Efficient Alignment of Large Language Models via Data Sampling
作者: Amrit Khera, Rajat Ghosh, Debojyoti Dutta
分类: cs.LG, cs.CL
发布日期: 2024-11-15 (更新: 2025-02-17)
备注: Original work accepted at NeurIPS Efficient Natural Language and Speech Processing Workshop. PMLR, 2024. Experiments with a larger model from a different family, Llama-30B have been added to the appendix for generalizability
💡 一句话要点
提出基于信息论的数据采样方法,高效对齐大语言模型,降低90%成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型对齐 数据采样 信息论 高效对齐 资源优化
📋 核心要点
- 现有LLM对齐方法依赖大量人工标注数据,成本高昂且耗时,限制了其应用。
- 论文提出基于信息论的数据采样方法,选取高质量数据子集进行对齐,降低资源需求。
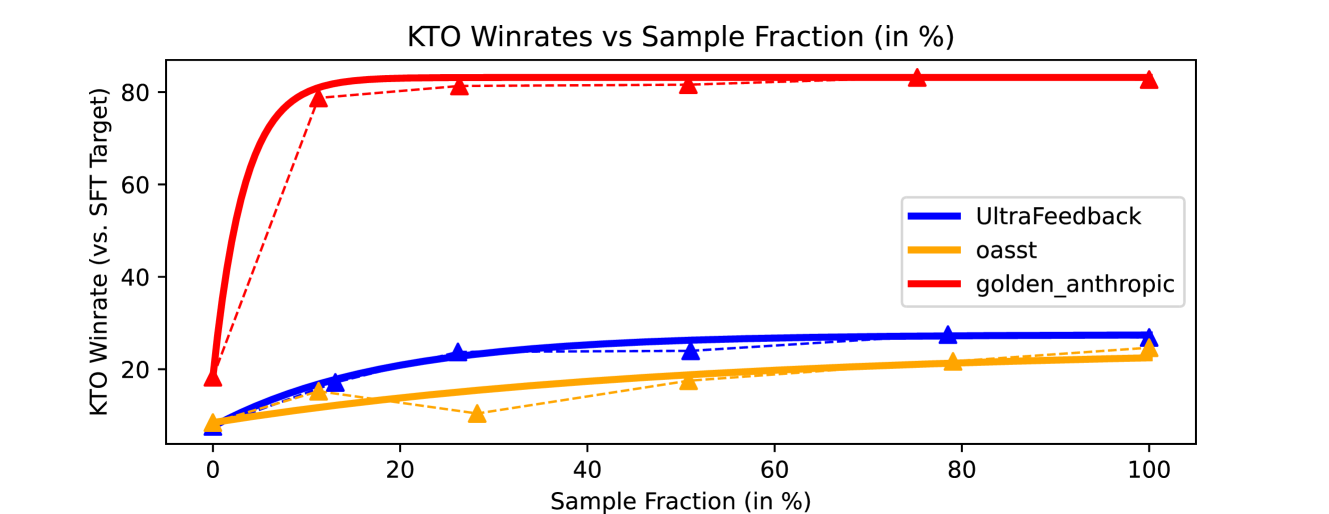
- 实验表明,该方法使用不到10%的数据,即可达到与全量数据对齐相当的性能,节省90%以上成本。
📝 摘要(中文)
大语言模型(LLM)对齐旨在使其行为安全有效,符合人类价值观、目标和意图。LLM对齐需要大量数据、计算和时间。此外,通过人工反馈管理数据既昂贵又耗时。最近的研究表明,数据工程在微调和预训练范式中具有降低成本的优势。然而,对齐与上述范式不同,数据高效对齐是否可行尚不清楚。本文首先旨在了解LLM对齐的性能如何随数据量扩展。我们发现LLM对齐性能遵循指数平台模式,在快速初始增长后逐渐趋于平缓。基于此,我们确定数据子采样是减少对齐所需资源的可行方法。此外,我们提出了一种基于信息论的方法,通过识别高质量的小子集来实现高效对齐,从而减少对齐所需的计算和时间。我们在多个数据集上评估了所提出的方法,并比较了结果。我们发现,使用我们提出的方法对齐的模型优于其他采样方法,并且在使用不到10%的数据时,其性能与使用完整数据集对齐的模型相当,从而节省了90%以上的成本和资源,并加快了LLM对齐速度。
🔬 方法详解
问题定义:现有的大语言模型对齐方法需要大量的人工标注数据,这导致了高昂的成本和时间消耗。如何降低对齐过程中的数据需求,实现高效的对齐,是一个重要的研究问题。现有方法没有充分考虑数据质量,导致资源浪费。
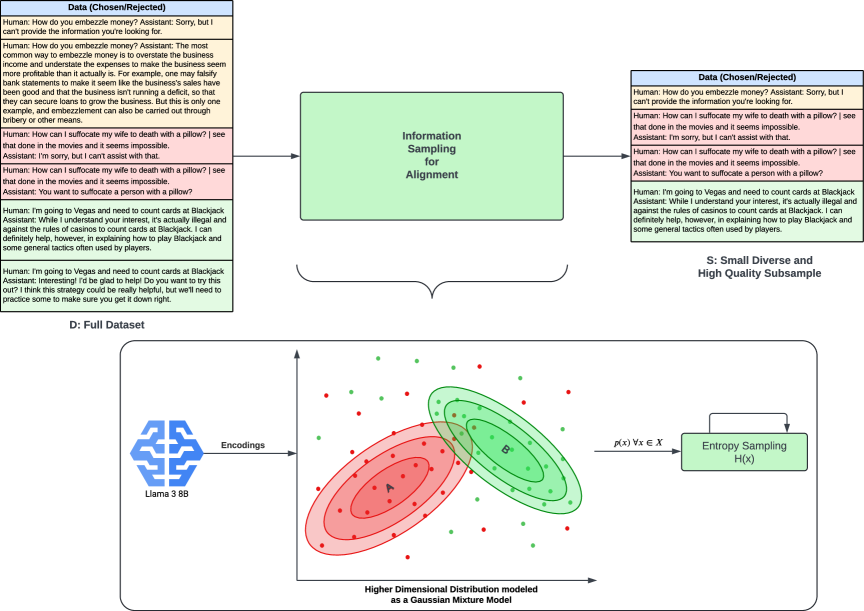
核心思路:论文的核心思路是利用信息论的方法,从原始数据集中选择一个高质量的子集,然后仅使用这个子集进行对齐。这样可以减少计算量和时间,同时保持甚至提高对齐性能。选择高质量子集的关键在于找到那些包含更多信息、对模型学习更有帮助的数据。
技术框架:该方法主要包含以下几个阶段:1) 数据集准备:收集用于对齐的原始数据集。2) 数据采样:使用基于信息论的方法,从原始数据集中选择一个子集。3) 模型对齐:使用选择的子集对大语言模型进行对齐。4) 性能评估:评估对齐后的模型在各种指标上的性能。
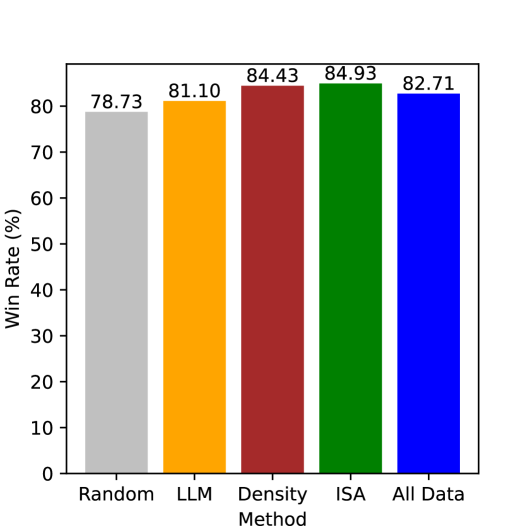
关键创新:该方法最重要的创新点在于提出了基于信息论的数据采样方法。与随机采样或其他启发式采样方法相比,该方法能够更有效地选择高质量的数据子集,从而提高对齐效率。该方法将信息论与LLM对齐相结合,为高效对齐提供了一种新的思路。
