Q-SFT: Q-Learning for Language Models via Supervised Fine-Tuning
作者: Joey Hong, Anca Dragan, Sergey Levine
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-11-07 (更新: 2024-11-27)
备注: 17 pages, 4 figures
💡 一句话要点
提出Q-SFT算法,将Q学习转化为监督微调,提升语言模型在多轮强化学习任务中的性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Q学习 强化学习 语言模型 监督微调 离线强化学习
📋 核心要点
- 现有基于价值的强化学习方法难以扩展到大型语言模型的多轮任务,无法有效利用预训练的优势。
- Q-SFT将Q学习转化为监督微调问题,token概率直接对应Q值,实现从预训练到Q函数学习的平滑过渡。
- 实验表明,Q-SFT在自然语言对话和机器人操作等任务上表现出色,无需重新初始化权重或添加额外模块。
📝 摘要(中文)
基于价值的强化学习原则上可以为各种多轮问题学习有效的策略,从游戏到对话再到机器人控制,包括通过静态的先前收集的数据集进行离线强化学习。然而,尽管策略梯度方法被广泛用于训练大型语言模型以完成单轮任务(例如,问答),但基于价值的方法在离线或离线设置中用于多轮强化学习已被证明特别难以扩展到大型语言模型的设置。这种设置需要有效地利用预训练,扩展到具有数十亿参数的大型架构,并在大型数据集上进行训练,所有这些都代表了当前基于价值的强化学习方法的主要挑战。在这项工作中,我们提出了一种新颖的离线强化学习算法,该算法解决了这些缺点,将Q学习转化为一种改进的监督微调(SFT)问题,其中token的概率直接转化为Q值。通过这种方式,我们获得了一种算法,该算法可以从预训练期间最大化数据的可能性平滑过渡到微调期间学习接近最优的Q函数。我们的算法具有强大的理论基础,享有与最先进的Q学习方法类似的性能界限,同时在实践中利用了与SFT非常相似的目标。因此,我们的方法可以享受语言模型预训练的全部好处,而无需在强化学习微调之前重新初始化任何权重,也无需初始化新的头来预测值或优势。在经验上,我们在预训练的LLM和VLM上评估了我们的方法,在各种任务上,包括自然语言对话以及来自图像的机器人操作和导航。
