A Implies B: Circuit Analysis in LLMs for Propositional Logical Reasoning
作者: Guan Zhe Hong, Nishanth Dikkala, Enming Luo, Cyrus Rashtchian, Xin Wang, Rina Panigrahy
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-11-06 (更新: 2025-06-19)
💡 一句话要点
利用LLM电路分析揭示命题逻辑推理机制,发现模块化子电路。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 逻辑推理 电路分析 机制可解释性 因果中介分析
📋 核心要点
- 大型语言模型的推理机制复杂且难以理解,现有方法难以定位推理过程的关键组成部分。
- 该论文通过研究命题逻辑问题,利用因果中介分析揭示LLM推理过程中的路径和组件。
- 研究发现LLM中存在稀疏电路,可分解为具有模块化用途的子电路,且不同模型间存在相似但非完全相同的机制。
📝 摘要(中文)
由于大型语言模型(LLM)的规模和复杂性,揭示模型用于解决推理问题的底层机制极具挑战。例如,针对特定问题的推理是否局限于网络的某些部分?模型是否将推理问题分解为模块化组件,并在模型中逐步执行?为了更好地理解LLM的推理能力,我们研究了一个最小的命题逻辑问题,该问题需要组合多个事实才能得出解决方案。通过在Mistral和Gemma模型(参数高达27B)上研究这个问题,我们阐明了模型用于解决此类逻辑问题的核心组件。从机制可解释性的角度来看,我们使用因果中介分析来揭示LLM推理过程的路径和组件。然后,我们提供了对不同层中注意力头功能的细粒度见解。我们不仅发现了一个计算答案的稀疏电路,而且将其分解为具有四个不同和模块化用途的子电路。最后,我们揭示了三个不同的模型——Mistral-7B、Gemma-2-9B和Gemma-2-27B——包含类似但不相同的机制。
🔬 方法详解
问题定义:论文旨在理解大型语言模型(LLM)如何进行逻辑推理,特别是命题逻辑推理。现有方法难以揭示LLM内部的推理机制,例如推理过程是否模块化、关键组件位于何处等。这阻碍了我们对LLM推理能力的深入理解和改进。
