Measuring similarity between embedding spaces using induced neighborhood graphs
作者: Tiago F. Tavares, Fabio Ayres, Paris Smaragdis
分类: cs.LG
发布日期: 2024-11-13
💡 一句话要点
提出基于近邻图结构的嵌入空间相似度度量方法,用于评估配对嵌入的质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 嵌入空间相似度 近邻图 类比推理 零样本分类 跨模态学习
📋 核心要点
- 现有方法难以有效评估配对嵌入空间之间的相似性,尤其是在不同尺度下结构相似性的识别。
- 论文提出一种基于近邻图结构相似性的度量方法,通过比较嵌入空间中近邻关系来评估相似度。
- 实验表明,该方法能够识别不同尺度的相似结构,并且嵌入相似性与类比和零样本分类任务的准确性相关。
📝 摘要(中文)
深度学习技术在生成能够捕捉项目之间语义相似性的嵌入空间方面表现出色。这些表示通常是成对的,从而能够进行类比(同一领域内的配对)和跨模态(跨领域的配对)实验。这些实验基于关于嵌入空间几何形状的特定假设,这些假设允许通过推断训练数据集中嵌入对之间的位置关系来找到配对项目,从而实现诸如寻找新类比和多模态零样本分类等任务。在这项工作中,我们提出了一种度量标准来评估配对项目表示之间的相似性。我们的提议建立在每个表示的最近邻诱导图的结构相似性之上,并且可以配置为基于不同的距离度量和不同的邻域大小来比较空间。我们证明了我们的提议可以用于识别不同尺度的相似结构,这对于诸如中心核对齐(CKA)之类的核方法来说很难实现。我们通过两个案例研究进一步说明了我们的方法:使用GloVe嵌入的类比任务和使用CLIP嵌入的CIFAR-100数据集中的零样本分类。我们的结果表明,类比和零样本分类任务的准确性与嵌入相似性相关。这些发现有助于解释这些任务中的性能差异,并可能有助于未来改进配对嵌入模型的设计。
🔬 方法详解
问题定义:论文旨在解决如何有效衡量配对嵌入空间相似性的问题。现有方法,如中心核对齐(CKA),在识别不同尺度的结构相似性方面存在局限性,无法充分利用嵌入空间中的近邻关系信息。这导致难以解释和改进基于配对嵌入的模型在类比和零样本分类等任务中的性能差异。
核心思路:核心思路是利用嵌入空间中每个点的近邻结构来表征该空间的几何特性,并通过比较这些近邻图的结构相似性来衡量嵌入空间的相似度。这种方法能够捕捉不同尺度的结构信息,并且对嵌入空间的具体维度和分布不敏感。
技术框架:该方法主要包含以下几个步骤:1) 对每个嵌入空间,构建基于近邻关系的图结构。可以选择不同的距离度量(如欧氏距离、余弦相似度)和邻域大小(k值)。2) 计算两个图结构之间的相似性。可以使用各种图相似性度量方法,例如Jaccard系数、PageRank相关性等。3) 将计算得到的图相似性作为两个嵌入空间相似度的度量。
关键创新:关键创新在于将嵌入空间的相似性问题转化为图结构的相似性问题。通过引入近邻图的概念,能够更好地捕捉嵌入空间中的局部结构信息,从而更准确地评估嵌入空间之间的相似性。与传统的核方法相比,该方法能够识别不同尺度的相似结构。
关键设计:关键设计包括:1) 近邻数量k的选择:k值影响近邻图的密度,需要根据具体数据集和任务进行调整。2) 距离度量的选择:不同的距离度量适用于不同的数据类型和嵌入空间。3) 图相似性度量的选择:不同的图相似性度量方法对图结构的敏感度不同,需要根据具体应用场景进行选择。论文中使用了Jaccard系数作为图相似性度量。
🖼️ 关键图片
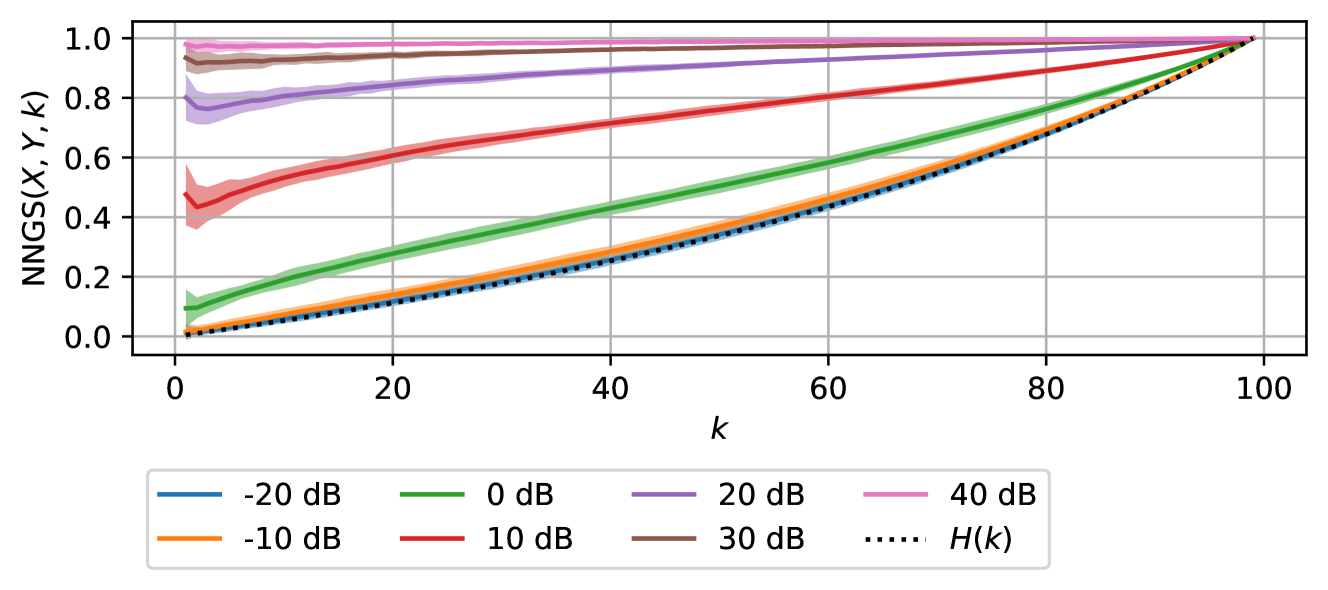
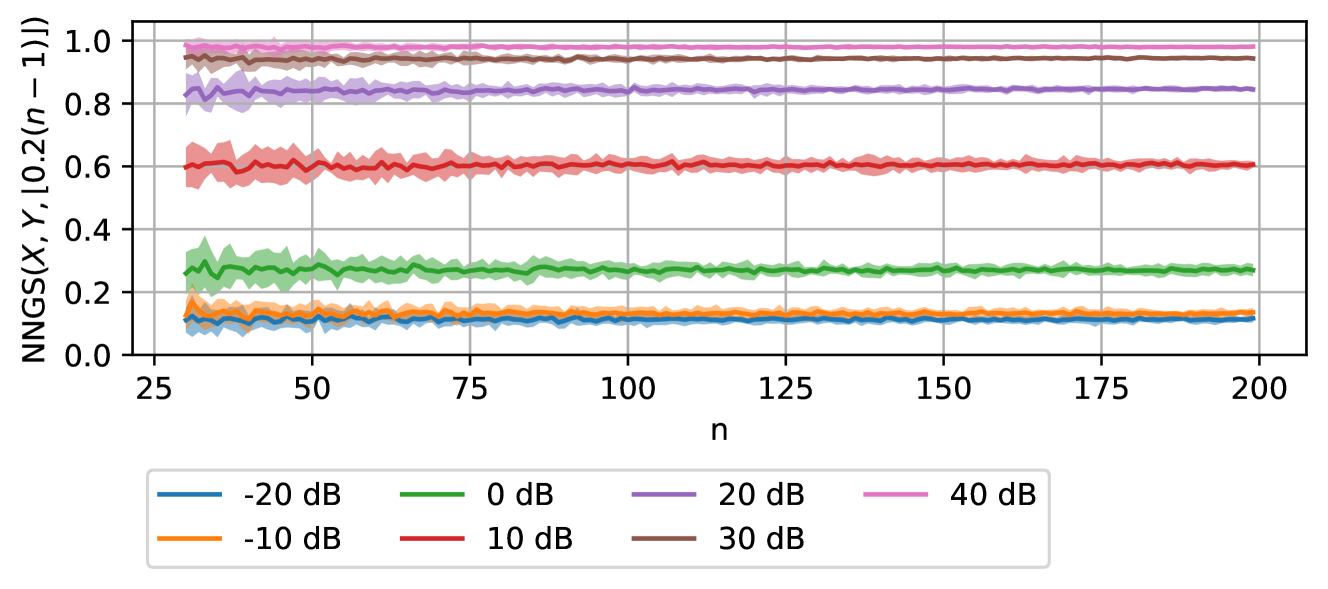

📊 实验亮点
论文通过在GloVe嵌入的类比任务和CLIP嵌入的CIFAR-100数据集零样本分类任务上的实验,验证了所提出方法的有效性。实验结果表明,嵌入空间相似度与类比和零样本分类的准确率之间存在显著的相关性。这表明该方法能够有效地评估嵌入空间的质量,并解释不同模型在这些任务上的性能差异。
