Re-examining learning linear functions in context
作者: Omar Naim, Guilhem Fouilhé, Nicholas Asher
分类: cs.LG, cs.CL
发布日期: 2024-11-18 (更新: 2025-08-31)
期刊: KI 2025: Advances in Artificial Intelligence
DOI: 10.1007/978-3-032-02813-6_8
💡 一句话要点
研究表明Transformer在上下文学习线性函数时,未采用线性回归等算法方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 大型语言模型 Transformer模型 线性函数 泛化能力
📋 核心要点
- 现有研究对上下文学习(ICL)的理解有限,尤其是在Transformer模型如何学习抽象任务结构方面。
- 该研究通过合成数据和类GPT-2模型,探究Transformer在上下文中学习线性函数的能力,挑战了线性回归的假设。
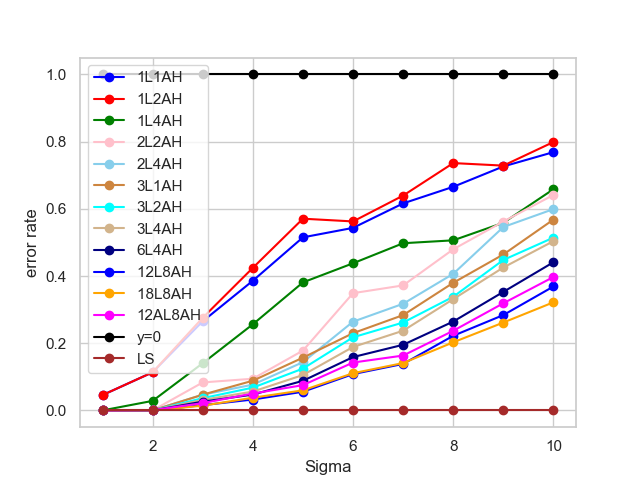
- 实验表明,Transformer模型在学习线性函数时,无法泛化到训练分布之外,揭示了其在抽象推理方面的局限性。
📝 摘要(中文)
上下文学习(ICL)已经成为一种强大的范式,可以轻松地将大型语言模型(LLM)应用于各种任务。然而,我们对ICL工作原理的理解仍然有限。我们通过一个受控的设置和合成训练数据,探索了一个简单的ICL模型,以研究单变量线性函数的ICL。我们使用一系列从头开始训练的类GPT-2 Transformer模型进行实验。我们的发现挑战了当前流行的观点,即Transformer采用线性回归等算法方法来在上下文中学习线性函数。这些模型无法推广到其训练分布之外,突显了它们在推断抽象任务结构方面的根本局限性。我们的实验引导我们提出了一个数学上精确的假设,即模型可能正在学习的内容。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)中的上下文学习(ICL)机制,特别是当任务是学习线性函数时。现有的理解认为,Transformer模型可能采用类似线性回归的算法来解决此类问题。然而,这种理解缺乏充分的实验验证,并且模型泛化能力未知。
核心思路:论文的核心思路是通过构建一个可控的实验环境,使用合成数据训练类GPT-2的Transformer模型,并观察其在上下文中学习线性函数时的行为。通过分析模型的表现,特别是其泛化能力,来验证或推翻现有的关于ICL的假设。
技术框架:该研究的技术框架主要包括以下几个部分:1) 生成合成的训练数据,这些数据包含输入和输出,并且遵循线性函数关系。2) 使用这些数据从头开始训练类GPT-2的Transformer模型。3) 设计实验来测试模型在不同条件下的上下文学习能力,例如,改变输入数据的分布或范围。4) 分析模型的输出,以确定其是否能够正确地学习线性函数,并评估其泛化能力。
关键创新:该研究的关键创新在于其对Transformer模型在ICL中学习线性函数的方式提出了质疑。通过实验,论文发现Transformer模型并没有像预期的那样采用线性回归等算法方法,而是表现出对训练数据分布的强烈依赖,泛化能力较差。这挑战了当前对ICL的普遍认知。
关键设计:在实验设计方面,论文采用了多种策略来控制变量和评估模型的性能。例如,使用了不同大小的Transformer模型,改变了训练数据的数量和分布,以及设计了不同的测试用例来评估模型的泛化能力。此外,论文还尝试提出一个数学上精确的假设来解释模型可能正在学习的内容,尽管具体细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,从头训练的类GPT-2 Transformer模型在上下文中学习线性函数时,无法泛化到训练分布之外。这与普遍认为的Transformer模型采用线性回归等算法的观点相悖。该研究揭示了Transformer模型在学习抽象任务结构方面的局限性。
🎯 应用场景
该研究成果有助于更深入地理解大型语言模型的上下文学习机制,为改进ICL算法、提升模型泛化能力提供理论基础。潜在应用包括开发更高效、更可靠的LLM,以及在数据稀缺或分布变化的场景下更好地利用LLM解决实际问题。
📄 摘要(原文)
In-context learning (ICL) has emerged as a powerful paradigm for easily adapting Large Language Models (LLMs) to various tasks. However, our understanding of how ICL works remains limited. We explore a simple model of ICL in a controlled setup with synthetic training data to investigate ICL of univariate linear functions. We experiment with a range of GPT-2-like transformer models trained from scratch. Our findings challenge the prevailing narrative that transformers adopt algorithmic approaches like linear regression to learn a linear function in-context. These models fail to generalize beyond their training distribution, highlighting fundamental limitations in their capacity to infer abstract task structures. Our experiments lead us to propose a mathematically precise hypothesis of what the model might be learning.