Entropy Controllable Direct Preference Optimization
作者: Motoki Omura, Yasuhiro Fujita, Toshiki Kataoka
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-11-12 (更新: 2025-06-13)
备注: ICML 2025 Workshop on Models of Human Feedback for AI Alignment
💡 一句话要点
提出H-DPO,通过熵控制增强DPO的性能,提升LLM在数学任务中的表现。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 直接偏好优化 强化学习 人类反馈 熵控制 语言模型 策略优化 数学任务
📋 核心要点
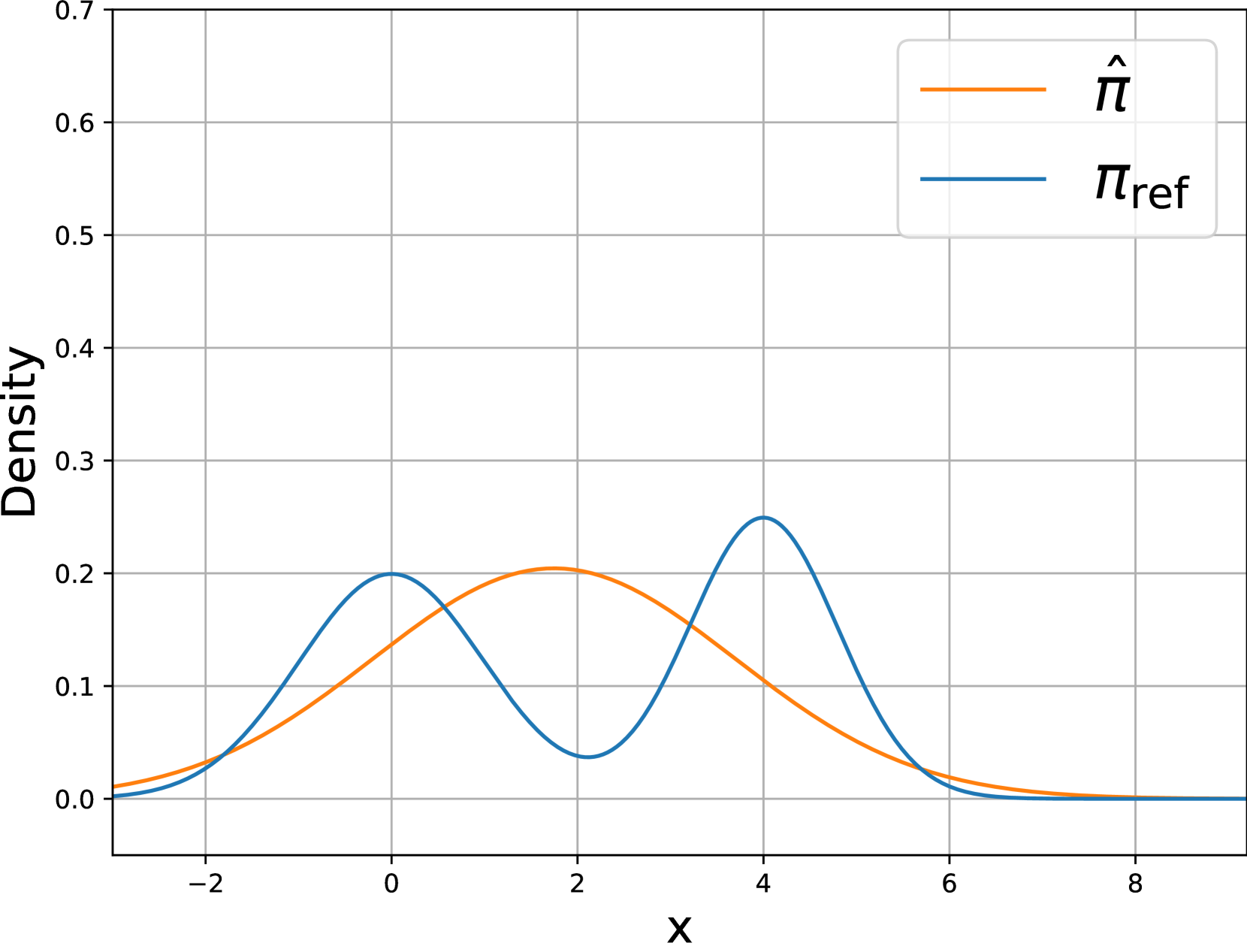
- DPO虽然避免了奖励模型的训练,但其反向KL散度正则化可能导致无法有效捕捉参考策略的模式。
- H-DPO通过引入熵控制机制,增强策略分布的清晰度,从而更有效地进行模式寻找拟合。
- 实验表明,H-DPO在多种任务上超越了DPO,尤其在数学任务的pass@$k$评估中表现出显著优势。
📝 摘要(中文)
在大型语言模型(LLM)的后训练中,从人类反馈中进行强化学习(RLHF)是一种有效的方法,可以实现与人类偏好对齐的生成。直接偏好优化(DPO)允许使用简单的二元交叉熵损失进行策略训练,而无需奖励模型。DPO的目标受到反向KL散度的正则化,鼓励模式寻找拟合参考策略。然而,我们指出,最小化反向KL散度可能无法捕捉到参考分布的模式,这可能会损害策略的性能。基于这一观察,我们提出了一种对DPO的简单修改,H-DPO,它允许控制结果策略的熵,增强分布的清晰度,从而更有效地实现模式寻找拟合。