Towards Improved Preference Optimization Pipeline: from Data Generation to Budget-Controlled Regularization
作者: Zhuotong Chen, Fang Liu, Jennifer Zhu, Wanyu Du, Yanjun Qi
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-11-07
备注: 15 pages
💡 一句话要点
提出一种改进的偏好优化流程,通过优化数据生成和预算控制正则化提升LLM对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好优化 大型语言模型 数据生成 正则化 模型对齐 成对排序 奖励模型
📋 核心要点
- DPO等偏好优化方法依赖高质量偏好数据,但现有基于评分的奖励模型生成的数据质量不高,影响LLM对齐。
- 提出迭代成对排序机制生成高质量偏好数据,并设计预算控制正则化,允许模型适当降低偏好样本的可能性。
- 实验表明,结合提出的数据生成和正则化方法,模型在两个基准测试中超越了现有最佳方法。
📝 摘要(中文)
直接偏好优化(DPO)及其变体已成为将大型语言模型(LLM)与人类偏好或特定目标对齐的事实标准。然而,DPO需要高质量的偏好数据,并且存在不稳定的偏好优化问题。本文旨在通过更仔细地研究偏好数据生成和训练正则化技术来改进偏好优化流程。对于偏好数据生成,我们证明了现有的基于评分的奖励模型产生不令人满意的偏好数据,并且在分布外任务上表现不佳。当使用这些数据进行偏好调整时,这会显著影响LLM的对齐性能。为了确保高质量的偏好数据生成,我们提出了一种迭代的成对排序机制,该机制使用成对比较信号来推导补全的偏好排序。对于训练正则化,我们观察到,当LLM预测的偏好样本的可能性略有降低时,偏好优化往往会实现更好的收敛。然而,广泛使用的监督式下一词预测正则化严格地阻止了偏好样本的任何可能性降低。这一观察结果促使我们设计了一种预算控制的正则化公式。经验表明,结合这两种设计可以产生对齐的模型,从而在两个流行的基准测试中超越现有的SOTA。
🔬 方法详解
问题定义:现有直接偏好优化(DPO)方法在将大型语言模型(LLM)与人类偏好对齐时,依赖于高质量的偏好数据。然而,现有的基于评分的奖励模型在生成偏好数据时存在不足,尤其是在分布外任务中表现不佳。此外,常用的监督式下一词预测正则化方法会严格阻止模型降低偏好样本的可能性,这与偏好优化过程中的观察到的现象相悖,即适当降低偏好样本的可能性有助于更好的收敛。
核心思路:本文的核心思路是改进偏好优化流程中的两个关键环节:偏好数据生成和训练正则化。针对偏好数据生成,提出一种迭代的成对排序机制,以生成更准确、更可靠的偏好数据。针对训练正则化,设计一种预算控制的正则化方法,允许模型在一定预算范围内降低偏好样本的可能性,从而促进更好的收敛。
技术框架:该方法包含两个主要组成部分:1) 迭代成对排序的偏好数据生成模块;2) 预算控制的正则化训练模块。首先,使用迭代成对排序机制生成高质量的偏好数据。然后,使用这些数据对LLM进行偏好优化训练,同时应用预算控制的正则化方法。整个流程旨在提高LLM与人类偏好的对齐程度,并提升模型的泛化能力。
关键创新:该方法最重要的技术创新点在于:1) 提出了一种迭代的成对排序机制,用于生成高质量的偏好数据,克服了现有基于评分的奖励模型在数据质量方面的局限性;2) 设计了一种预算控制的正则化方法,允许模型在训练过程中适当降低偏好样本的可能性,从而促进更好的收敛和泛化。
关键设计:在迭代成对排序机制中,关键在于如何有效地利用成对比较信号来推导补全的偏好排序。具体实现细节未知,但可以推测可能涉及到多次迭代,每次迭代都基于前一次迭代的结果进行更精确的排序。在预算控制的正则化方法中,关键在于如何设置预算,以及如何控制模型降低偏好样本可能性的程度。具体实现细节未知,但可以推测可能涉及到对损失函数进行修改,引入一个与预算相关的惩罚项。
