Comparing Bottom-Up and Top-Down Steering Approaches on In-Context Learning Tasks
作者: Madeline Brumley, Joe Kwon, David Krueger, Dmitrii Krasheninnikov, Usman Anwar
分类: cs.LG
发布日期: 2024-11-11
💡 一句话要点
对比自底向上和自顶向下引导方法在上下文学习任务中的有效性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可解释性 向量引导 上下文学习 自底向上 自顶向下 函数向量 上下文向量
📋 核心要点
- 大型语言模型的可解释性研究旨在开发引导模型行为的方法,但自底向上和自顶向下两种方法缺乏定量比较。
- 本文对比了函数向量(FV)和上下文向量(ICV)这两种代表性的方法,分别代表自底向上和自顶向下两种思路。
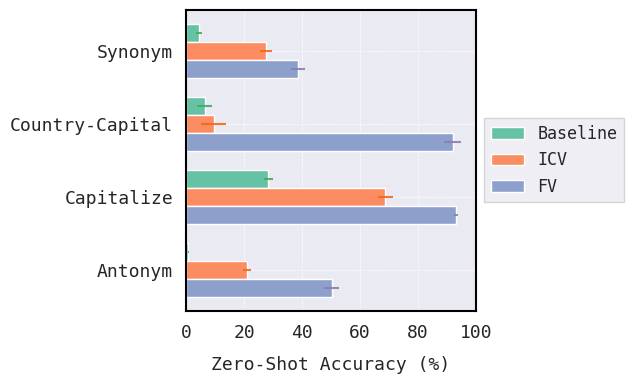
- 实验表明,ICV在行为转移任务中表现更好,而FV在需要更高精度的任务中表现更优,揭示了两种方法的适用范围。
📝 摘要(中文)
大型语言模型(LLM)可解释性研究的一个关键目标是开发能够稳健地引导模型朝着期望行为发展的方法。为此,已经提出了两种截然不同的可解释性方法——“自底向上”和“自顶向下”——但两者之间几乎没有定量的比较。本文通过案例研究,比较了每种方法中具有代表性的向量引导方法的有效性:函数向量(FV;arXiv:2310.15213)作为一种自底向上的方法,以及上下文向量(ICV;arXiv:2311.06668)作为一种自顶向下的方法。虽然两者都旨在捕获广泛的上下文学习任务的紧凑表示,但我们发现它们仅在特定类型的任务上有效:ICV在行为转移方面优于FV,而FV在需要更高精度的任务中表现出色。我们讨论了这些发现对未来引导方法评估以及对自顶向下和自底向上引导的进一步研究的意义。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的可解释性问题,具体来说,是如何有效地引导LLM产生期望的行为。现有的自底向上和自顶向下引导方法缺乏直接的定量比较,导致难以选择合适的引导策略来完成特定任务。两种方法的优缺点尚不明确,限制了它们在实际应用中的效果。
核心思路:论文的核心思路是通过对比两种代表性的引导方法(FV和ICV)在不同类型的上下文学习任务上的表现,来揭示它们的优势和局限性。通过实验分析,确定哪种方法更适合哪种类型的任务,从而为未来的引导方法选择和研究提供指导。这种对比分析有助于更深入地理解自底向上和自顶向下引导的本质区别。
技术框架:论文的技术框架主要包括以下几个步骤:1)选择两种代表性的引导方法:自底向上的函数向量(FV)和自顶向下的上下文向量(ICV)。2)设计不同类型的上下文学习任务,例如行为转移和需要高精度的任务。3)使用FV和ICV对LLM进行引导,并在不同的任务上评估它们的性能。4)分析实验结果,比较FV和ICV的优缺点,并讨论其对未来研究的意义。
关键创新:论文的关键创新在于首次对自底向上和自顶向下的引导方法进行了直接的定量比较。以往的研究主要集中在单个方法的改进上,而忽略了不同方法之间的差异和适用范围。通过对比FV和ICV,论文揭示了两种方法在不同任务上的性能差异,为未来的引导方法研究提供了新的视角。
关键设计:论文的关键设计包括:1)选择具有代表性的FV和ICV作为对比对象。2)设计能够区分两种方法性能差异的上下文学习任务。3)使用标准的评估指标来衡量引导效果。4)对实验结果进行详细的分析,包括统计显著性检验和误差分析。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ICV在行为转移任务中表现优于FV,而FV在需要更高精度的任务中表现更出色。这一发现揭示了两种引导方法在不同任务上的适用性差异,为未来的引导方法选择和研究提供了重要的参考依据。具体性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于需要精确控制大型语言模型行为的场景,例如:对话系统中的个性化回复、文本生成中的风格控制、以及安全敏感领域的风险规避。通过选择合适的引导方法,可以提高LLM在特定任务上的性能和可靠性,从而提升用户体验和降低潜在风险。
📄 摘要(原文)
A key objective of interpretability research on large language models (LLMs) is to develop methods for robustly steering models toward desired behaviors. To this end, two distinct approaches to interpretability --
bottom-up" andtop-down" -- have been presented, but there has been little quantitative comparison between them. We present a case study comparing the effectiveness of representative vector steering methods from each branch: function vectors (FV; arXiv:2310.15213), as a bottom-up method, and in-context vectors (ICV; arXiv:2311.06668) as a top-down method. While both aim to capture compact representations of broad in-context learning tasks, we find they are effective only on specific types of tasks: ICVs outperform FVs in behavioral shifting, whereas FVs excel in tasks requiring more precision. We discuss the implications for future evaluations of steering methods and for further research into top-down and bottom-up steering given these findings.