Benchmarking Large Language Models with Integer Sequence Generation Tasks
作者: Daniel O'Malley, Manish Bhattarai, Nishath Rajiv Ranasinghe, Erick Draayer, Javier Santos
分类: cs.LG, cs.AI, cs.SE
发布日期: 2024-11-07 (更新: 2025-11-08)
💡 一句话要点
提出整数序列生成基准,评估大语言模型在数学推理和代码合成中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数学推理 代码合成 整数序列 算法评估
📋 核心要点
- 现有LLM在数学推理和算法代码生成方面能力不足,缺乏系统性的评估基准。
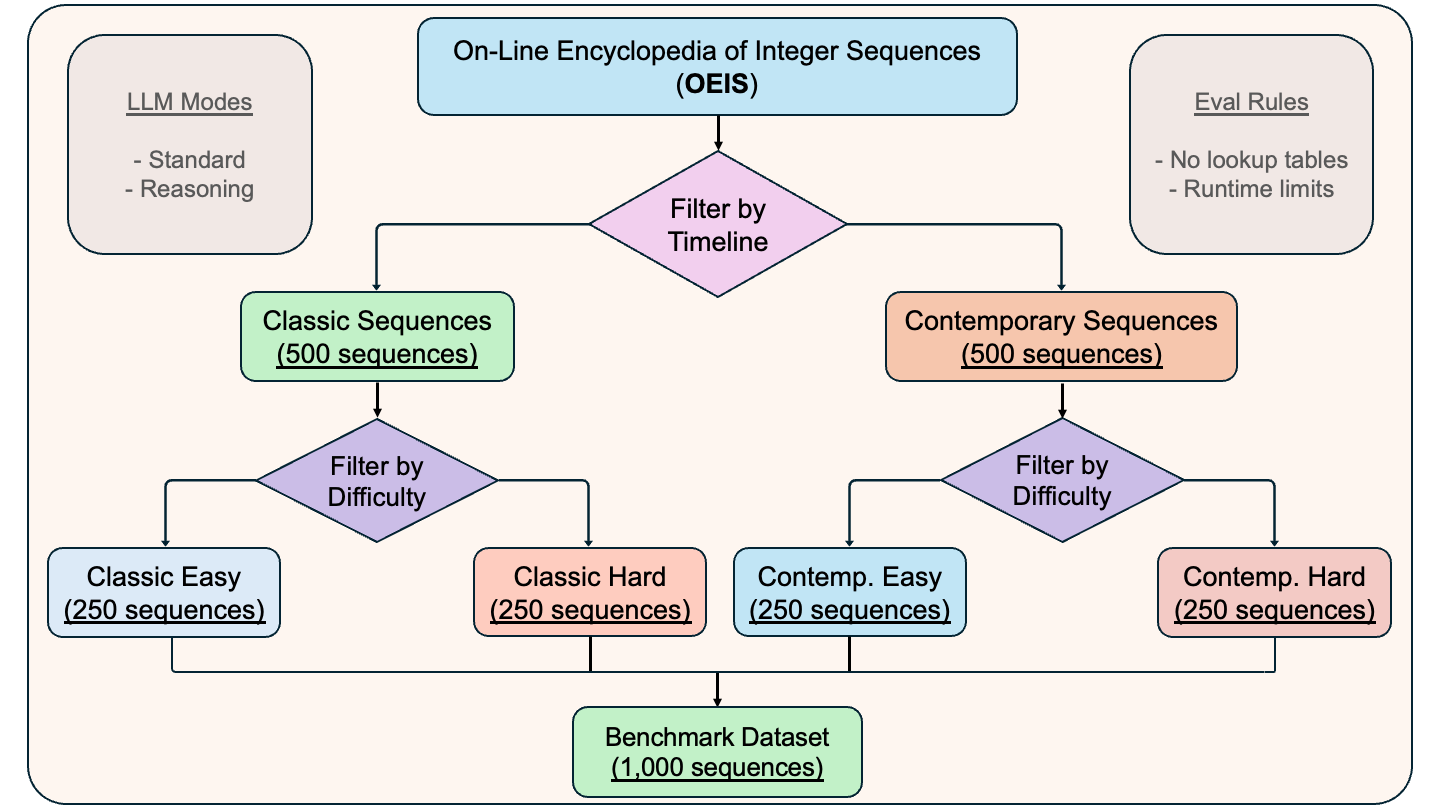
- 构建基于OEIS的整数序列生成任务基准,要求LLM生成Python代码而非查找表。
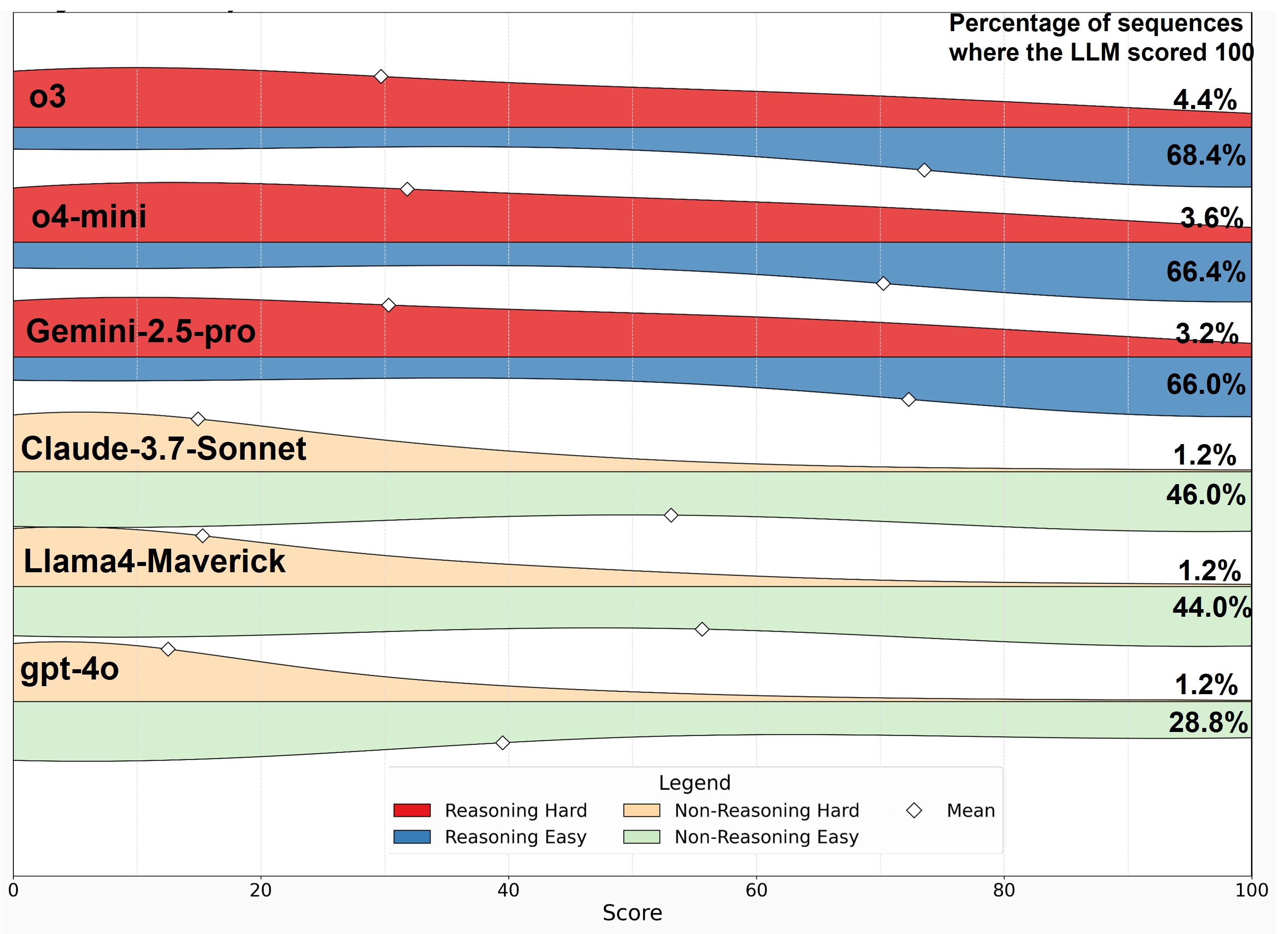
- 实验表明,推理专用模型在复杂任务上表现更优,但整体性能仍有提升空间。
📝 摘要(中文)
本文提出了一种新的基准,旨在严格评估大型语言模型(LLM)在数学推理和算法代码合成方面的能力。该基准包含来自整数数列线上大全(OEIS)的整数序列生成任务,测试LLM在不使用查找表的情况下,准确有效地生成Python代码来计算这些序列的能力。我们对来自OpenAI(包括专门针对推理的o系列)、Anthropic、Meta和Google的领先模型进行了全面评估,使用了精心挑选的1000个OEIS序列,这些序列被分为“简单”或“困难”两类。其中一半是OEIS早期的经典序列,另一半是最近添加的,以避免与模型的训练数据发生污染。为了防止模型利用记忆的序列值,我们引入了一种自动作弊检测机制,该机制可以标记查找表的使用,并通过与人类专家评估的比较进行验证。实验结果表明,专门用于推理的模型(OpenAI的o3、o3-mini、o4-mini和Google的Gemini 2.5-pro)在准确性方面比非推理模型有了显著提高,尤其是在更复杂的任务上。然而,总体而言,模型在困难序列上的表现较差,突显了算法推理方面仍然存在的挑战。我们的基准为最先进的LLM的优势和局限性提供了重要的见解,特别强调了需要进一步发展,以可靠地以算法方式解决复杂的数学推理任务。
🔬 方法详解
问题定义:论文旨在评估大型语言模型在数学推理和算法代码合成方面的能力。现有方法主要依赖于通用语言模型的预训练和微调,缺乏针对数学推理的专门设计和评估。此外,模型可能通过记忆训练数据来解决问题,而非进行真正的算法推理。