核心思路:论文的核心思路是通过研究一个最小的命题逻辑问题,利用机制可解释性方法(如因果中介分析)来揭示LLM推理过程中的关键路径和组件。通过分析LLM内部的“电路”,理解其如何组合多个事实以得出结论。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择命题逻辑问题作为研究对象。2) 在Mistral和Gemma等LLM上进行实验。3) 使用因果中介分析来识别LLM推理过程中的关键路径和组件。4) 分析不同层中注意力头的功能。5) 将推理电路分解为模块化的子电路。
关键创新:该论文的关键创新在于:1) 使用电路分析的方法来研究LLM的推理机制。2) 发现LLM中存在稀疏电路,可以计算命题逻辑问题的答案。3) 将该电路分解为具有模块化用途的子电路,揭示了LLM推理过程的模块化特性。4) 比较了不同模型(Mistral-7B、Gemma-2-9B和Gemma-2-27B)之间的推理机制,发现它们之间存在相似但非完全相同的结构。
关键设计:论文的关键设计包括:1) 选择合适的命题逻辑问题,使其既能体现推理能力,又具有一定的复杂度。2) 使用因果中介分析,这是一种用于识别因果关系的统计方法,可以有效地揭示LLM推理过程中的关键路径。3) 对注意力头进行细粒度分析,以理解它们在推理过程中的具体作用。4) 将推理电路分解为子电路,这有助于理解LLM推理过程的模块化特性。具体的参数设置、损失函数、网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
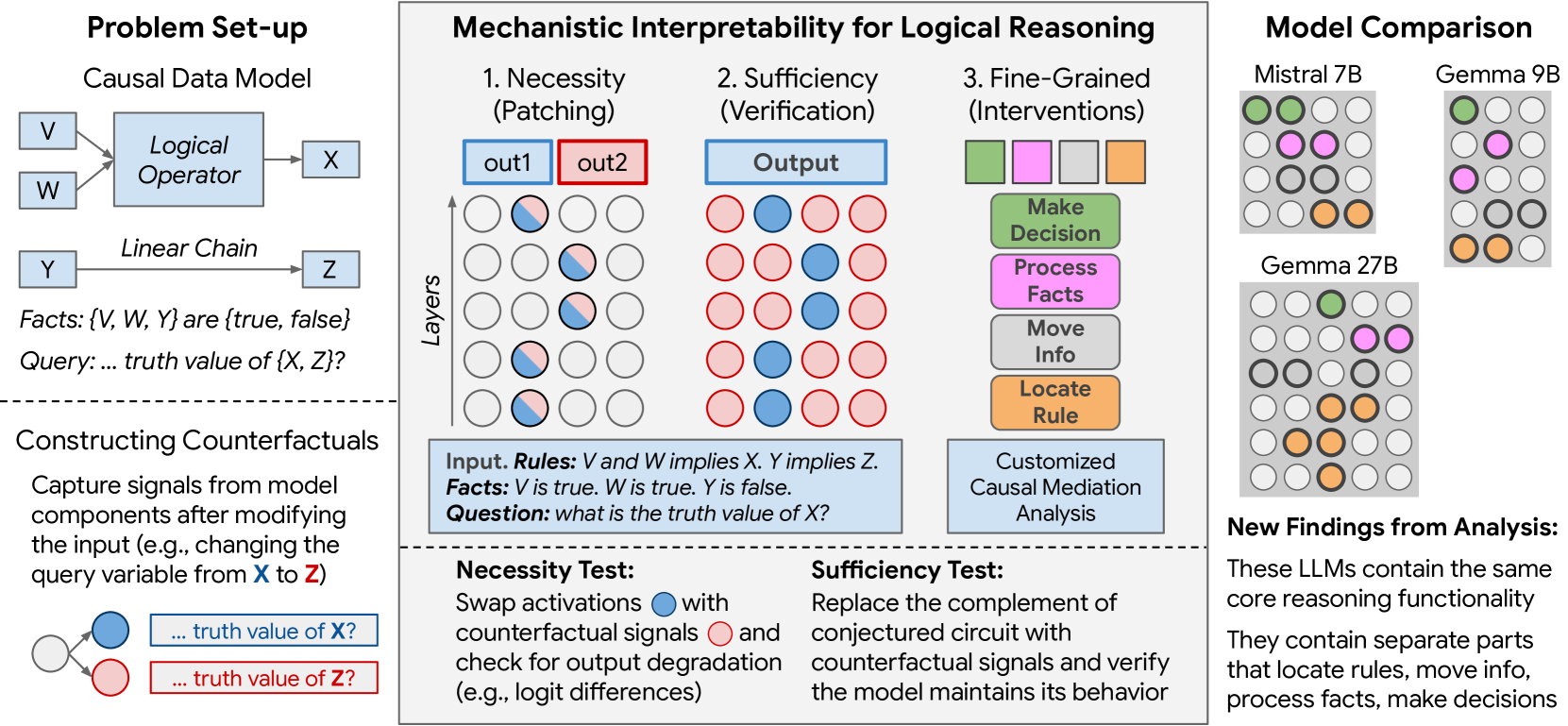
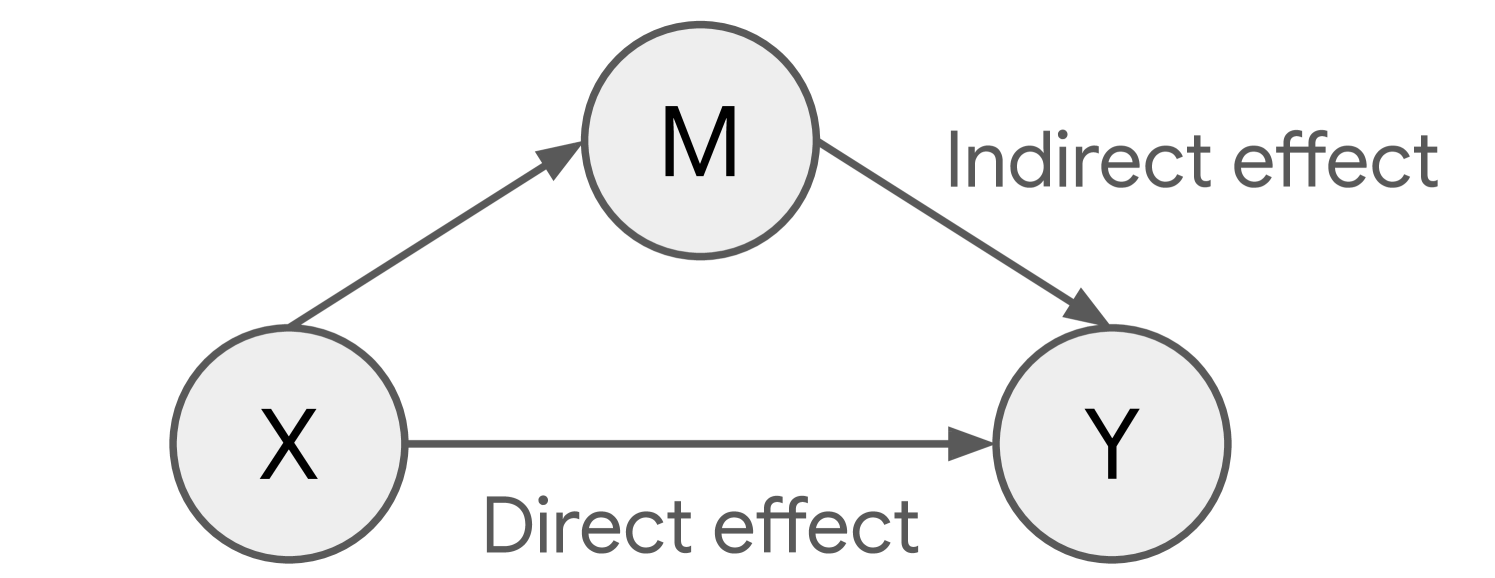
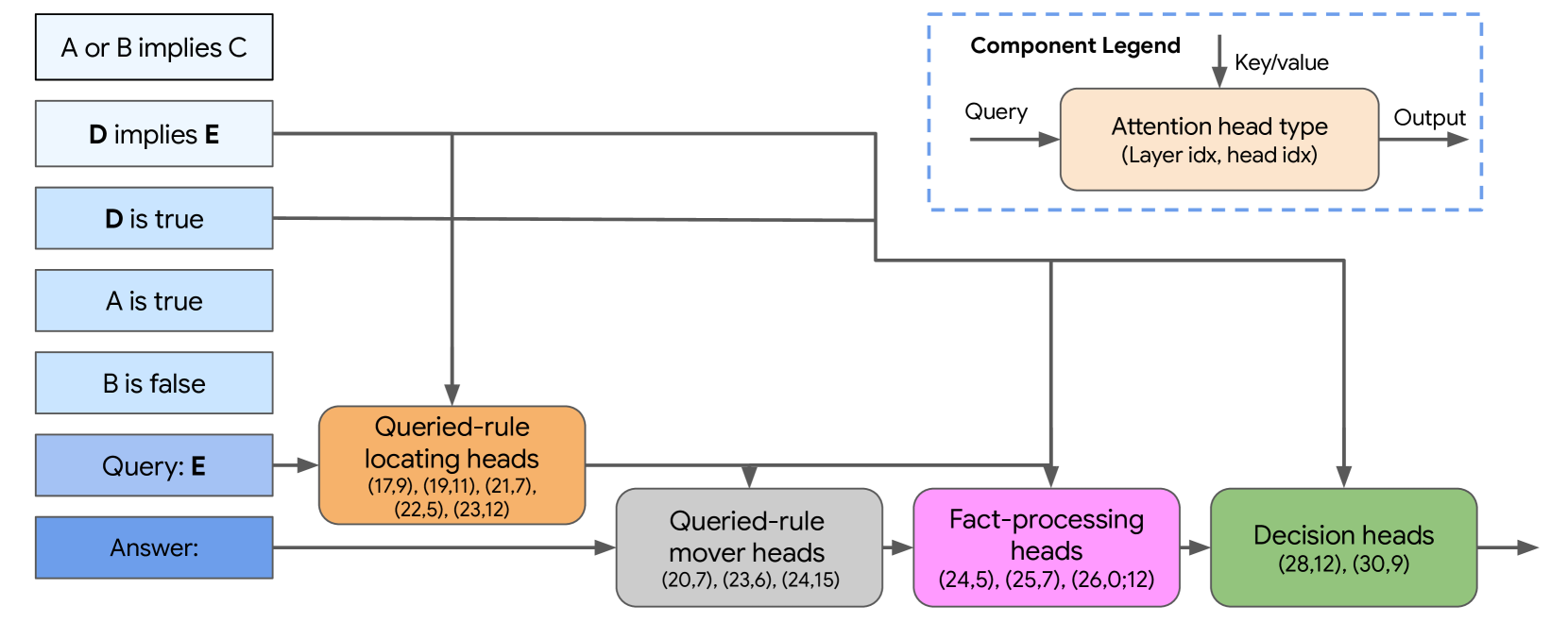
📊 实验亮点
研究发现,LLM中存在用于解决命题逻辑问题的稀疏电路,并且该电路可以分解为具有四个不同和模块化用途的子电路。此外,研究还揭示了Mistral-7B、Gemma-2-9B和Gemma-2-27B等不同模型之间存在相似但非完全相同的推理机制。
🎯 应用场景
该研究成果可应用于提升LLM的可解释性和可靠性。通过理解LLM的推理机制,可以更好地诊断和修复其推理错误,并开发更高效、更可控的LLM。此外,该方法还可以推广到其他类型的推理问题,促进通用人工智能的发展。
📄 摘要(原文)
Due to the size and complexity of modern large language models (LLMs), it has proven challenging to uncover the underlying mechanisms that models use to solve reasoning problems. For instance, is their reasoning for a specific problem localized to certain parts of the network? Do they break down the reasoning problem into modular components that are then executed as sequential steps as we go deeper in the model? To better understand the reasoning capability of LLMs, we study a minimal propositional logic problem that requires combining multiple facts to arrive at a solution. By studying this problem on Mistral and Gemma models, up to 27B parameters, we illuminate the core components the models use to solve such logic problems. From a mechanistic interpretability point of view, we use causal mediation analysis to uncover the pathways and components of the LLMs' reasoning processes. Then, we offer fine-grained insights into the functions of attention heads in different layers. We not only find a sparse circuit that computes the answer, but we decompose it into sub-circuits that have four distinct and modular uses. Finally, we reveal that three distinct models -- Mistral-7B, Gemma-2-9B and Gemma-2-27B -- contain analogous but not identical mechanisms.