🔬 方法详解
问题定义:现有基于价值的强化学习方法在应用于大型语言模型的多轮任务时,面临着扩展性挑战。这些方法难以有效利用预训练语言模型的知识,需要重新初始化权重或添加额外的网络模块,导致训练效率低下,性能提升有限。此外,离线强化学习场景下,如何从静态数据集中学习有效的Q函数也是一个难题。
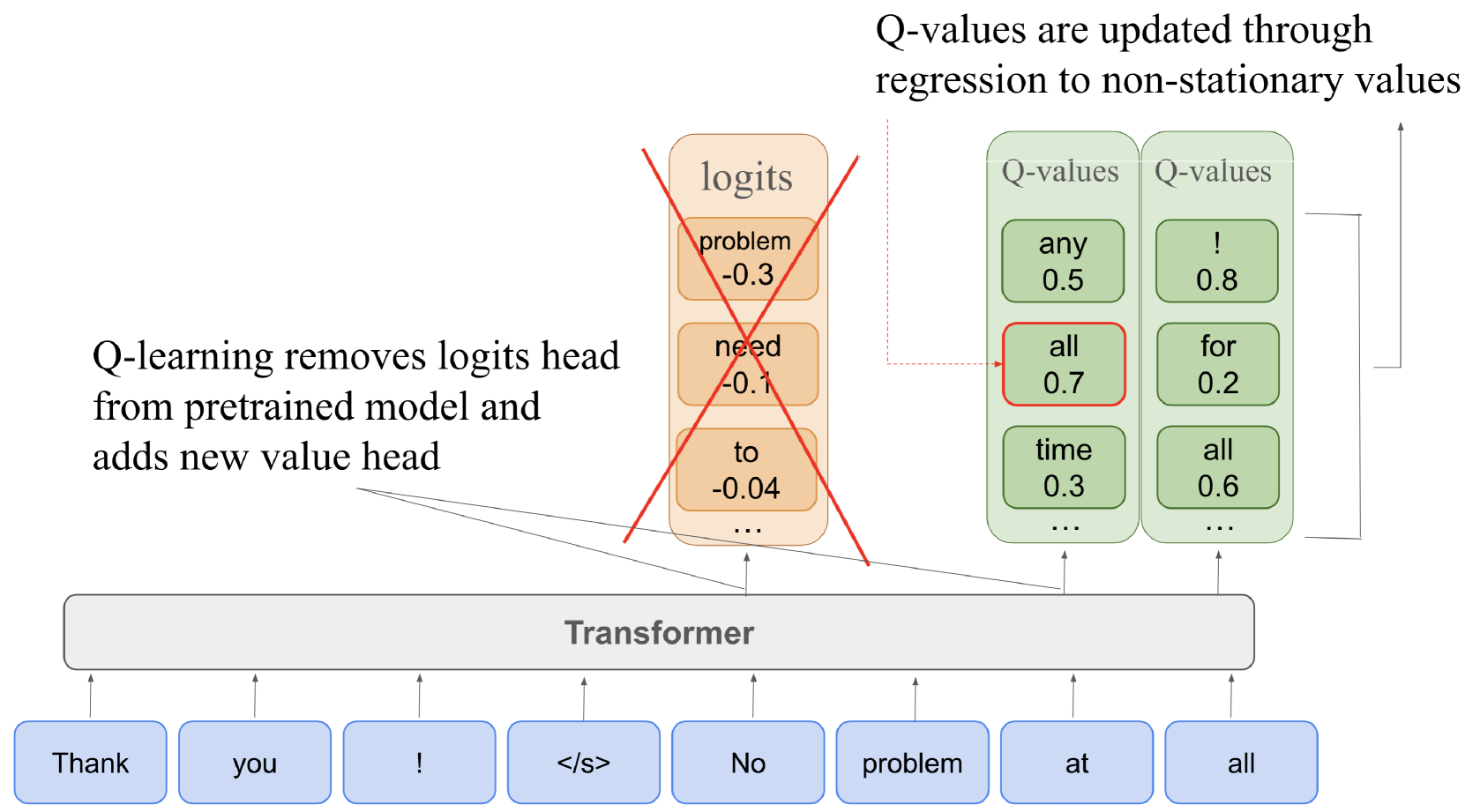
核心思路:Q-SFT的核心思路是将Q学习问题转化为一个监督微调(SFT)问题。通过将语言模型输出的token概率直接映射为Q值,Q-SFT能够利用预训练语言模型的强大表示能力,并避免了重新初始化权重或添加额外模块的需求。这种方法使得Q学习过程可以无缝地融入到语言模型的微调过程中,从而实现高效的离线强化学习。
技术框架:Q-SFT的整体框架包括以下几个主要阶段:1) 数据收集:收集包含状态、动作和奖励的离线数据集。2) 预训练:使用大规模语料库对语言模型进行预训练,获得强大的语言表示能力。3) Q-SFT微调:使用离线数据集,将Q学习目标转化为监督学习目标,通过微调语言模型来学习Q函数。在微调过程中,token的概率被直接解释为Q值,模型的目标是最大化期望累积奖励。
关键创新:Q-SFT最重要的技术创新点在于将Q学习问题转化为监督微调问题。与传统的Q学习方法相比,Q-SFT无需显式地估计Q值,而是通过语言模型的token概率来隐式地表示Q值。这种方法避免了传统Q学习方法中的值函数近似误差,并能够充分利用预训练语言模型的知识。此外,Q-SFT还具有良好的理论性质,其性能界限与最先进的Q学习方法相当。
关键设计:Q-SFT的关键设计包括:1) Q值映射:将语言模型输出的token概率通过一个函数映射为Q值。这个函数可以是简单的线性变换,也可以是更复杂的非线性函数。2) 损失函数:使用交叉熵损失函数来训练语言模型,目标是最大化期望累积奖励。3) 探索策略:在离线强化学习场景下,需要使用合适的探索策略来保证数据集的多样性。常用的探索策略包括ε-greedy策略和Boltzmann策略。
🖼️ 关键图片
📊 实验亮点
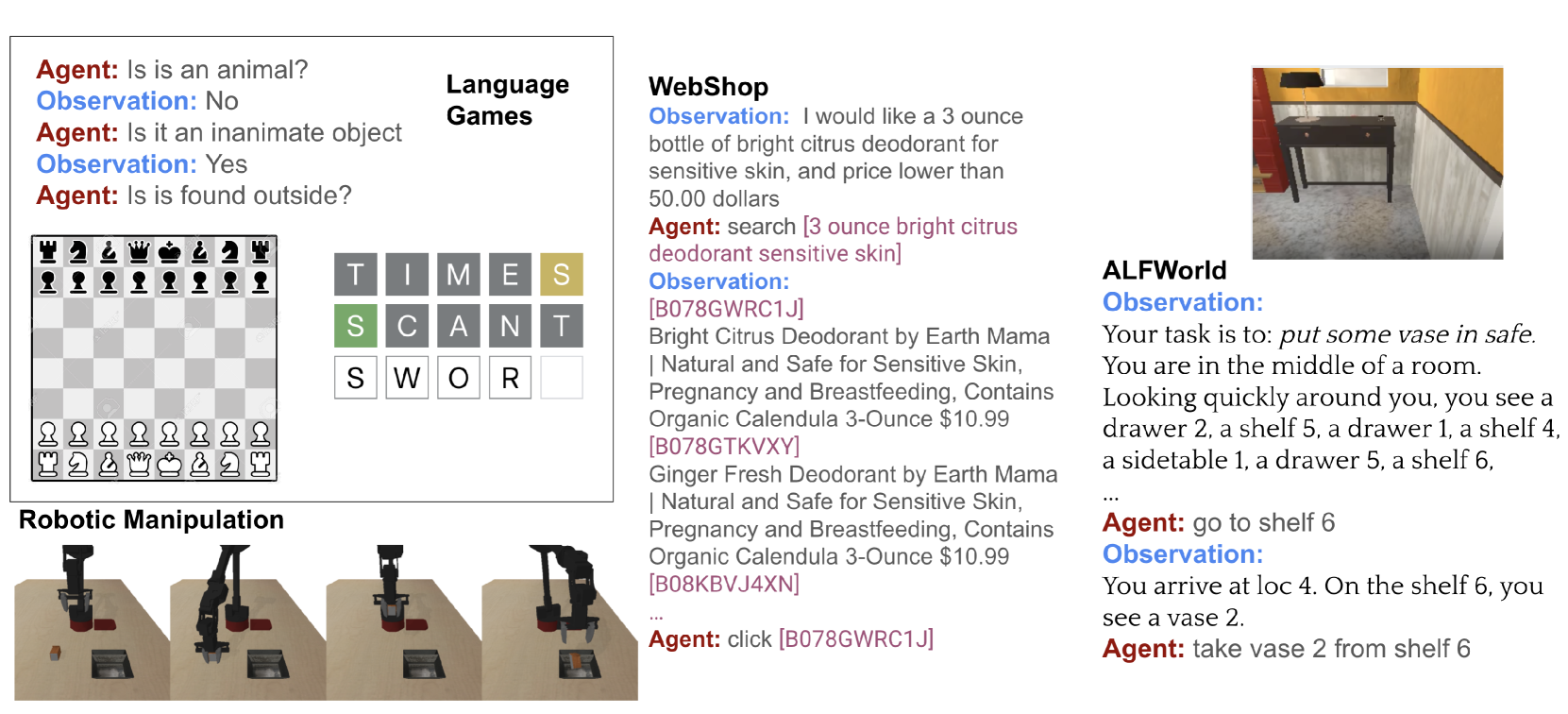
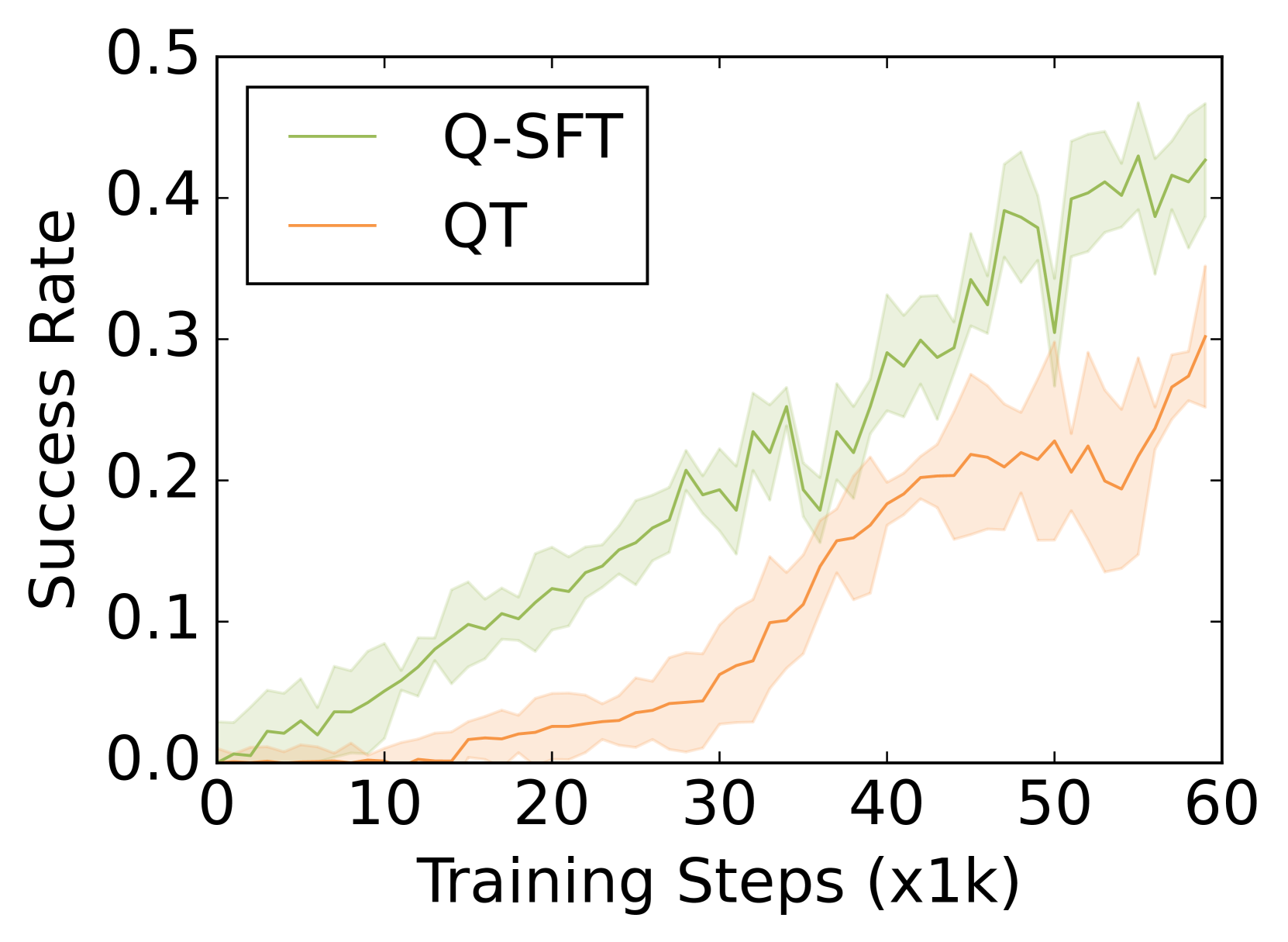
