dequantization unit to rescale the per-group partial sum with minimal hardware overhead. Our evaluation on six representative LLMs demonstrates that BitMoD significantly outperforms state-of-the-art LLM quantization and acceleration methods. For discriminative tasks, BitMoD can quantize LLM weights to 4-bit with $<!0.5\%$ accuracy loss on average. For generative tasks, BitMoD is able to quantize LLM weights to 3-bit while achieving better perplexity than prior LLM quantization scheme. Combining the superior model performance with an efficient accelerator design, BitMoD achieves an average of $1.69\times$ and $1.48\times$ speedups compared to prior LLM accelerators ANT and OliVe, respectively.