Efficient Federated Finetuning of Tiny Transformers with Resource-Constrained Devices
作者: Kilian Pfeiffer, Mohamed Aboelenien Ahmed, Ramin Khalili, Jörg Henkel
分类: cs.LG, cs.AI, cs.DC
发布日期: 2024-11-12 (更新: 2025-04-16)
💡 一句话要点
提出一种高效联邦微调Tiny Transformer的层微调方案,解决资源受限设备上的内存和计算瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 Tiny Transformer 参数高效微调 资源约束 层选择
📋 核心要点
- 大型语言模型微调计算和内存开销巨大,LoRA等方法在联邦学习中仍存在效率问题。
- 提出一种新的层微调方案,使联邦学习中的设备能够在资源约束下有效利用预训练模型。
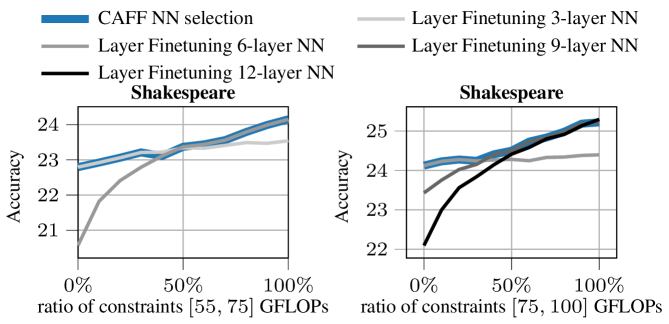
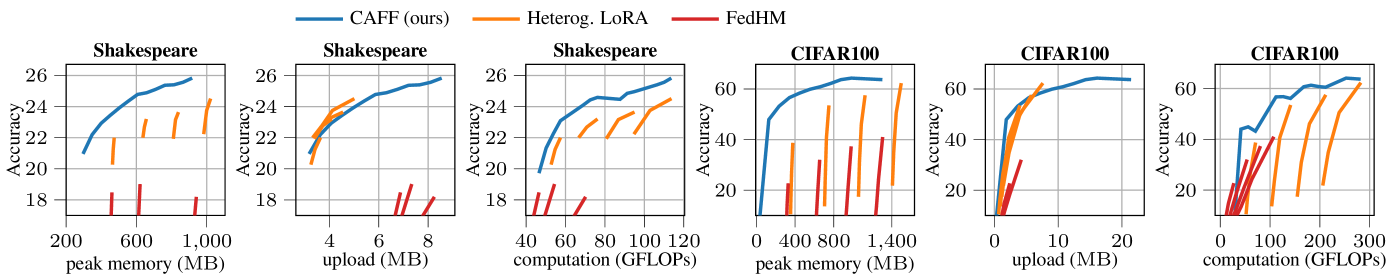
- 实验表明,该方案在同构和异构资源约束下均优于现有技术,并在通信限制下与LoRA相当,精度更高。
📝 摘要(中文)
近年来,基于Transformer结构的大型语言模型(LLM)在许多机器学习任务中占据主导地位,尤其是在文本处理方面。然而,这些模型需要大量的数据进行训练,并且对资源要求很高,特别是在浮点运算(FLOPs)的数量和所需的内存方面。为了以参数高效的方式微调这样的模型,已经开发了诸如Adapter或LoRA之类的技术。然而,我们观察到,当在联邦学习(FL)中使用时,LoRA虽然仍然是参数高效的,但在内存和FLOP方面效率低下。基于这一观察,我们开发了一种新的层微调方案,该方案允许跨设备FL中的设备利用预训练的神经网络(NN),同时遵守给定的资源约束。我们表明,当处理同构或异构计算和内存约束时,我们提出的方案优于当前的技术水平,并且在有限的通信方面与LoRA相当,从而在FL训练中实现了显着更高的准确性。
🔬 方法详解
问题定义:论文旨在解决在资源受限的联邦学习环境中,如何高效地微调Tiny Transformer模型的问题。现有方法,如LoRA,虽然参数效率高,但在内存和计算效率方面存在不足,尤其是在设备异构性较高的情况下,容易成为瓶颈。
核心思路:论文的核心思路是提出一种新的层微调方案,该方案能够根据设备的计算和内存资源约束,选择性地微调Transformer模型的不同层。通过这种方式,可以在保证模型性能的同时,最大限度地降低计算和内存开销。
技术框架:该方案主要包含以下几个阶段:1) 资源分析:收集联邦学习系统中各个设备的计算和内存资源信息。2) 层选择:根据资源信息,选择需要微调的Transformer模型的层。选择策略旨在平衡模型性能和资源消耗。3) 联邦微调:在选定的层上进行联邦学习微调,使用联邦平均等算法聚合各个设备的更新。4) 模型部署:将微调后的模型部署到各个设备上。
关键创新:该方案的关键创新在于提出了一种资源感知的层选择策略。与传统的微调方法(如全参数微调或LoRA)不同,该策略能够根据设备的实际资源情况,动态地选择需要微调的层,从而实现更高的资源利用率和模型性能。
