Can sparse autoencoders be used to decompose and interpret steering vectors?
作者: Harry Mayne, Yushi Yang, Adam Mahdi
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-11-13
💡 一句话要点
研究表明稀疏自编码器直接分解和解释steering vectors效果不佳,并分析了其原因。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Steering Vectors 稀疏自编码器 大语言模型 模型解释性 特征分解
📋 核心要点
- Steering vectors作为控制LLM行为的方法,其内在机制尚不明确,需要有效方法进行解释。
- 论文分析了直接使用稀疏自编码器(SAEs)分解steering vectors的局限性,并指出了其不适用的两个主要原因。
- 研究揭示了steering vectors的特性与SAEs的设计假设不符,导致SAEs无法有效分解和解释steering vectors。
📝 摘要(中文)
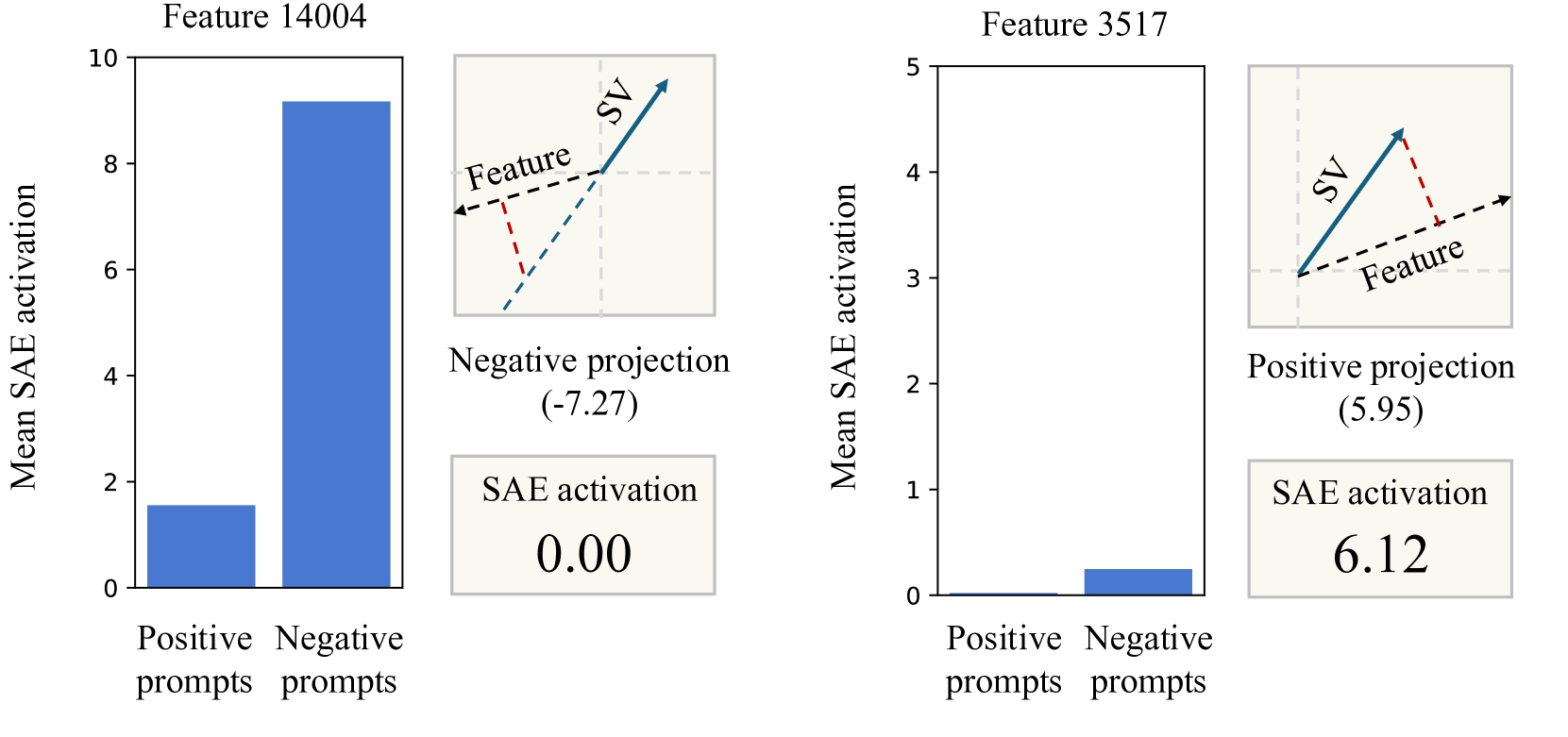
Steering vectors是一种很有前景的控制大型语言模型行为的方法。然而,其底层机制仍然知之甚少。虽然稀疏自编码器(SAEs)可能提供了一种解释steering vectors的潜在方法,但最近的研究结果表明,SAE重构的向量通常缺乏原始向量的steering特性。本文研究了为什么直接将SAEs应用于steering vectors会产生误导性的分解,并确定了两个原因:(1)steering vectors落在SAEs设计的输入分布之外,以及(2)steering vectors在特征方向上可能具有有意义的负投影,而SAEs并非旨在适应这种情况。这些限制阻碍了SAEs直接用于解释steering vectors。
🔬 方法详解
问题定义:论文旨在解决如何有效分解和解释steering vectors的问题。现有方法,即直接应用稀疏自编码器(SAEs),存在局限性,无法准确反映steering vectors的steering特性。痛点在于SAEs的重构向量缺乏原始向量的控制能力,导致对steering vectors的理解产生偏差。
核心思路:论文的核心思路是分析SAEs不适用于steering vectors的原因,并从数据分布和特征表示两个方面进行解释。具体来说,steering vectors的分布超出了SAEs的训练范围,且steering vectors包含SAEs无法处理的负投影。
技术框架:该论文主要是一个理论分析框架,没有提出新的模型或算法。其核心在于对现有方法(直接应用SAEs)的失效原因进行剖析,并提出改进方向。主要包含以下阶段:1. 分析steering vectors的特性;2. 分析SAEs的设计假设;3. 比较两者之间的差异;4. 总结SAEs不适用的原因。
