Interactive Dialogue Agents via Reinforcement Learning on Hindsight Regenerations
作者: Joey Hong, Jessica Lin, Anca Dragan, Sergey Levine
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-11-07
备注: 23 pages, 5 figures
💡 一句话要点
提出基于事后重生的强化学习方法,提升交互式对话Agent在心理健康支持和慈善捐赠场景下的表现。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 交互式对话Agent 强化学习 事后重生 大型语言模型 心理健康支持 慈善捐赠 离线强化学习 对话策略引导
📋 核心要点
- 现有对话Agent难以有效引导对话,尤其是在需要理解人类心理状态的任务中,依赖专家数据成本高昂且效果有限。
- 该论文提出利用LLM的事后分析能力,重写和增强次优对话数据,从而训练出更有效的对话策略。
- 在心理健康支持和慈善捐赠两个领域,通过用户研究验证了该方法显著优于现有对话Agent,提升了交互效果。
📝 摘要(中文)
大型语言模型(LLM)的最新进展使得对话Agent能够生成高度自然和合理的文本。然而,当前的LLM语言生成侧重于用单个有效响应来准确回答问题和请求。实际上,许多真实的对话是交互式的,这意味着Agent的话语会影响他们的对话伙伴,引出信息或改变他们的观点。考虑到Agent如何有效地引导对话是许多对话任务中的关键能力,从医疗保健到偏好引导。现有的微调对话Agent以完成此类任务的方法将依赖于策划一些专家数据。然而,这样做通常需要理解对话伙伴的潜在认知过程,这是人类和在人类数据上训练的LLM都无法可靠地做到的技能。我们的关键见解是,虽然LLM可能不擅长先验地或在正在进行的对话中识别用于引导对话的有效策略,但他们可以在事后,或在事后,在看到他们的对话伙伴如何回应之后这样做。我们使用这个事实来重写和扩充现有的次优数据,并通过离线强化学习(RL)训练一个Agent,该Agent的性能优于提示和从未经修改的人类演示中学习。我们将我们的方法应用于两个需要理解人类精神状态、智能交互和说服的领域:心理健康支持和征集慈善捐款。我们与真实人类的用户研究结果表明,我们的方法大大优于现有的最先进的对话Agent。
🔬 方法详解
问题定义:现有对话Agent在交互式对话中,难以有效引导对话,尤其是在需要理解人类心理状态的任务中,例如心理健康支持和慈善捐赠。现有方法依赖于大量专家数据,但专家数据难以获取,且人类或LLM难以准确理解对话伙伴的认知过程,导致Agent无法学习到有效的对话策略。
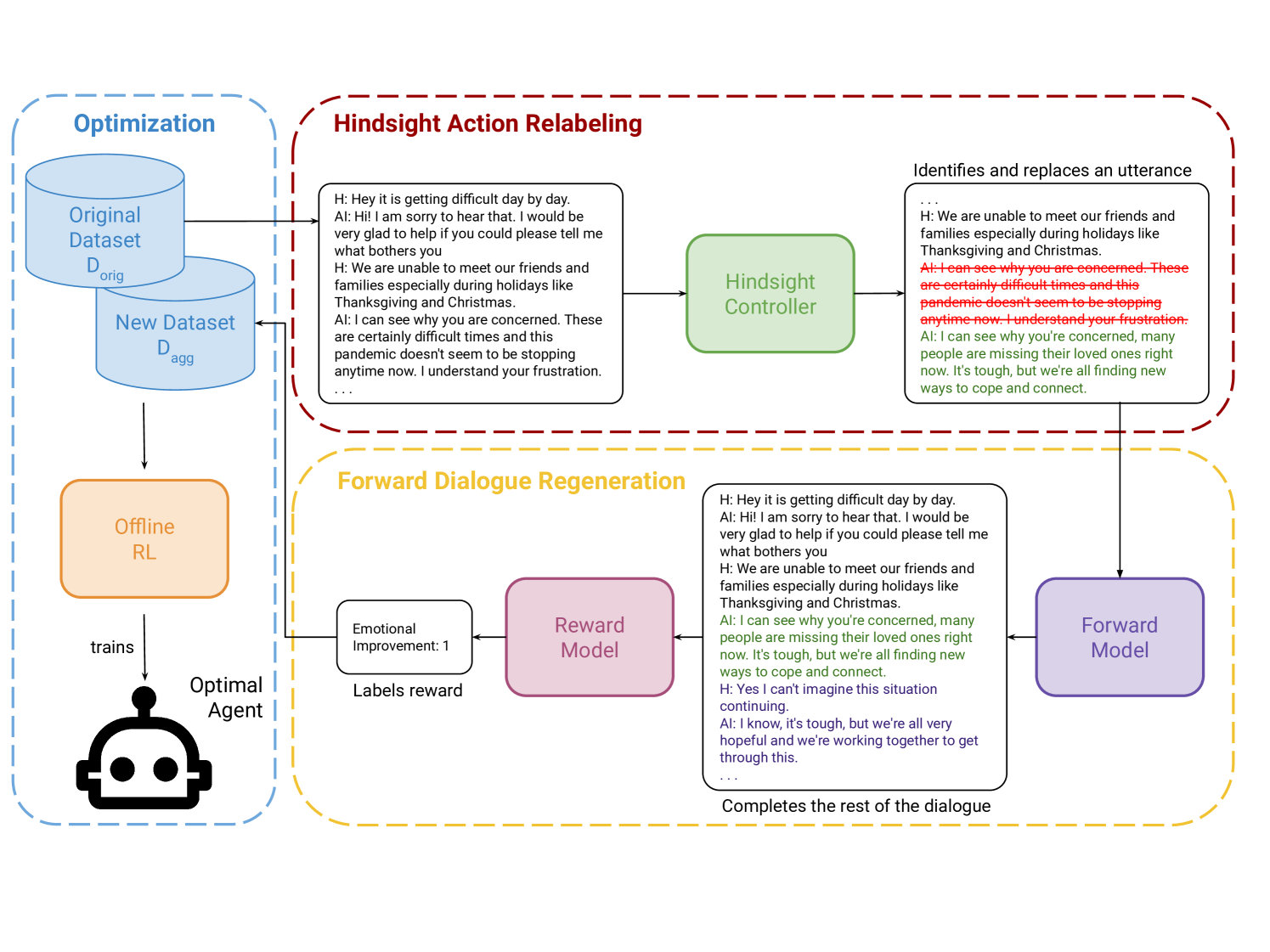
核心思路:利用LLM在事后分析方面的优势。虽然LLM可能无法事先或在对话过程中识别有效的引导策略,但它们可以在事后,即在观察到对话伙伴的反应后,更好地判断哪些策略是有效的。基于此,对次优的对话数据进行重写和增强,从而为Agent提供更好的训练数据。
技术框架:该方法采用离线强化学习(RL)框架。首先,收集或生成初始对话数据。然后,利用LLM对这些数据进行事后分析,重写和增强次优的对话轮次,生成新的训练数据集。最后,使用离线RL算法,如Q-learning或Actor-Critic方法,在增强后的数据集上训练对话Agent。
关键创新:该方法的核心创新在于利用LLM的事后分析能力来改进训练数据。与传统的依赖专家数据或直接从人类数据学习的方法不同,该方法通过LLM的“反思”来发现更有效的对话策略,从而克服了人类或LLM难以准确理解对话伙伴认知过程的难题。
关键设计:关键设计包括:1) 如何设计LLM的prompt,使其能够有效地进行事后分析和数据重写;2) 如何选择合适的离线RL算法,以充分利用增强后的数据集;3) 如何平衡原始数据和增强数据,避免过度拟合LLM的偏见;4) 损失函数的设计需要考虑对话的长期回报,例如是否成功引导对话伙伴改变观点或采取行动。
🖼️ 关键图片

📊 实验亮点
在心理健康支持和慈善捐赠两个领域的实验结果表明,该方法显著优于现有的对话Agent。具体来说,在用户研究中,使用该方法训练的Agent在引导用户改变观点或采取行动方面的成功率明显高于基线方法,例如直接prompt LLM或使用未经修改的人类数据进行训练的Agent。具体的性能提升数据未知,但用户研究结果表明该方法具有显著的优势。