关键设计:层选择策略是该方案的关键。具体来说,可以设计一个评分函数,用于评估每个层的重要性和资源消耗。评分函数可以考虑层的参数数量、计算复杂度以及对模型性能的影响等因素。然后,根据评分函数的结果,选择评分最高的若干层进行微调。此外,还可以设计一个自适应的层选择算法,根据训练过程中的性能反馈,动态地调整层选择策略。
🖼️ 关键图片
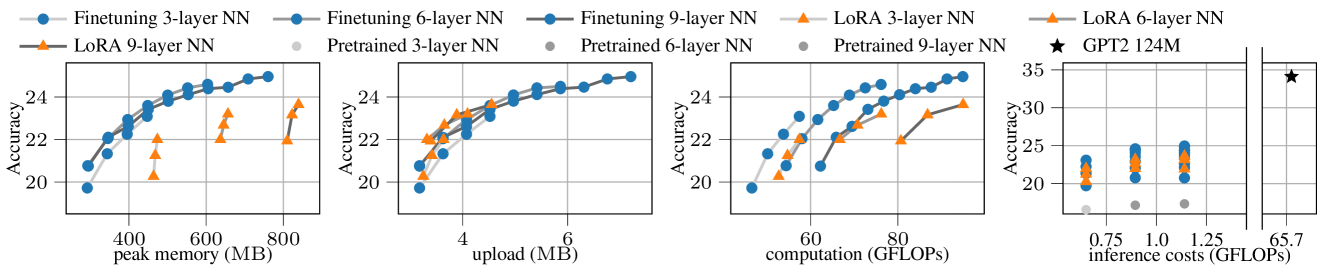
📊 实验亮点
实验结果表明,该方案在同构和异构计算和内存约束下均优于现有技术水平。具体来说,在某些实验设置下,该方案的准确率比LoRA提高了5%以上,同时显著降低了计算和内存开销。此外,该方案在有限的通信条件下与LoRA相当,表明其具有良好的通信效率。
🎯 应用场景
该研究成果可应用于各种资源受限的联邦学习场景,例如移动设备上的自然语言处理、边缘计算环境下的智能推荐等。通过高效地微调Tiny Transformer模型,可以在保护用户隐私的同时,提升设备上的AI应用性能,并降低部署成本,具有广泛的应用前景。
📄 摘要(原文)
In recent years, Large Language Models (LLMs) through Transformer structures have dominated many machine learning tasks, especially text processing. However, these models require massive amounts of data for training and induce high resource requirements, particularly in terms of the large number of Floating Point Operations (FLOPs) and the high amounts of memory needed. To fine-tune such a model in a parameter-efficient way, techniques like Adapter or LoRA have been developed. However, we observe that the application of LoRA, when used in federated learning (FL), while still being parameter-efficient, is memory and FLOP inefficient. Based on that observation, we develop a novel layer finetuning scheme that allows devices in cross-device FL to make use of pretrained neural networks (NNs) while adhering to given resource constraints. We show that our presented scheme outperforms the current state of the art when dealing with homogeneous or heterogeneous computation and memory constraints and is on par with LoRA regarding limited communication, thereby achieving significantly higher accuracies in FL training.