关键创新:论文的关键创新在于发现了SAEs不适用于steering vectors的两个根本原因:一是steering vectors的分布与SAEs的输入分布不匹配;二是steering vectors包含SAEs无法处理的负投影。这为后续研究如何设计更有效的steering vector解释方法提供了理论基础。与现有方法直接应用SAEs不同,该论文强调了steering vectors的特殊性,并指出需要针对性地设计解释方法。
关键设计:该论文侧重于理论分析,没有涉及具体的参数设置、损失函数或网络结构设计。其关键在于对steering vectors和SAEs的特性进行深入理解,并在此基础上进行对比分析。未来的研究可以基于这些发现,设计新的自编码器结构或训练方法,以更好地适应steering vectors的特性。
🖼️ 关键图片


📊 实验亮点
该论文通过理论分析,明确指出了直接使用稀疏自编码器分解steering vectors的局限性,并从数据分布和特征表示两个方面解释了其原因。虽然没有提供具体的性能数据,但其分析结果为后续研究提供了重要的指导,有助于开发更有效的steering vector解释方法。
🎯 应用场景
该研究成果有助于更好地理解和控制大型语言模型的行为。通过深入理解steering vectors的内在机制,可以开发更有效的控制方法,提升LLM在特定任务上的性能,并降低其产生有害或不期望行为的风险。此外,该研究也为开发更通用的模型解释方法提供了思路。
📄 摘要(原文)
Steering vectors are a promising approach to control the behaviour of large language models. However, their underlying mechanisms remain poorly understood. While sparse autoencoders (SAEs) may offer a potential method to interpret steering vectors, recent findings show that SAE-reconstructed vectors often lack the steering properties of the original vectors. This paper investigates why directly applying SAEs to steering vectors yields misleading decompositions, identifying two reasons: (1) steering vectors fall outside the input distribution for which SAEs are designed, and (2) steering vectors can have meaningful negative projections in feature directions, which SAEs are not designed to accommodate. These limitations hinder the direct use of SAEs for interpreting steering vectors.