Dissecting Representation Misalignment in Contrastive Learning via Influence Function
作者: Lijie Hu, Chenyang Ren, Huanyi Xie, Khouloud Saadi, Shu Yang, Zhen Tan, Jingfeng Zhang, Di Wang
分类: cs.LG, cs.AI, cs.CV
发布日期: 2024-11-18 (更新: 2025-01-31)
备注: 33 pages
💡 一句话要点
提出ECIF:通过扩展影响函数解决对比学习中表征错位问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对比学习 影响函数 数据估值 多模态模型 表征学习
📋 核心要点
- 大规模对比学习模型易受数据错位影响,导致性能下降,现有数据估值方法计算成本高昂。
- 提出扩展影响函数ECIF,同时考虑正负样本的影响,为对比损失提供闭式近似解。
- 实验表明,ECIF能更准确评估数据影响和模型对齐,提升CLIP风格模型的透明性和可解释性。
📝 摘要(中文)
对比学习常用于大规模多模态模型,但依赖于多样且不可靠的数据源,其中可能包含错位或错误标注的文本-图像对。这会导致鲁棒性问题和幻觉,最终降低性能。数据估值是检测和追踪这些错位的有效方法,但现有方法对于大规模模型计算成本高昂。传统的的影响函数虽然计算效率高,但最初是为点损失设计的,不适用于对比学习模型。此外,对比学习涉及最小化正样本模态之间的距离,同时最大化负样本模态之间的距离,因此需要从两个角度评估样本的影响。为了解决这些挑战,我们引入了对比损失的扩展影响函数(ECIF),它考虑了正样本和负样本,并提供了对比学习模型的闭式近似,无需重新训练。基于ECIF,我们开发了一系列算法,用于数据评估、错位检测和错误预测追溯任务。实验结果表明,与传统基线方法相比,我们的ECIF通过提供更准确的数据影响和模型对齐评估,提高了CLIP风格嵌入模型的透明度和可解释性。
🔬 方法详解
问题定义:对比学习在多模态模型中广泛应用,但训练数据中存在的文本-图像错位问题会导致模型性能下降,产生幻觉。现有数据估值方法,如直接重新训练模型来评估每个样本的影响,计算成本过高,难以应用于大规模模型。传统的影响函数主要针对点损失设计,无法直接应用于对比学习,因为它同时涉及正样本对的距离最小化和负样本对的距离最大化。
核心思路:论文的核心思路是扩展传统的影响函数,使其能够适用于对比学习的损失函数。通过同时考虑正样本和负样本的影响,ECIF能够更准确地评估每个样本对模型训练的贡献。此外,ECIF提供了一种闭式解的近似,避免了重新训练模型的需要,从而显著降低了计算成本。
技术框架:ECIF方法主要包含以下几个阶段:1) 定义对比损失函数;2) 推导ECIF,即对比损失函数对训练样本的二阶导数近似;3) 利用ECIF进行数据评估,包括识别错位数据、追溯错误预测等。整体框架是在现有对比学习模型的基础上,增加一个数据评估模块,该模块利用ECIF来分析训练数据对模型的影响。
关键创新:最重要的技术创新点在于提出了针对对比损失的扩展影响函数ECIF。与传统影响函数相比,ECIF不仅考虑了单个样本的影响,还考虑了正负样本对之间的关系,更全面地反映了数据对模型训练的影响。此外,ECIF提供了一种闭式解的近似,避免了重新训练模型的需要,大大提高了计算效率。
关键设计:ECIF的关键设计在于其对对比损失函数的二阶导数近似。具体而言,论文推导了对比损失函数关于模型参数的一阶和二阶导数,并利用这些导数来近似计算每个训练样本对模型预测的影响。对比损失函数通常采用InfoNCE loss等形式,ECIF的推导过程需要针对具体的损失函数进行。此外,论文还设计了一系列基于ECIF的算法,用于数据评估、错位检测和错误预测追溯等任务。
🖼️ 关键图片
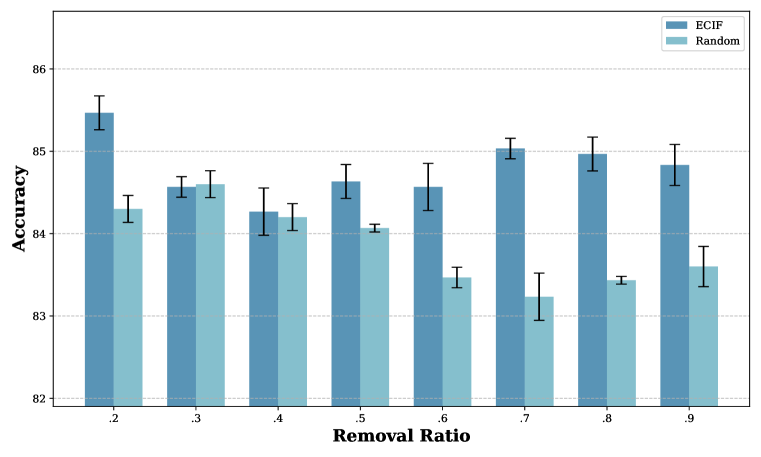
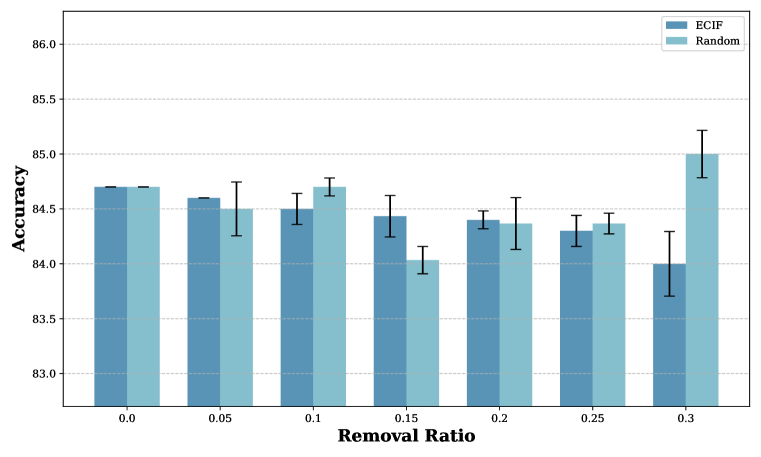

📊 实验亮点