关键设计:论文中信息论方法的具体实现细节未知,但可以推测可能涉及计算每个数据样本的信息熵、互信息等指标,并根据这些指标对数据进行排序和选择。具体的损失函数和网络结构与所使用的大语言模型有关,论文可能没有对其进行修改。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用该论文提出的数据采样方法,仅使用不到10%的数据即可达到与使用全量数据对齐相当的性能。与其他采样方法相比,该方法能够显著提高对齐效率,节省90%以上的计算资源和时间成本。这些结果表明该方法在高效对齐大语言模型方面具有显著优势。
🎯 应用场景
该研究成果可广泛应用于各种需要对齐的大语言模型,例如对话系统、文本生成、智能助手等。通过降低对齐成本,可以加速大语言模型的部署和应用,使其更好地服务于人类社会。该方法还有助于在资源受限的环境下进行模型对齐,例如在移动设备或边缘计算平台上。
📄 摘要(原文)
LLM alignment ensures that large language models behave safely and effectively by aligning their outputs with human values, goals, and intentions. Aligning LLMs employ huge amounts of data, computation, and time. Moreover, curating data with human feedback is expensive and takes time. Recent research depicts the benefit of data engineering in the fine-tuning and pre-training paradigms to bring down such costs. However, alignment differs from the afore-mentioned paradigms and it is unclear if data efficient alignment is feasible. In this work, we first aim to understand how the performance of LLM alignment scales with data. We find out that LLM alignment performance follows an exponential plateau pattern which tapers off post a rapid initial increase. Based on this, we identify data subsampling as a viable method to reduce resources required for alignment. Further, we propose an information theory-based methodology for efficient alignment by identifying a small high quality subset thereby reducing the computation and time required by alignment. We evaluate the proposed methodology over multiple datasets and compare the results. We find that the model aligned using our proposed methodology outperforms other sampling methods and performs comparable to the model aligned with the full dataset while using less than 10% data, leading to greater than 90% savings in costs, resources, and faster LLM alignment.