Exploring How Generative MLLMs Perceive More Than CLIP with the Same Vision Encoder
作者: Siting Li, Pang Wei Koh, Simon Shaolei Du
分类: cs.LG, cs.CL, cs.CV
发布日期: 2024-11-07 (更新: 2025-07-21)
备注: ACL 2025; 19 pages, 3 figures
💡 一句话要点
生成式MLLM利用相同视觉编码器超越CLIP,揭示视觉信息提取的关键架构设计
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 生成式模型 对比学习 视觉推理 架构设计 信息提取 多模态学习
📋 核心要点
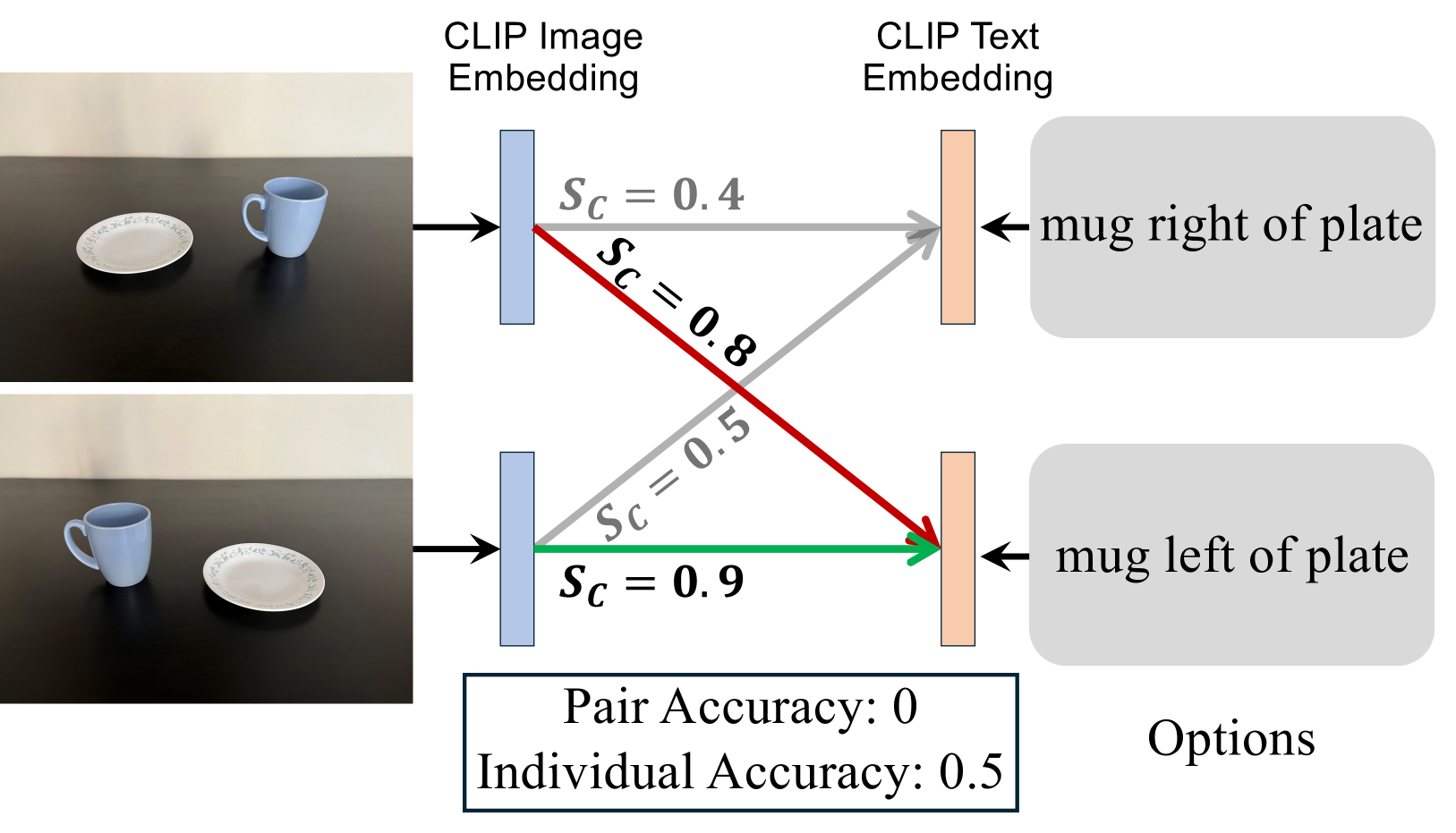
- CLIP在视觉推理任务中存在局限性,并非由于视觉编码器本身缺乏信息,而是信息提取不足。
- 研究表明,生成式MLLM通过特定的架构设计,能够更有效地从相同的视觉编码器中提取视觉信息。
- 实验结果表明,patch tokens、位置嵌入和prompt加权是MLLM优于CLIP的关键因素,而数据增强和更强的文本编码器效果不明显。
📝 摘要(中文)
最近的研究表明,CLIP模型在需要组合性推理、理解空间关系或捕捉细粒度细节的视觉推理任务中表现不佳。一个自然的假设是CLIP视觉编码器没有嵌入这些任务所需的基本信息。然而,本文发现情况并非总是如此:编码器收集了与查询相关的视觉信息,而CLIP未能有效地提取这些信息。具体而言,生成式多模态大型语言模型(MLLM)在使用相同视觉编码器和权重的情况下,在许多此类任务中实现了比CLIP显著更高的准确率,表明这些生成式MLLM能够更有效地提取和利用视觉信息。通过一系列受控实验,揭示了其成功归因于多个关键设计选择,包括patch tokens、位置嵌入和基于prompt的加权。另一方面,仅增强训练数据或应用更强的文本编码器不足以解决该问题,并且额外的文本tokens几乎没有益处。有趣的是,本文发现细粒度的视觉推理并非生成式模型独有:通过对比微调将其转换为类CLIP编码器时,这些MLLM在相同的基于余弦相似度的评估协议下仍然优于CLIP。这项研究强调了VLM架构选择的重要性,并为改进类CLIP对比VLM的性能提供了方向。
🔬 方法详解
问题定义:CLIP模型在视觉推理任务中表现不佳,尤其是在需要组合性、空间关系理解和细粒度细节捕捉的任务中。现有研究认为可能是CLIP的视觉编码器没有包含足够的信息。然而,本文挑战了这一观点,认为CLIP的视觉编码器实际上包含了相关信息,但CLIP本身未能有效提取这些信息。
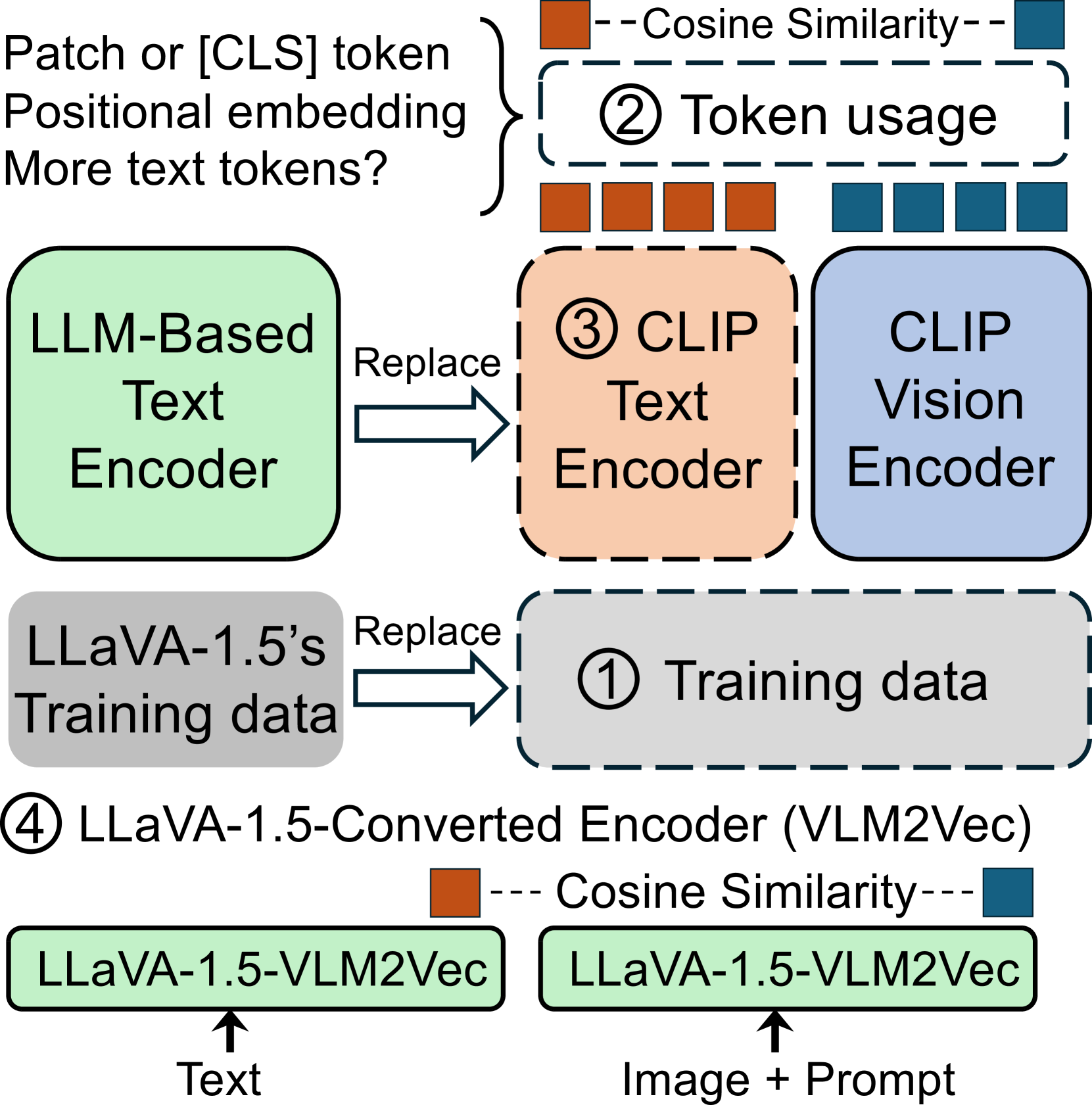