在我们的实验中,我们表明H-DPO在各种任务中优于DPO,在数学任务的pass@$k$评估中表现出卓越的结果。此外,H-DPO易于实现,只需要对DPO的损失计算进行微小的修改,这使得它在LLM训练的广泛应用中具有高度的实用性和前景。
🔬 方法详解
问题定义:DPO在训练过程中,使用反向KL散度来约束学习到的策略与参考策略之间的差异,以保证训练的稳定性。然而,过度依赖反向KL散度可能导致模型无法充分探索参考策略分布的各个模式,从而限制了模型的性能。现有DPO方法缺乏对策略熵的有效控制,可能导致次优解。
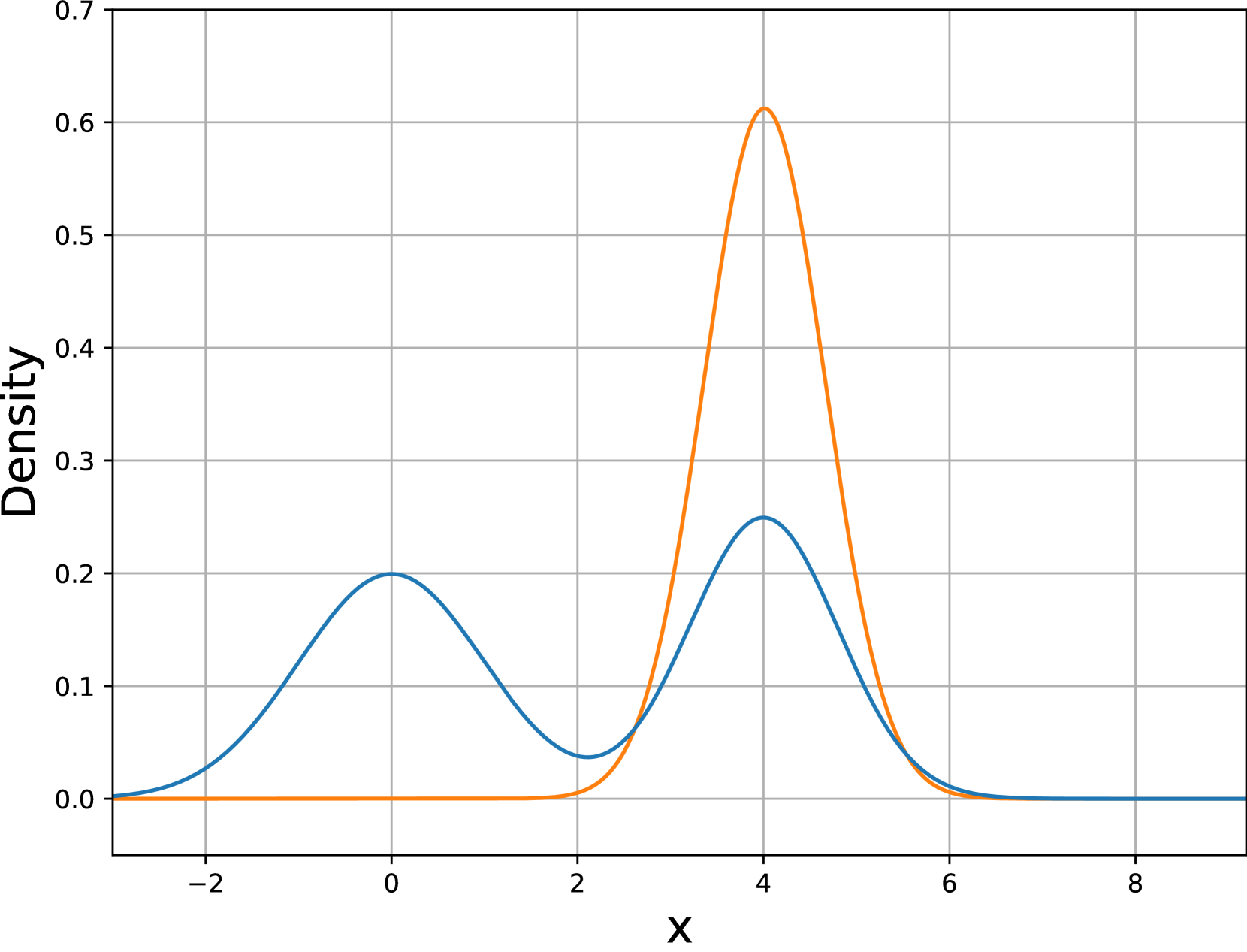
核心思路:H-DPO的核心思想是通过显式地控制策略的熵,来改善DPO的性能。通过调整策略分布的“锐利度”,H-DPO能够更有效地捕捉参考策略分布中的重要模式,从而提升模型的生成质量和准确性。这种方法旨在克服DPO中反向KL散度可能导致的模式捕捉不足的问题。
技术框架:H-DPO的整体框架与DPO类似,仍然采用二元交叉熵损失进行策略训练,避免了奖励模型的训练。关键区别在于损失函数中引入了一个额外的熵正则化项,用于显式地控制策略的熵。训练过程包括:1)收集人类偏好数据;2)使用H-DPO损失函数训练语言模型;3)评估模型性能。
关键创新:H-DPO的关键创新在于引入了熵控制机制,允许用户显式地调整策略的熵。这与传统的DPO方法不同,后者仅通过反向KL散度进行隐式的正则化。通过控制熵,H-DPO能够更灵活地调整策略分布的形状,从而更好地捕捉参考策略的模式。
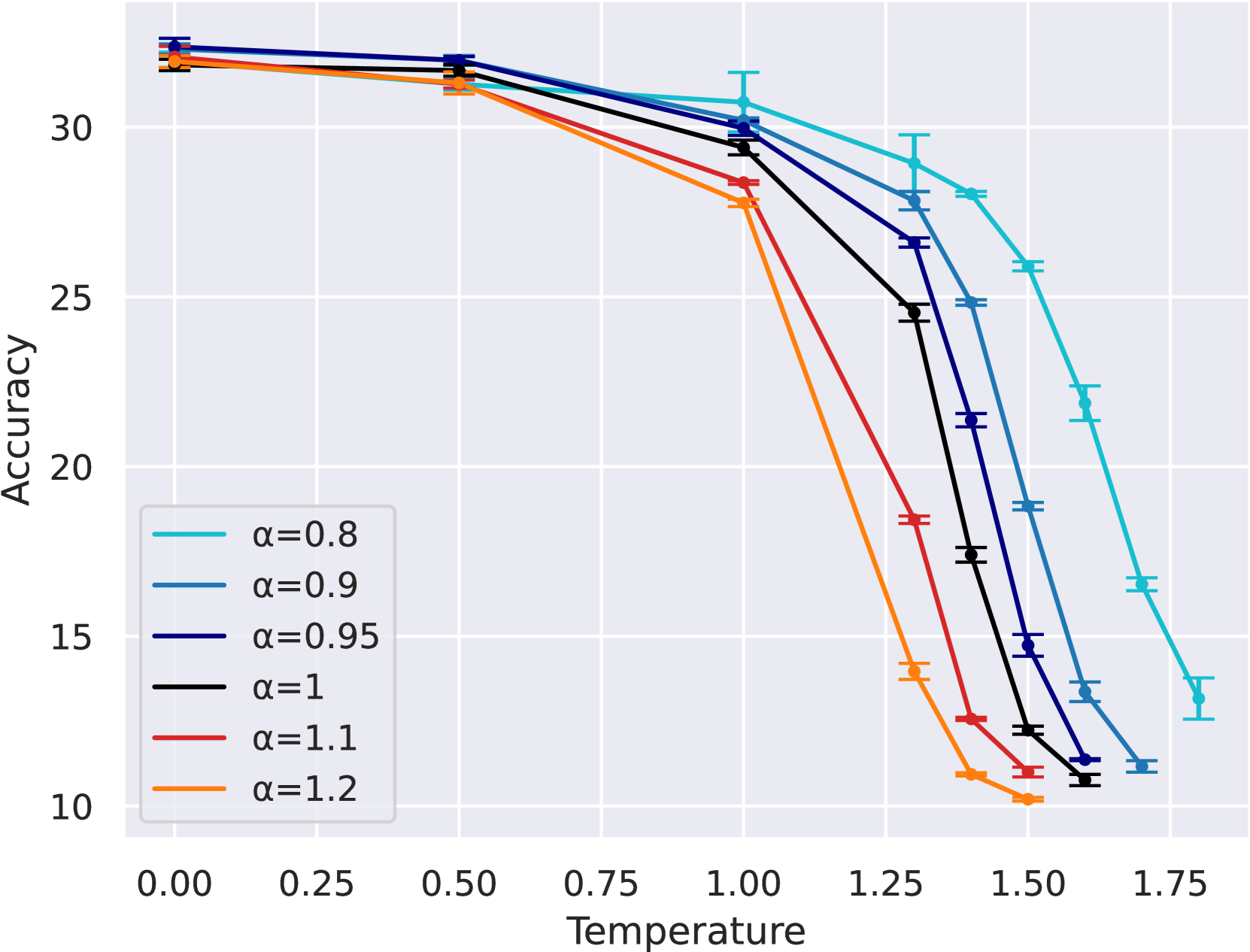
