Sparse Upcycling: Inference Inefficient Finetuning
作者: Sasha Doubov, Nikhil Sardana, Vitaliy Chiley
分类: cs.LG, cs.CL
发布日期: 2024-11-13
备注: 12 pages, 4 figures, To appear in the 4th NeurIPS Workshop on Efficient Natural Language and Speech Processing (ENLSP), 2024
💡 一句话要点
对比稀疏Upcycling与持续预训练,探索模型质量与推理效率的权衡。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏Upcycling 混合专家模型 持续预训练 模型质量 推理效率 语言模型 模型优化
📋 核心要点
- 小型语言模型推理效率高,但进一步提升模型质量面临挑战。
- 稀疏Upcycling将稠密模型转化为MoE架构,旨在提升模型参数量和质量。
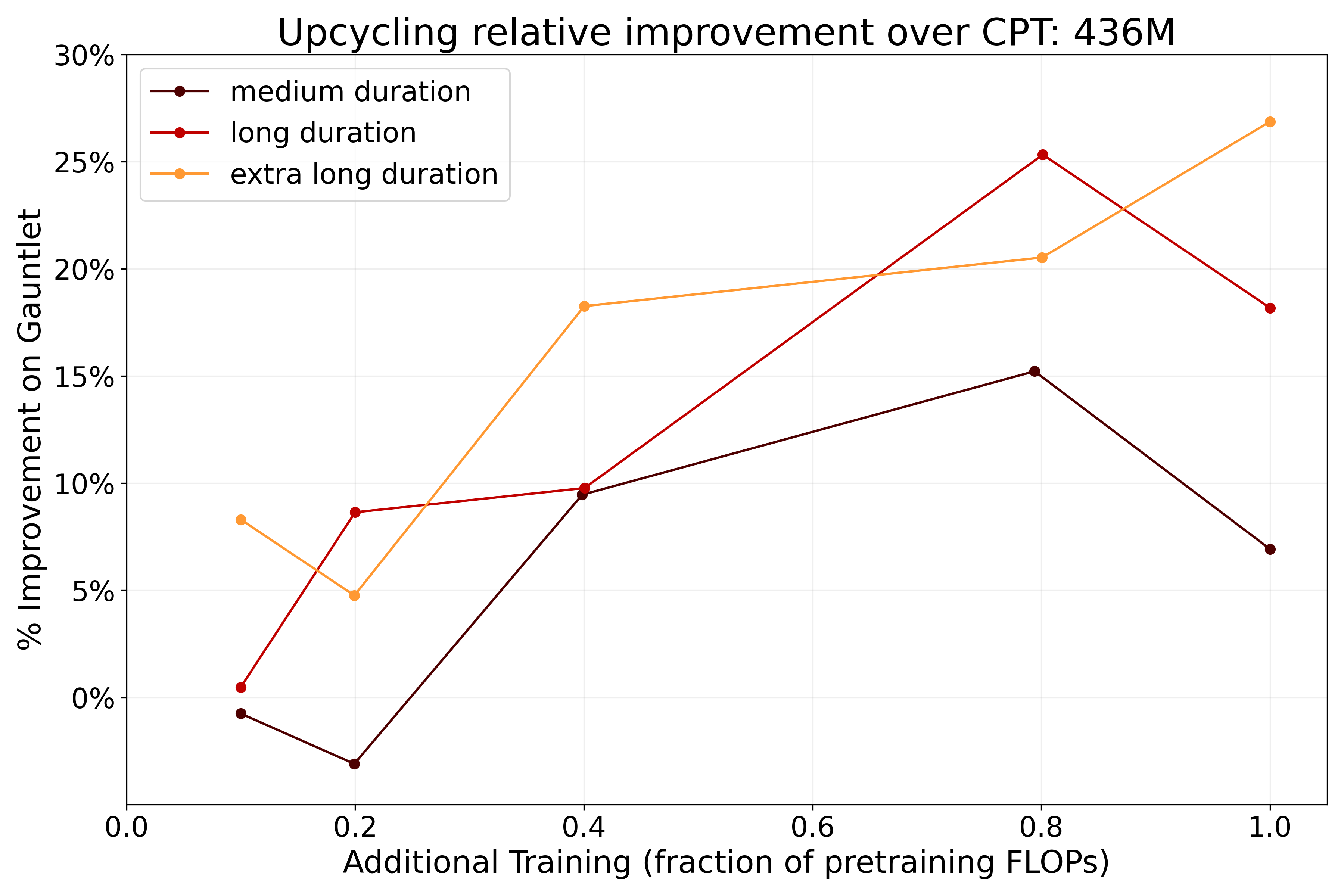
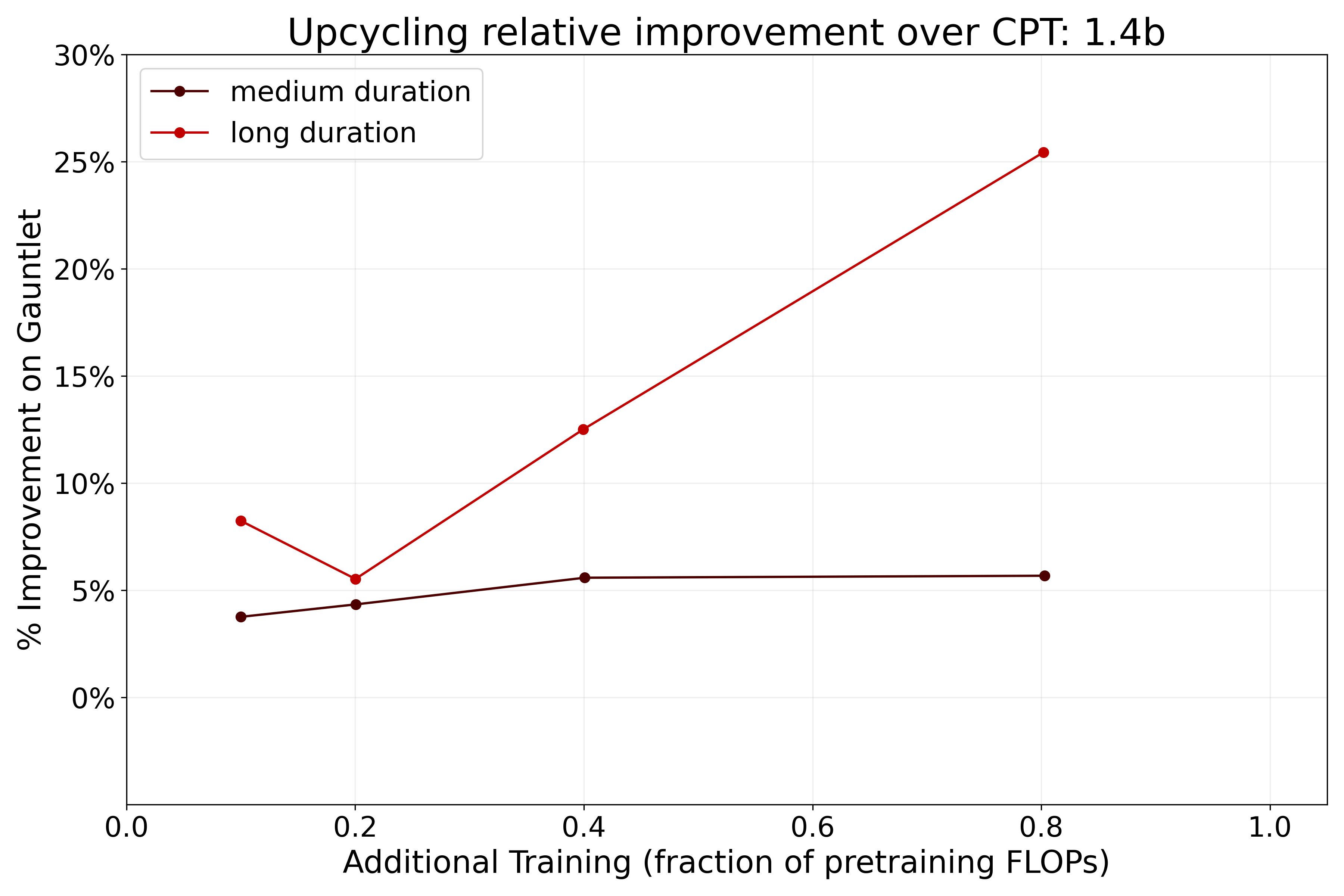
- 实验对比稀疏Upcycling与持续预训练,发现前者在特定场景下质量提升超过20%,但推理速度降低40%。
📝 摘要(中文)
由于推理效率,小型、高度训练的开源大型语言模型被广泛使用,但进一步提高其质量仍然是一个挑战。稀疏Upcycling是一种有前景的方法,它将预训练的稠密模型转换为混合专家(MoE)架构,从而增加模型的参数数量和质量。本文比较了稀疏Upcycling与持续预训练(CPT)在不同模型大小、计算预算和预训练持续时间上的有效性。实验表明,在某些情况下,稀疏Upcycling可以获得更好的质量,相对于CPT有超过20%的相对改进。然而,这也带来了显著的推理成本,导致大型模型在高需求推理设置中减慢40%。研究结果突出了模型质量和推理效率之间的权衡,为寻求平衡模型质量和部署约束的从业者提供了见解。
🔬 方法详解
