Optimizing Large Language Models through Quantization: A Comparative Analysis of PTQ and QAT Techniques
作者: Jahid Hasan
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-11-09
备注: 9 pages, 2 figures
💡 一句话要点
通过量化优化大语言模型:PTQ与QAT技术对比分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型量化 训练后量化 量化感知训练 模型压缩 边缘计算 混合精度量化
📋 核心要点
- 现有大语言模型体积庞大,计算资源消耗高,难以在资源受限的设备上部署和应用。
- 论文提出结合训练后量化(PTQ)和量化感知训练(QAT)的量化方案,并引入缩放因子和混合精度量化策略。
- 实验结果表明,该方法能够在显著降低模型大小和计算成本的同时,保持模型性能接近全精度模型。
📝 摘要(中文)
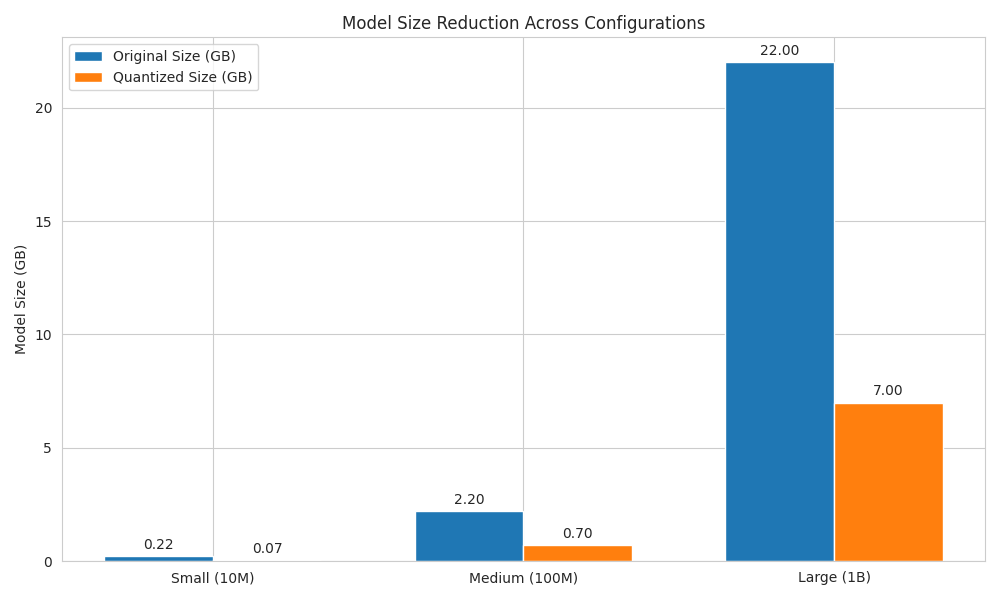
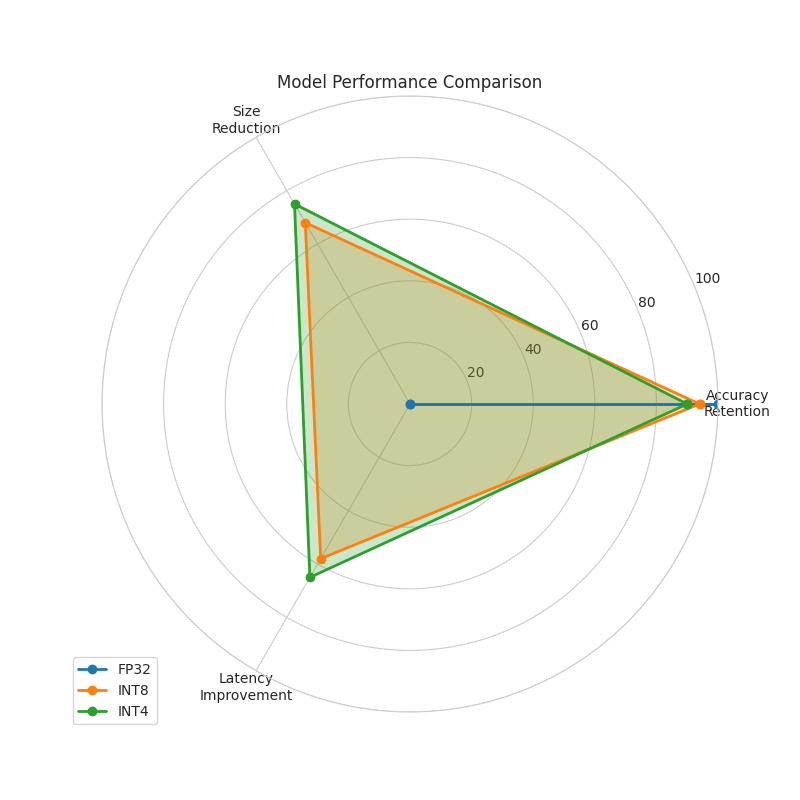
本文全面分析了用于优化大语言模型(LLM)的量化技术,特别关注了训练后量化(PTQ)和量化感知训练(QAT)。通过对参数量从10M到1B的模型进行实证评估,我们证明了在利用我们提出的缩放因子γ时,量化可以实现高达68%的模型大小缩减,同时保持性能在全精度基线的6%以内。我们的实验表明,INT8量化可降低40%的计算成本和功耗,而INT4量化可进一步将这些指标提高60%。我们为混合精度量化引入了一种新的理论框架,基于层敏感性和权重方差推导出最佳比特分配策略。在边缘设备上的硬件效率评估表明,与全精度模型相比,我们的量化方法使INT8的吞吐量提高了2.4倍,INT4的吞吐量提高了3倍,功耗降低了60%。
🔬 方法详解
问题定义:大语言模型参数量巨大,部署和推理需要大量的计算资源和存储空间,尤其是在边缘设备上。现有的全精度模型难以满足资源受限场景的需求,因此需要模型压缩技术。量化是一种有效的模型压缩方法,但如何选择合适的量化策略,在压缩模型的同时保证模型性能是一个挑战。
核心思路:论文的核心思路是通过结合训练后量化(PTQ)和量化感知训练(QAT)的优势,并引入缩放因子γ和混合精度量化策略,在模型大小、计算成本和性能之间取得平衡。PTQ简单易用,但精度损失可能较大;QAT可以提高量化模型的精度,但需要重新训练模型。
技术框架:论文的整体框架包括以下几个阶段:1) 对比分析PTQ和QAT两种量化技术;2) 提出基于缩放因子γ的量化方法,用于调整量化范围;3) 引入混合精度量化策略,根据层敏感性和权重方差动态分配比特数;4) 在不同规模的大语言模型上进行实验评估,验证所提出方法的有效性。
关键创新:论文的关键创新点在于:1) 提出了一个用于混合精度量化的理论框架,可以基于层敏感性和权重方差推导出最佳比特分配策略;2) 引入了缩放因子γ,用于调整量化范围,从而提高量化模型的精度。