关键设计:H-DPO的损失函数是在DPO的损失函数基础上增加了一个熵正则化项。具体来说,损失函数可以表示为:L = DPO Loss + λ * H(π),其中DPO Loss是标准的DPO损失函数,H(π)是策略π的熵,λ是熵正则化系数,用于控制熵正则化的强度。λ是一个重要的超参数,需要根据具体任务进行调整。较大的λ值鼓励更高的熵,从而使策略分布更加平滑;较小的λ值鼓励更低的熵,从而使策略分布更加尖锐。
🖼️ 关键图片
📊 实验亮点
实验结果表明,H-DPO在多个任务上优于DPO。特别是在数学任务的pass@$k$评估中,H-DPO取得了显著的性能提升,表明其能够更有效地捕捉参考策略的模式。例如,在某些数学任务上,H-DPO的pass@$k$指标比DPO提高了5%以上。这些结果验证了H-DPO的有效性和优越性。
🎯 应用场景
H-DPO具有广泛的应用前景,可以应用于各种需要从人类反馈中进行学习的语言模型训练任务,例如对话生成、文本摘要、代码生成等。通过控制策略的熵,H-DPO可以提高生成结果的质量和准确性,从而提升用户体验。此外,H-DPO的简单性和易于实现的特点使其能够快速地应用于现有的DPO训练流程中。
📄 摘要(原文)
In the post-training of large language models (LLMs), Reinforcement Learning from Human Feedback (RLHF) is an effective approach to achieve generation aligned with human preferences. Direct Preference Optimization (DPO) allows for policy training with a simple binary cross-entropy loss without a reward model. The objective of DPO is regularized by reverse KL divergence that encourages mode-seeking fitting to the reference policy. Nonetheless, we indicate that minimizing reverse KL divergence could fail to capture a mode of the reference distribution, which may hurt the policy's performance. Based on this observation, we propose a simple modification to DPO, H-DPO, which allows for control over the entropy of the resulting policy, enhancing the distribution's sharpness and thereby enabling mode-seeking fitting more effectively. In our experiments, we show that H-DPO outperformed DPO across various tasks, demonstrating superior results in pass@$k$ evaluations for mathematical tasks. Moreover, H-DPO is simple to implement, requiring only minor modifications to the loss calculation of DPO, which makes it highly practical and promising for wide-ranging applications in the training of LLMs.