🎯 应用场景
该研究成果可广泛应用于需要智能交互和说服的对话场景,例如在线心理咨询、客户服务、销售谈判、教育辅导等。通过提升对话Agent的引导能力,可以更有效地帮助用户解决问题、达成目标,并改善用户体验。未来,该方法有望应用于更复杂的对话任务,例如多轮对话、个性化对话等。
📄 摘要(原文)
Recent progress on large language models (LLMs) has enabled dialogue agents to generate highly naturalistic and plausible text. However, current LLM language generation focuses on responding accurately to questions and requests with a single effective response. In reality, many real dialogues are interactive, meaning an agent's utterances will influence their conversational partner, elicit information, or change their opinion. Accounting for how an agent can effectively steer a conversation is a crucial ability in many dialogue tasks, from healthcare to preference elicitation. Existing methods for fine-tuning dialogue agents to accomplish such tasks would rely on curating some amount of expert data. However, doing so often requires understanding the underlying cognitive processes of the conversational partner, which is a skill neither humans nor LLMs trained on human data can reliably do. Our key insight is that while LLMs may not be adept at identifying effective strategies for steering conversations a priori, or in the middle of an ongoing conversation, they can do so post-hoc, or in hindsight, after seeing how their conversational partner responds. We use this fact to rewrite and augment existing suboptimal data, and train via offline reinforcement learning (RL) an agent that outperforms both prompting and learning from unaltered human demonstrations. We apply our approach to two domains that require understanding human mental state, intelligent interaction, and persuasion: mental health support, and soliciting charitable donations. Our results in a user study with real humans show that our approach greatly outperforms existing state-of-the-art dialogue agents.