Q-SFT在自然语言对话和机器人操作等任务上取得了显著的性能提升。实验结果表明,Q-SFT能够有效地利用预训练语言模型的知识,并学习到接近最优的Q函数。与传统的Q学习方法相比,Q-SFT在样本效率和性能方面均具有优势。此外,Q-SFT还具有良好的泛化能力,能够适应不同的任务和环境。
🎯 应用场景
Q-SFT具有广泛的应用前景,可以应用于自然语言对话、机器人控制、游戏等领域。在自然语言对话中,Q-SFT可以用于训练对话策略,提高对话的流畅性和信息量。在机器人控制中,Q-SFT可以用于学习机器人的运动规划策略,提高机器人的自主性和适应性。此外,Q-SFT还可以应用于游戏AI的开发,提高游戏AI的智能水平。
📄 摘要(原文)
Value-based reinforcement learning (RL) can in principle learn effective policies for a wide range of multi-turn problems, from games to dialogue to robotic control, including via offline RL from static previously collected datasets. However, despite the widespread use of policy gradient methods to train large language models for single turn tasks (e.g., question answering), value-based methods for multi-turn RL in an off-policy or offline setting have proven particularly challenging to scale to the setting of large language models. This setting requires effectively leveraging pretraining, scaling to large architectures with billions of parameters, and training on large datasets, all of which represent major challenges for current value-based RL methods. In this work, we propose a novel offline RL algorithm that addresses these drawbacks, casting Q-learning as a modified supervised fine-tuning (SFT) problem where the probabilities of tokens directly translate to Q-values. In this way we obtain an algorithm that smoothly transitions from maximizing the likelihood of the data during pretraining to learning a near-optimal Q-function during finetuning. Our algorithm has strong theoretical foundations, enjoying performance bounds similar to state-of-the-art Q-learning methods, while in practice utilizing an objective that closely resembles SFT. Because of this, our approach can enjoy the full benefits of the pretraining of language models, without the need to reinitialize any weights before RL finetuning, and without the need to initialize new heads for predicting values or advantages. Empirically, we evaluate our method on both pretrained LLMs and VLMs, on a variety of tasks including both natural language dialogue and robotic manipulation and navigation from images.