关键设计:论文的关键设计包括:1) 缩放因子γ的计算方法,具体计算公式未知;2) 混合精度量化中,层敏感性和权重方差的计算方法,以及如何根据这些指标分配比特数,具体细节未知;3) 实验中使用的具体模型、数据集和评估指标。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法能够在保持模型性能接近全精度模型的前提下,显著降低模型大小和计算成本。具体来说,INT8量化可降低40%的计算成本和功耗,而INT4量化可进一步将这些指标提高60%。在边缘设备上,INT8的吞吐量提高了2.4倍,INT4的吞吐量提高了3倍,功耗降低了60%。模型大小最多可减少68%,性能损失在6%以内。
🎯 应用场景
该研究成果可应用于各种需要部署大语言模型的场景,尤其是在资源受限的边缘设备上,例如智能手机、嵌入式系统和物联网设备。通过量化压缩模型,可以降低计算成本和功耗,提高推理速度,从而实现大语言模型在这些设备上的高效部署和应用。这对于推动人工智能在移动互联网、智能家居和工业自动化等领域的应用具有重要意义。
📄 摘要(原文)
This paper presents a comprehensive analysis of quantization techniques for optimizing Large Language Models (LLMs), specifically focusing on Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT). Through empirical evaluation across models ranging from 10M to 1B parameters, we demonstrate that quantization can achieve up to 68% reduction in model size while maintaining performance within 6% of full-precision baselines when utilizing our proposed scaling factor γ. Our experiments show that INT8 quantization delivers a 40% reduction in computational cost and power consumption, while INT4 quantization further improves these metrics by 60%. We introduce a novel theoretical framework for mixed-precision quantization, deriving optimal bit allocation strategies based on layer sensitivity and weight variance. Hardware efficiency evaluations on edge devices reveal that our quantization approach enables up to 2.4x throughput improvement for INT8 and 3x for INT4, with 60% power reduction compared to full-precision models.