GitChameleon: Unmasking the Version-Switching Capabilities of Code Generation Models
作者: Nizar Islah, Justine Gehring, Diganta Misra, Eilif Muller, Irina Rish, Terry Yue Zhuo, Massimo Caccia
分类: cs.SE, cs.LG
发布日期: 2024-11-05
🔗 代码/项目: GITHUB
💡 一句话要点
提出GitChameleon以解决代码生成模型版本适应性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 版本适应性 动态评估 Python 大型语言模型 数据集构建 软件开发
📋 核心要点
- 现有代码生成模型在适应软件库频繁版本更新时存在显著挑战,缺乏动态评估。
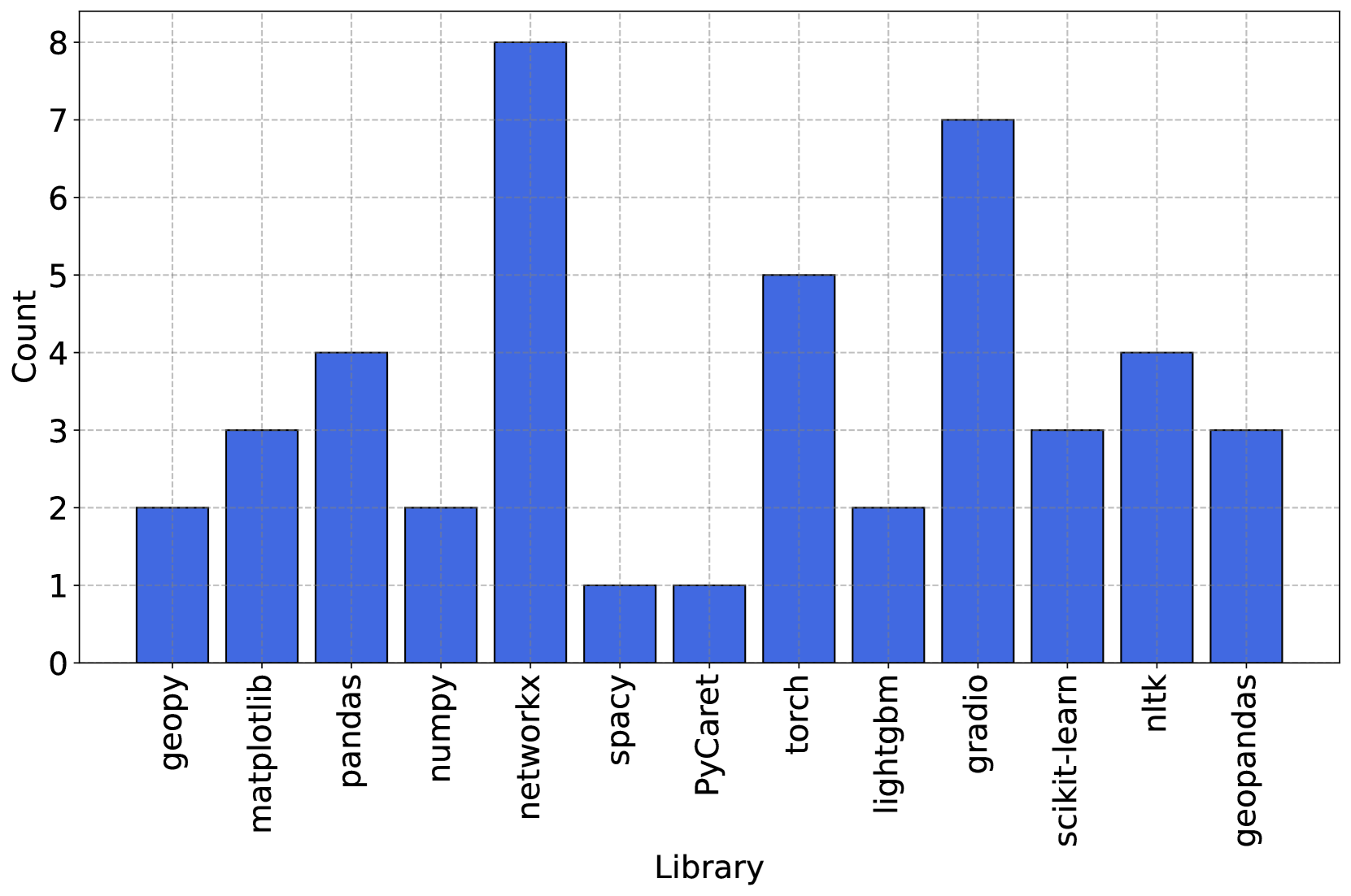
- 本文提出GitChameleon数据集,包含116个基于特定库版本的Python代码补全问题,配有可执行单元测试。
- 实验结果显示,当前最先进的LLMs在版本特定代码生成任务上表现不佳,GPT-4o的pass@10仅为39.9%。
📝 摘要(中文)
随着软件库的快速演变,代码生成模型面临着适应频繁版本更新的挑战,同时保持与先前版本的兼容性。现有的代码补全基准往往忽视这一动态特性,而考虑到这一点的基准又依赖于静态代码预测任务,缺乏基于执行的评估,限制了模型的实际可用性。为了解决这一问题,本文提出了GitChameleon,一个新颖的手动策划数据集,包含116个Python代码补全问题,每个问题都基于特定的库版本,并附有可执行的单元测试。GitChameleon旨在严格评估现代大型语言模型生成特定版本代码的能力,确保其不仅语法正确,而且在执行时功能准确。综合评估显示,当前最先进的LLMs在此任务上表现不佳,例如GPT-4o的pass@10仅为39.9%。
🔬 方法详解
问题定义:本文旨在解决代码生成模型在频繁版本更新中保持兼容性的问题。现有方法往往忽视动态版本变化,导致模型在实际应用中的局限性。
核心思路:通过引入GitChameleon数据集,论文提供了一个基于执行的评估框架,强调生成代码的版本特定性和功能准确性。这样的设计旨在填补现有基准的空白,推动模型的适应性和可靠性。
技术框架:整体架构包括数据集构建、问题定义、代码生成和执行评估四个主要模块。每个模块都围绕如何确保生成代码的版本适应性进行设计。
关键创新:GitChameleon的最大创新在于其手动策划的数据集和执行基准,这与以往静态预测任务的评估方式本质上不同,强调了动态库版本的影响。
关键设计:在数据集构建中,针对每个问题设置了特定的库版本,并设计了相应的可执行单元测试,以确保生成代码的功能性和准确性。
🖼️ 关键图片

📊 实验亮点
实验结果显示,当前最先进的LLMs在版本特定代码生成任务上表现不佳,GPT-4o的pass@10仅为39.9%,在提供错误反馈后提升至43.7%。这一结果突显了现有模型在动态代码生成中的局限性。
🎯 应用场景
该研究的潜在应用领域包括自动化代码生成、软件开发工具和智能编程助手等。通过提升代码生成模型的版本适应性,能够显著提高软件开发的效率和可靠性,推动智能编程技术的发展。
📄 摘要(原文)
The rapid evolution of software libraries presents a significant challenge for code generation models, which must adapt to frequent version updates while maintaining compatibility with previous versions. Existing code completion benchmarks often overlook this dynamic aspect, and the one that does consider it relies on static code prediction tasks without execution-based evaluation, offering a limited perspective on a model's practical usability. To address this gap, we introduce \textbf{\GitChameleon{}}, a novel, manually curated dataset comprising 116 Python code completion problems, each conditioned on specific library versions and accompanied by executable unit tests. \GitChameleon{} is designed to rigorously assess the ability of modern large language models (LLMs) to generate version-specific code that is not only syntactically correct but also functionally accurate upon execution. Our comprehensive evaluations reveal that state-of-the-art LLMs struggle with this task; for instance, \textbf{GPT-4o} achieves a pass@10 of only 39.9\% (43.7\% when provided with error feedback), highlighting the complexity of the problem and the limitations of current models. By providing an execution-based benchmark that emphasizes the dynamic nature of code libraries, \GitChameleon{} serves as a critical tool to advance the development of more adaptable and reliable code generation models. For facilitation for further exploration of version-conditioned code generation, we make our code repository publicly accessible at \url{https://github.com/NizarIslah/GitChameleon}.