A Bayesian Approach to Data Point Selection
作者: Xinnuo Xu, Minyoung Kim, Royson Lee, Brais Martinez, Timothy Hospedales
分类: cs.LG
发布日期: 2024-11-06
💡 一句话要点
提出一种基于贝叶斯推断的数据点选择方法,提升深度学习训练效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据点选择 贝叶斯推断 随机梯度Langevin MCMC 深度学习 模型优化
📋 核心要点
- 现有数据点选择方法依赖双层优化,计算成本高昂,且在小批量训练中存在理论缺陷。
- 论文提出一种贝叶斯方法,将数据点选择视为后验推断,联合学习网络参数和实例权重。
- 实验证明该方法在视觉和语言任务上有效,并能扩展到大型语言模型,实现按任务优化。
📝 摘要(中文)
数据点选择(DPS)在深度学习中变得至关重要,因为获取未经处理的训练数据比获取精心策划或处理过的数据更容易。现有的DPS方法主要基于双层优化(BLO)公式,这在内存和计算方面要求很高,并且在minibatch方面存在一些理论缺陷。因此,我们提出了一种新的贝叶斯DPS方法。我们将DPS问题视为一种新颖贝叶斯模型中的后验推断问题,其中实例权重和主神经网络参数的后验分布是在合理的先验和似然模型下推断的。我们采用随机梯度Langevin MCMC采样来联合学习主网络和实例权重,确保即使使用minibatch也能收敛。我们的更新方程与广泛使用的SGD相当,并且比现有的基于BLO的方法效率更高。通过在视觉和语言领域中的受控实验,我们展示了概念验证。此外,我们证明了我们的方法可以有效地扩展到大型语言模型,并有助于指令微调数据集的自动化按任务优化。
🔬 方法详解
问题定义:数据点选择旨在从大量数据中选择最具信息量的子集进行训练,以提高模型效率和泛化能力。现有方法,特别是基于双层优化(BLO)的方法,计算复杂度高,内存需求大,难以扩展到大型数据集和模型。此外,BLO方法在处理小批量数据时存在理论上的不足,可能导致训练不稳定。
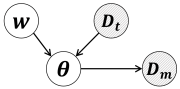
核心思路:论文的核心思路是将数据点选择问题转化为贝叶斯推断问题。通过构建一个贝叶斯模型,将每个数据点的权重视为随机变量,并利用后验推断来确定这些权重。这种方法允许联合学习神经网络的参数和数据点的权重,从而实现更有效的数据点选择。
技术框架:该方法的核心是构建一个贝叶斯模型,该模型包含神经网络参数和数据点权重。模型的训练过程采用随机梯度Langevin MCMC(SGLD)采样。SGLD是一种近似的MCMC方法,适用于大规模数据集的训练。通过SGLD,可以同时更新神经网络的参数和数据点的权重,从而实现联合优化。
关键创新:该方法最重要的创新在于将数据点选择问题转化为贝叶斯推断问题,并采用SGLD进行联合优化。与传统的BLO方法相比,该方法计算效率更高,内存需求更低,并且更适用于大规模数据集和模型。此外,该方法在理论上更健全,能够更好地处理小批量数据。
关键设计:论文的关键设计包括:1) 贝叶斯模型的构建,需要选择合适的先验分布和似然函数;2) SGLD算法的参数设置,例如学习率和噪声水平;3) 损失函数的设计,需要考虑模型性能和数据点权重的正则化。具体而言,论文可能采用了高斯先验或者其他常用的先验分布,并设计了相应的损失函数来鼓励选择更有信息量的数据点。
🖼️ 关键图片


📊 实验亮点
论文通过在视觉和语言领域的实验验证了该方法的有效性。实验结果表明,该方法在保持模型性能的同时,能够显著减少训练数据量,并能扩展到大型语言模型。具体性能提升数据未知,但摘要强调了其效率优于BLO方法,并能有效应用于指令微调数据集的自动化按任务优化。
🎯 应用场景
该研究成果可应用于各种需要数据点选择的深度学习场景,例如主动学习、模型压缩、领域自适应等。特别是在数据量巨大但标注成本高昂的情况下,该方法能够有效地选择最具价值的数据进行标注和训练,从而降低成本并提高模型性能。未来,该方法有望在自动驾驶、医疗诊断等领域发挥重要作用。
📄 摘要(原文)
Data point selection (DPS) is becoming a critical topic in deep learning due to the ease of acquiring uncurated training data compared to the difficulty of obtaining curated or processed data. Existing approaches to DPS are predominantly based on a bi-level optimisation (BLO) formulation, which is demanding in terms of memory and computation, and exhibits some theoretical defects regarding minibatches. Thus, we propose a novel Bayesian approach to DPS. We view the DPS problem as posterior inference in a novel Bayesian model where the posterior distributions of the instance-wise weights and the main neural network parameters are inferred under a reasonable prior and likelihood model. We employ stochastic gradient Langevin MCMC sampling to learn the main network and instance-wise weights jointly, ensuring convergence even with minibatches. Our update equation is comparable to the widely used SGD and much more efficient than existing BLO-based methods. Through controlled experiments in both the vision and language domains, we present the proof-of-concept. Additionally, we demonstrate that our method scales effectively to large language models and facilitates automated per-task optimization for instruction fine-tuning datasets.