🎯 应用场景
该研究成果可应用于多种领域,例如跨模态检索、零样本学习、知识图谱对齐等。通过评估不同嵌入空间的相似性,可以更好地理解和利用不同模态或领域的信息,从而提升相关任务的性能。此外,该方法还可以用于指导配对嵌入模型的训练和设计,例如选择合适的损失函数和网络结构。
📄 摘要(原文)
Deep Learning techniques have excelled at generating embedding spaces that capture semantic similarities between items. Often these representations are paired, enabling experiments with analogies (pairs within the same domain) and cross-modality (pairs across domains). These experiments are based on specific assumptions about the geometry of embedding spaces, which allow finding paired items by extrapolating the positional relationships between embedding pairs in the training dataset, allowing for tasks such as finding new analogies, and multimodal zero-shot classification. In this work, we propose a metric to evaluate the similarity between paired item representations. Our proposal is built from the structural similarity between the nearest-neighbors induced graphs of each representation, and can be configured to compare spaces based on different distance metrics and on different neighborhood sizes. We demonstrate that our proposal can be used to identify similar structures at different scales, which is hard to achieve with kernel methods such as Centered Kernel Alignment (CKA). We further illustrate our method with two case studies: an analogy task using GloVe embeddings, and zero-shot classification in the CIFAR-100 dataset using CLIP embeddings. Our results show that accuracy in both analogy and zero-shot classification tasks correlates with the embedding similarity. These findings can help explain performance differences in these tasks, and may lead to improved design of paired-embedding models in the future.