Fair Resource Allocation in Weakly Coupled Markov Decision Processes
作者: Xiaohui Tu, Yossiri Adulyasak, Nima Akbarzadeh, Erick Delage
分类: cs.LG
发布日期: 2024-11-14 (更新: 2025-04-27)
💡 一句话要点
针对弱耦合MDP中的公平资源分配,提出基于Gini系数和深度强化学习的优化方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 公平资源分配 弱耦合MDP 广义Gini函数 深度强化学习 置换不变策略
📋 核心要点
- 传统资源分配通常以最大化总效用为目标,忽略了公平性,可能导致某些子MDP长期处于不利地位。
- 论文核心在于将公平性目标融入到弱耦合MDP的资源分配中,通过优化广义Gini函数来平衡不同子MDP的收益。
- 实验结果表明,所提出的基于深度强化学习的方法能够有效地在弱耦合MDP中实现公平的资源分配,优于传统方法。
📝 摘要(中文)
本文研究了弱耦合马尔可夫决策过程中的公平资源分配问题,其中资源约束耦合了N个子MDP的动作空间,这些子MDP原本可以独立运行。我们采用广义Gini函数作为公平性定义,而非传统的功利主义(总和)目标。在介绍了一种基于线性规划的通用但计算量巨大的解决方案后,我们专注于所有子MDP都相同的情况。对于这种情况,我们首次证明了该问题简化为优化“置换不变”策略类上的功利主义目标。这个结果特别有用,因为我们可以在restless bandits设置中利用Whittle index策略,同时,对于更一般的设置,我们引入了一种基于计数比例的深度强化学习方法。最后,我们通过全面的实验验证了我们的理论发现,证实了我们提出的方法在实现公平性方面的有效性。
🔬 方法详解
问题定义:论文旨在解决弱耦合马尔可夫决策过程(MDP)中的公平资源分配问题。现有方法通常采用功利主义目标,即最大化所有子MDP的总收益,而忽略了公平性。这种方法可能导致某些子MDP长期处于资源匮乏的状态,从而影响整体系统的稳定性和可持续性。因此,如何在资源约束下,保证各个子MDP之间的公平性,是一个重要的挑战。
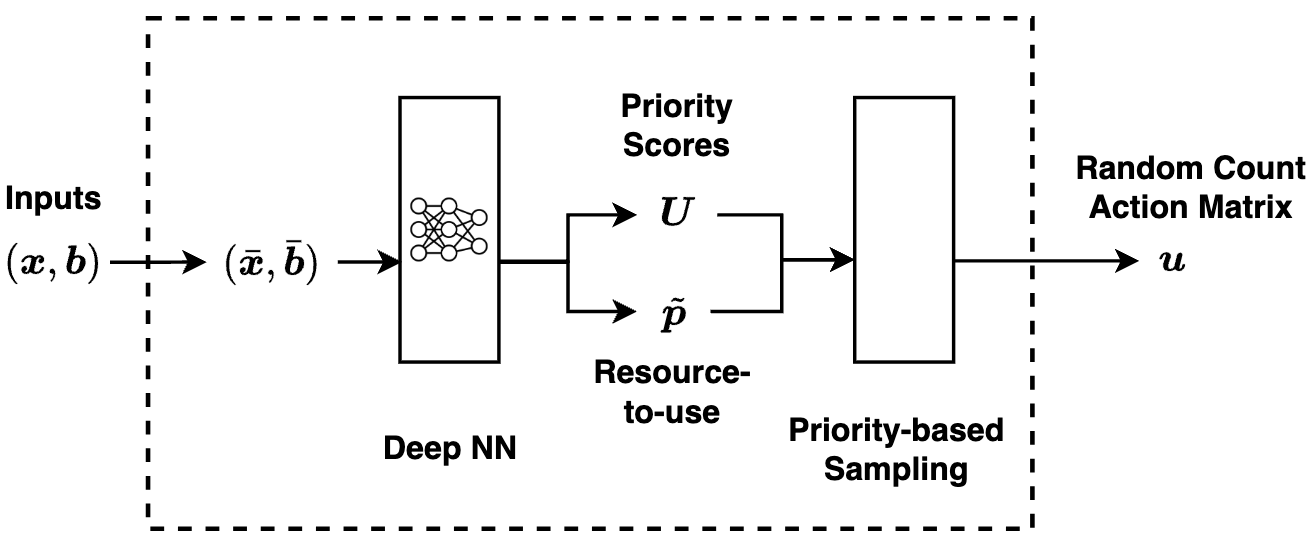
核心思路:论文的核心思路是将公平性目标融入到资源分配策略中。具体来说,论文采用广义Gini函数来衡量公平性,并通过优化该函数来平衡不同子MDP的收益。对于同构子MDP的情况,论文证明了该问题可以简化为优化置换不变策略类上的功利主义目标。对于更一般的情况,论文提出了一种基于计数比例的深度强化学习方法。
技术框架:整体框架包括以下几个主要阶段:1) 问题建模:将资源分配问题建模为弱耦合MDP,其中资源约束耦合了各个子MDP的动作空间。2) 公平性定义:采用广义Gini函数来衡量资源分配的公平性。3) 策略优化:对于同构子MDP,采用Whittle index策略;对于更一般的情况,采用基于计数比例的深度强化学习方法。4) 实验验证:通过实验验证所提出的方法在实现公平性方面的有效性。
关键创新:论文最重要的技术创新点在于:1) 首次将广义Gini函数引入到弱耦合MDP的资源分配问题中,从而能够显式地优化公平性。2) 证明了对于同构子MDP,该问题可以简化为优化置换不变策略类上的功利主义目标,从而大大降低了计算复杂度。3) 提出了一种基于计数比例的深度强化学习方法,能够有效地解决一般情况下的公平资源分配问题。