核心思路:本文的核心思路是,通过对比CLIP和生成式MLLM在相同视觉编码器下的表现,来研究MLLM是如何更有效地提取视觉信息的。通过控制变量实验,分析不同的架构设计对视觉信息提取的影响,从而找到提升CLIP性能的关键因素。
技术框架:本文采用对比实验的方法,使用相同的视觉编码器,分别训练CLIP模型和生成式MLLM。然后,在各种视觉推理任务上评估它们的性能。通过消融实验,分析patch tokens、位置嵌入和prompt加权等因素对MLLM性能的影响。最后,将MLLM转换为类CLIP编码器,并进行对比微调,以验证其在对比学习框架下的性能。
关键创新:本文最重要的创新点在于,它揭示了视觉语言模型(VLM)的架构设计,而非视觉编码器本身,是影响视觉信息提取能力的关键因素。通过对比CLIP和生成式MLLM,证明了后者能够更有效地利用相同的视觉编码器中的信息。
关键设计:本文的关键设计包括:1) 使用patch tokens作为视觉输入的表示;2) 引入位置嵌入来编码视觉tokens的空间关系;3) 使用prompt-based weighting来引导模型关注与查询相关的视觉信息。此外,本文还研究了不同的损失函数(对比损失 vs. 自回归损失)和训练数据对模型性能的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,生成式MLLM在使用与CLIP相同的视觉编码器时,在视觉推理任务上的准确率显著高于CLIP。消融实验表明,patch tokens、位置嵌入和prompt加权是MLLM成功的关键因素。即使将MLLM转换为类CLIP编码器,并通过对比微调,其性能仍然优于原始CLIP模型。这些结果表明,VLM的架构设计对视觉信息提取至关重要。
🎯 应用场景
该研究成果可应用于提升各种视觉语言模型的性能,尤其是在需要复杂视觉推理的任务中,例如图像描述生成、视觉问答、目标检测和图像编辑等。通过优化VLM的架构设计,可以使其更好地理解图像内容,从而提高相关应用的准确性和可靠性。此外,该研究也为设计更有效的视觉编码器提供了新的思路。
📄 摘要(原文)
Recent research has shown that CLIP models struggle with visual reasoning tasks that require grounding compositionality, understanding spatial relationships, or capturing fine-grained details. One natural hypothesis is that the CLIP vision encoder does not embed essential information for these tasks. However, we find that this is not always the case: The encoder gathers query-relevant visual information, while CLIP fails to extract it. In particular, we show that another branch of Vision-Language Models (VLMs), Generative Multimodal Large Language Models (MLLMs), achieve significantly higher accuracy than CLIP in many of these tasks using the same vision encoder and weights, indicating that these Generative MLLMs perceive more -- as they extract and utilize visual information more effectively. We conduct a series of controlled experiments and reveal that their success is attributed to multiple key design choices, including patch tokens, position embeddings, and prompt-based weighting. On the other hand, enhancing the training data alone or applying a stronger text encoder does not suffice to solve the task, and additional text tokens offer little benefit. Interestingly, we find that fine-grained visual reasoning is not exclusive to generative models trained by an autoregressive loss: When converted into CLIP-like encoders by contrastive finetuning, these MLLMs still outperform CLIP under the same cosine similarity-based evaluation protocol. Our study highlights the importance of VLM architectural choices and suggests directions for improving the performance of CLIP-like contrastive VLMs.