问题定义:论文旨在解决小型语言模型在推理效率优先的前提下,如何进一步提升模型质量的问题。现有方法,如持续预训练(CPT),虽然可以提升模型性能,但可能无法充分利用计算资源,并且在某些情况下提升效果有限。稀疏Upcycling作为一种新兴技术,具有提升模型容量的潜力,但其有效性以及与CPT的对比尚不明确。
核心思路:论文的核心思路是通过将预训练的稠密模型转化为稀疏的混合专家(MoE)架构,从而增加模型的参数数量和质量。MoE架构允许模型在不同的输入上激活不同的专家子网络,从而提高模型的表达能力,同时保持较高的推理效率(因为每次推理只需要激活部分专家)。
技术框架:论文的整体框架是对比稀疏Upcycling和持续预训练两种方法。具体而言,首先使用预训练的稠密模型作为起点,然后分别采用稀疏Upcycling和持续预训练两种方式进行进一步训练。对于稀疏Upcycling,需要确定专家数量、路由策略等超参数。对于持续预训练,则需要选择合适的预训练数据和训练策略。最后,在相同的评估数据集上比较两种方法的性能。
关键创新:论文的关键创新在于系统性地对比了稀疏Upcycling和持续预训练在不同模型大小、计算预算和预训练持续时间下的性能。这为从业者提供了关于何时以及如何使用稀疏Upcycling的宝贵见解。此外,论文还量化了稀疏Upcycling带来的推理成本,强调了模型质量和推理效率之间的权衡。
关键设计:论文的关键设计包括:1) 针对不同模型大小(小型、中型、大型)进行实验;2) 采用不同的计算预算和预训练持续时间,以模拟不同的实际应用场景;3) 使用标准化的评估数据集来公平地比较不同方法的性能;4) 详细分析了稀疏Upcycling带来的推理延迟,并与持续预训练进行了对比。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在某些情况下,稀疏Upcycling可以获得比持续预训练更好的模型质量,相对提升超过20%。然而,稀疏Upcycling也带来了显著的推理成本,导致大型模型在高需求推理设置中减慢40%。这些结果清晰地展示了模型质量和推理效率之间的权衡,为实际应用提供了指导。
🎯 应用场景
该研究成果可应用于对推理效率有较高要求的场景,例如移动设备上的自然语言处理、实时对话系统等。通过权衡模型质量和推理效率,可以选择合适的训练策略,从而在有限的计算资源下获得最佳的模型性能。未来的研究可以探索更高效的稀疏Upcycling方法,例如动态调整专家数量、优化路由策略等。
📄 摘要(原文)
Small, highly trained, open-source large language models are widely used due to their inference efficiency, but further improving their quality remains a challenge. Sparse upcycling is a promising approach that transforms a pretrained dense model into a Mixture-of-Experts (MoE) architecture, increasing the model's parameter count and quality. In this work, we compare the effectiveness of sparse upcycling against continued pretraining (CPT) across different model sizes, compute budgets, and pretraining durations. Our experiments show that sparse upcycling can achieve better quality, with improvements of over 20% relative to CPT in certain scenarios. However, this comes with a significant inference cost, leading to 40% slowdowns in high-demand inference settings for larger models. Our findings highlight the trade-off between model quality and inference efficiency, offering insights for practitioners seeking to balance model quality and deployment constraints.