Communication Compression for Tensor Parallel LLM Inference
作者: Jan Hansen-Palmus, Michael Truong Le, Oliver Hausdörfer, Alok Verma
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-11-14 (更新: 2026-01-06)
💡 一句话要点
针对张量并行LLM推理,提出通信压缩方法以降低延迟。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 张量并行 通信压缩 量化 低延迟推理
📋 核心要点
- 大型语言模型推理对计算资源需求巨大,模型并行是常用解决方案,但加速器间通信成为瓶颈。
- 论文提出一种基于细粒度量化的通信压缩方法,旨在减少张量并行推理过程中的通信开销。
- 实验结果表明,该方法在几乎不影响模型性能的前提下,显著降低了首个token生成时间。
📝 摘要(中文)
大型语言模型(LLM)推动了人工智能的发展,但包含数千亿的参数和运算。为了加快推理速度,LLM通常通过各种模型并行策略部署在多个硬件加速器上。本文着重研究了一种策略——张量并行,并提出通过压缩加速器间的通信来降低延迟。我们利用细粒度的量化技术将选定的激活压缩了3.5到4.5倍。我们提出的方法在模型性能几乎没有下降的情况下,最多可将首个token生成时间(TTFT)减少2倍。
🔬 方法详解
问题定义:在张量并行的大型语言模型推理中,不同加速器之间需要频繁地进行数据交换,这导致了显著的通信开销,成为影响整体推理速度的关键瓶颈。现有方法通常侧重于优化计算过程,而忽略了通信环节的优化。
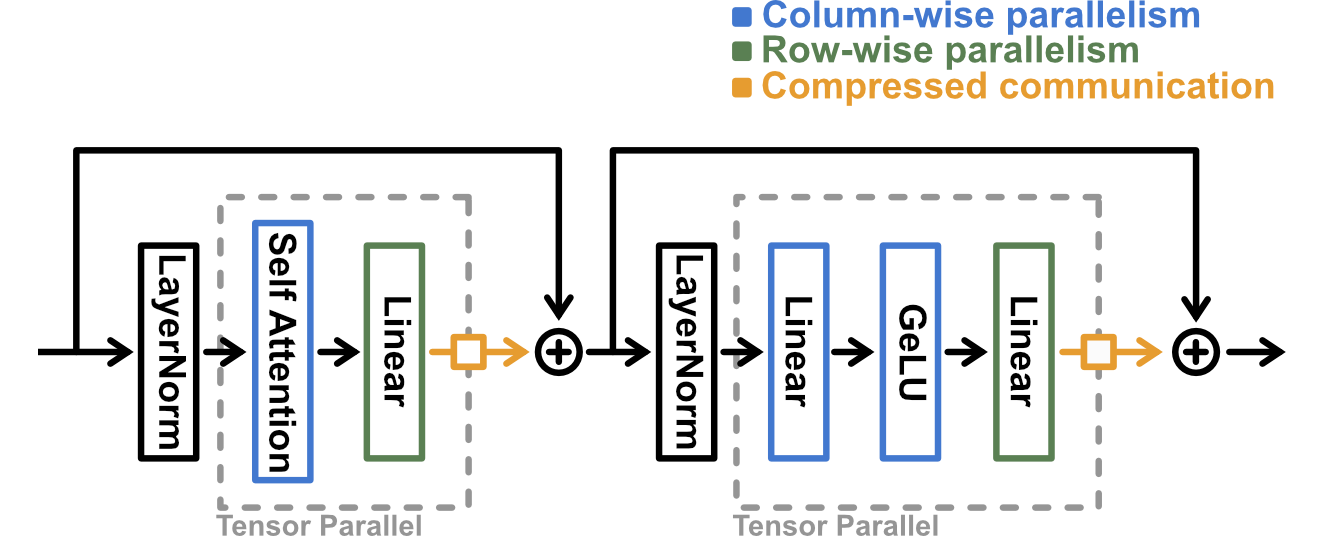
核心思路:论文的核心思路是通过压缩加速器之间传输的激活值来减少通信量。具体而言,通过细粒度的量化技术,将激活值表示为更低精度的数据类型,从而减少数据传输的大小。这样设计的目的是在保证模型性能的前提下,显著降低通信延迟。
技术框架:该方法主要包含以下几个阶段:首先,确定需要进行压缩的激活张量。然后,对这些张量应用细粒度的量化技术,将其转换为低精度表示。接下来,将压缩后的张量在加速器之间进行传输。最后,在接收端对张量进行解压缩,恢复到原始精度,用于后续的计算。整个过程旨在最小化对模型推理流程的侵入性。
关键创新:该方法最重要的创新点在于采用了细粒度的量化技术。与传统的粗粒度量化相比,细粒度量化能够更精确地表示激活值,从而在保证模型性能的同时,实现更高的压缩率。此外,该方法针对张量并行的特定通信模式进行了优化,能够更有效地减少通信开销。
关键设计:论文中关键的设计包括:选择合适的量化比特数,以平衡压缩率和模型性能;设计高效的量化和解量化算法,以减少额外的计算开销;以及优化通信协议,以减少数据传输的延迟。具体的参数设置和网络结构细节可能依赖于具体的LLM架构和硬件平台。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法可以将选定的激活压缩3.5到4.5倍,并且在模型性能几乎没有下降的情况下,最多可将首个token生成时间(TTFT)减少2倍。这一显著的性能提升表明了该方法在实际应用中的潜力。
🎯 应用场景
该研究成果可广泛应用于需要低延迟的大型语言模型推理服务,例如在线对话机器人、实时翻译和内容生成等。通过降低推理延迟,可以提升用户体验,并降低部署成本。未来,该技术有望推广到其他模型并行策略和硬件平台,进一步推动LLM的普及应用。
📄 摘要(原文)
Large Language Models (LLMs) have pushed the frontier of artificial intelligence but are comprised of hundreds of billions of parameters and operations. For faster inference latency, LLMs are deployed on multiple hardware accelerators through various Model Parallelism strategies. Our paper looks into the details on one such strategy - Tensor Parallel - and proposes to reduce latency by compressing inter-accelerator communication. We leverage fine grained quantization techniques to compress selected activations by 3.5 - 4.5x. Our proposed method leads up to 2x reduction of time-to-first-token (TTFT) with negligible model performance degradation.