🖼️ 关键图片


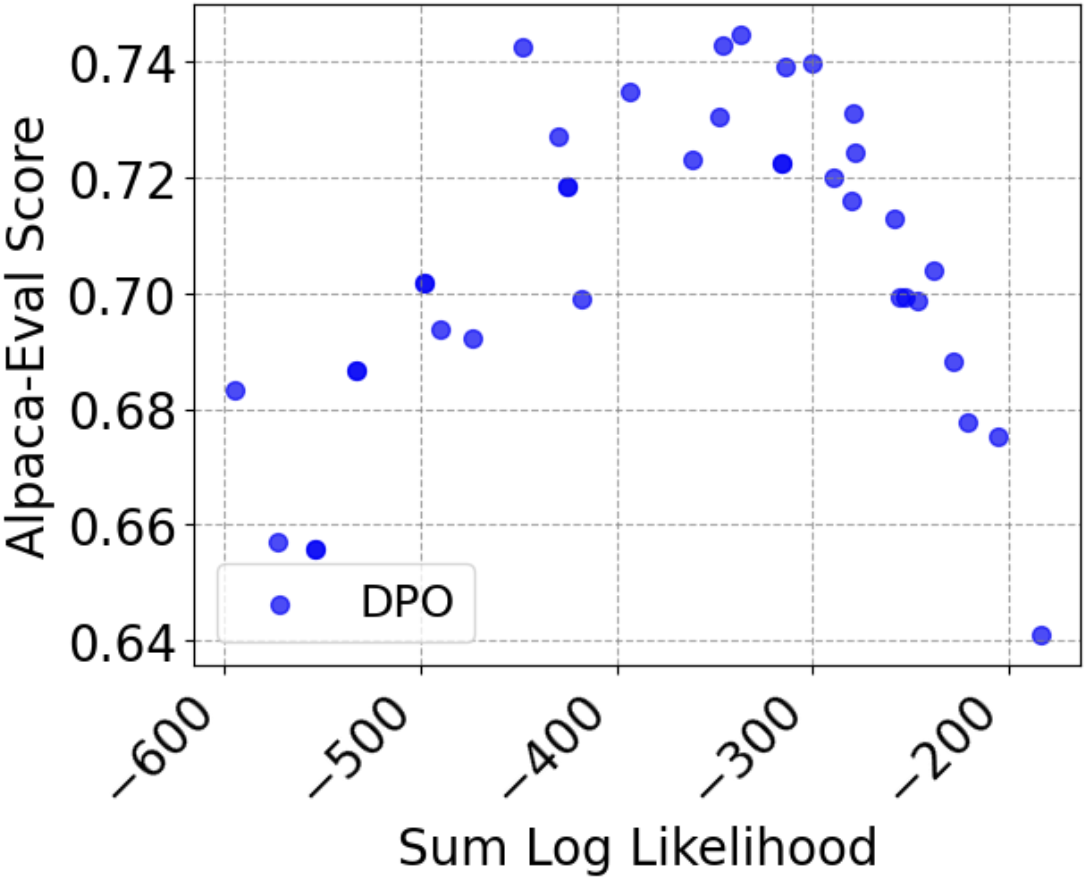
📊 实验亮点
实验结果表明,结合提出的迭代成对排序数据生成方法和预算控制正则化方法,模型在两个流行的基准测试中均超越了现有的SOTA方法。具体的性能数据和提升幅度在论文中未明确给出,但结论表明该方法具有显著的优势。
🎯 应用场景
该研究成果可广泛应用于各种需要将大型语言模型与人类偏好或特定目标对齐的场景,例如对话系统、文本生成、内容推荐等。通过提高LLM的对齐程度,可以提升用户体验,增强模型的实用性和可靠性,并促进人机协作。
📄 摘要(原文)
Direct Preference Optimization (DPO) and its variants have become the de facto standards for aligning large language models (LLMs) with human preferences or specific goals. However, DPO requires high-quality preference data and suffers from unstable preference optimization. In this work, we aim to improve the preference optimization pipeline by taking a closer look at preference data generation and training regularization techniques. For preference data generation, we demonstrate that existing scoring-based reward models produce unsatisfactory preference data and perform poorly on out-of-distribution tasks. This significantly impacts the LLM alignment performance when using these data for preference tuning. To ensure high-quality preference data generation, we propose an iterative pairwise ranking mechanism that derives preference ranking of completions using pairwise comparison signals. For training regularization, we observe that preference optimization tends to achieve better convergence when the LLM predicted likelihood of preferred samples gets slightly reduced. However, the widely used supervised next-word prediction regularization strictly prevents any likelihood reduction of preferred samples. This observation motivates our design of a budget-controlled regularization formulation. Empirically we show that combining the two designs leads to aligned models that surpass existing SOTA across two popular benchmarks.