关键设计:在深度强化学习方法中,论文采用了基于计数比例的状态表示,即使用每个子MDP的状态访问次数的比例作为输入。这种表示方法能够有效地捕捉不同子MDP之间的差异,从而更好地实现公平性。此外,论文还设计了一种特殊的奖励函数,该函数既考虑了总收益,又考虑了公平性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的基于深度强化学习的方法在实现公平性方面明显优于传统的功利主义方法。具体来说,在同构子MDP的情况下,该方法能够达到与Whittle index策略相当的性能,同时显著提高了公平性指标。在异构子MDP的情况下,该方法也能够有效地平衡总收益和公平性,取得了良好的效果。
🎯 应用场景
该研究成果可应用于各种需要公平资源分配的场景,例如云计算资源调度、无线网络频谱分配、医疗资源分配等。通过优化广义Gini函数,可以确保各个用户或实体获得相对公平的资源分配,从而提高系统的整体效率和用户满意度。未来的研究可以进一步探索更复杂的资源约束和动态环境下的公平资源分配问题。
📄 摘要(原文)
We consider fair resource allocation in sequential decision-making environments modeled as weakly coupled Markov decision processes, where resource constraints couple the action spaces of $N$ sub-Markov decision processes (sub-MDPs) that would otherwise operate independently. We adopt a fairness definition using the generalized Gini function instead of the traditional utilitarian (total-sum) objective. After introducing a general but computationally prohibitive solution scheme based on linear programming, we focus on the homogeneous case where all sub-MDPs are identical. For this case, we show for the first time that the problem reduces to optimizing the utilitarian objective over the class of "permutation invariant" policies. This result is particularly useful as we can exploit Whittle index policies in the restless bandits setting while, for the more general setting, we introduce a count-proportion-based deep reinforcement learning approach. Finally, we validate our theoretical findings with comprehensive experiments, confirming the effectiveness of our proposed method in achieving fairness.