核心思路:论文的核心思路是利用整数序列生成任务来测试LLM的算法推理能力。通过要求模型生成Python代码来计算序列,而非简单地查找或记忆序列值,可以更有效地评估其推理能力。OEIS提供了丰富的整数序列资源,可以构建具有不同难度和复杂度的测试用例。
技术框架:该研究的技术框架主要包括以下几个部分:1) 从OEIS中选取1000个整数序列,分为“简单”和“困难”两类。2) 要求LLM生成Python代码来计算这些序列。3) 引入自动作弊检测机制,以识别模型是否使用了查找表。4) 对比不同LLM在序列生成任务上的性能,并分析其优势和局限性。
关键创新:该研究的关键创新在于提出了一个专门用于评估LLM数学推理能力的基准。该基准基于OEIS的整数序列,并引入了自动作弊检测机制,可以更准确地评估模型的算法推理能力。此外,该研究还对多个主流LLM进行了全面评估,为后续研究提供了重要的参考。
关键设计:为了防止模型使用查找表,研究者设计了自动作弊检测机制。该机制通过分析模型生成的代码,判断其是否使用了预先存储的序列值。此外,研究者还精心挑选了OEIS序列,包括经典序列和最近添加的序列,以避免模型过度拟合训练数据。序列难度分为“简单”和“困难”两类,以便更全面地评估模型的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,专门用于推理的模型(如OpenAI的o3、o3-mini、o4-mini和Google的Gemini 2.5-pro)在准确性方面比非推理模型有了显著提高,尤其是在更复杂的任务上。然而,总体而言,模型在困难序列上的表现较差,表明LLM在算法推理方面仍面临挑战。具体性能数据未知,但推理专用模型在困难序列上的提升幅度显著。
🎯 应用场景
该研究成果可应用于评估和提升LLM在数学、科学和工程领域的应用能力。通过该基准,可以更好地了解LLM的优势和局限性,并指导模型的设计和训练,使其能够更可靠地解决复杂的算法推理问题。此外,该研究还可以促进LLM在自动化代码生成、数学问题求解等领域的应用。
📄 摘要(原文)
We present a novel benchmark designed to rigorously evaluate the capabilities of large language models (LLMs) in mathematical reasoning and algorithmic code synthesis tasks. The benchmark comprises integer sequence generation tasks sourced from the Online Encyclopedia of Integer Sequences (OEIS), testing LLMs' abilities to accurately and efficiently generate Python code to compute these sequences without using lookup tables. Our comprehensive evaluation includes leading models from OpenAI (including the specialized reasoning-focused o-series), Anthropic, Meta, and Google across a carefully selected set of 1000 OEIS sequences categorized as
easy'' orhard.'' Half of these sequences are classical sequences from the early days of OEIS and half were recently added to avoid contamination with the models' training data. To prevent models from exploiting memorized sequence values, we introduce an automated cheating detection mechanism that flags usage of lookup tables, validated by comparison with human expert evaluations. Experimental results demonstrate that reasoning-specialized models (o3, o3-mini, o4-mini from OpenAI, and Gemini 2.5-pro from Google) achieve substantial improvements in accuracy over non-reasoning models, especially on more complex tasks. However, overall model performance on the hard sequences is poor, highlighting persistent challenges in algorithmic reasoning. Our benchmark provides important insights into the strengths and limitations of state-of-the-art LLMs, particularly emphasizing the necessity for further advancements to reliably solve complex mathematical reasoning tasks algorithmically.