实验结果表明,ECIF在数据评估、错位检测和错误预测追溯等任务上优于传统基线方法。例如,在错位检测任务中,ECIF能够更准确地识别出错误的文本-图像对,从而提高模型的训练效果。具体性能提升数据未知,但论文强调ECIF在数据影响评估和模型对齐方面提供了更准确的评估。
🎯 应用场景
该研究成果可应用于大规模多模态模型的训练和优化,例如CLIP风格的模型。通过识别和纠正训练数据中的错位问题,可以提高模型的鲁棒性和准确性,减少幻觉的产生。此外,ECIF还可以用于模型调试和解释性分析,帮助研究人员理解模型学习到的知识和决策过程。
📄 摘要(原文)
Contrastive learning, commonly applied in large-scale multimodal models, often relies on data from diverse and often unreliable sources, which can include misaligned or mislabeled text-image pairs. This frequently leads to robustness issues and hallucinations, ultimately causing performance degradation. Data valuation is an efficient way to detect and trace these misalignments. Nevertheless, existing methods are computationally expensive for large-scale models. Although computationally efficient, classical influence functions are inadequate for contrastive learning models, as they were initially designed for pointwise loss. Furthermore, contrastive learning involves minimizing the distance between positive sample modalities while maximizing the distance between negative sample modalities. This necessitates evaluating the influence of samples from both perspectives. To tackle these challenges, we introduce the Extended Influence Function for Contrastive Loss (ECIF), an influence function crafted for contrastive loss. ECIF considers both positive and negative samples and provides a closed-form approximation of contrastive learning models, eliminating the need for retraining. Building upon ECIF, we develop a series of algorithms for data evaluation, misalignment detection, and misprediction trace-back tasks. Experimental results demonstrate our ECIF advances the transparency and interpretability of CLIP-style embedding models by offering a more accurate assessment of data impact and model alignment compared to traditional baseline methods.