A Mamba Foundation Model for Time Series Forecasting
作者: Haoyu Ma, Yushu Chen, Wenlai Zhao, Jinzhe Yang, Yingsheng Ji, Xinghua Xu, Xiaozhu Liu, Hao Jing, Shengzhuo Liu, Guangwen Yang
分类: cs.LG, cs.AI
发布日期: 2024-11-05
💡 一句话要点
提出TSMamba,一种基于Mamba架构的时间序列预测线性复杂度基础模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 Mamba架构 线性复杂度 迁移学习 零样本学习
📋 核心要点
- Transformer在时间序列预测中计算复杂度高,限制了其在长序列上的应用。
- TSMamba利用Mamba架构的线性复杂度特性,结合前向和后向编码器捕获时间依赖。
- TSMamba通过两阶段迁移学习,降低了对大规模数据集的依赖,并实现了优异的零样本和全监督性能。
📝 摘要(中文)
时间序列基础模型在零样本学习中表现出强大的性能,使其非常适合预测实际应用中快速演变的模式,尤其是在相关训练数据稀缺的情况下。然而,这些模型大多依赖于Transformer架构,随着输入长度的增加,其计算复杂度呈二次方增长。为了解决这个问题,我们引入了TSMamba,一种基于Mamba架构的时间序列预测线性复杂度基础模型。该模型通过前向和后向Mamba编码器捕获时间依赖关系,从而实现高预测精度。为了减少对大型数据集的依赖并降低训练成本,TSMamba采用了一种两阶段迁移学习过程,利用预训练的Mamba LLM,从而可以使用适中的训练集进行有效的时间序列建模。在第一阶段,通过分片自回归预测优化前向和后向骨干网络;在第二阶段,该模型训练预测头并细化其他组件以进行长期预测。虽然骨干网络假设通道独立性以管理跨数据集的不同通道数量,但引入了通道压缩注意力模块,以在特定多元数据集上进行微调期间捕获跨通道依赖关系。实验表明,TSMamba的零样本性能与最先进的时间序列基础模型相当,尽管使用的训练数据明显更少。与特定任务的预测模型相比,它还实现了有竞争力的或更优越的完全监督性能。代码将公开提供。
🔬 方法详解
问题定义:论文旨在解决时间序列预测任务中,现有基于Transformer的模型计算复杂度高,难以处理长序列的问题。同时,现有模型对大规模数据集的依赖性也限制了其在数据稀缺场景下的应用。
核心思路:论文的核心思路是利用Mamba架构的线性复杂度特性,替代Transformer,从而降低计算成本,提高处理长序列的能力。此外,通过两阶段迁移学习策略,利用预训练的Mamba LLM,减少对大规模数据集的依赖。
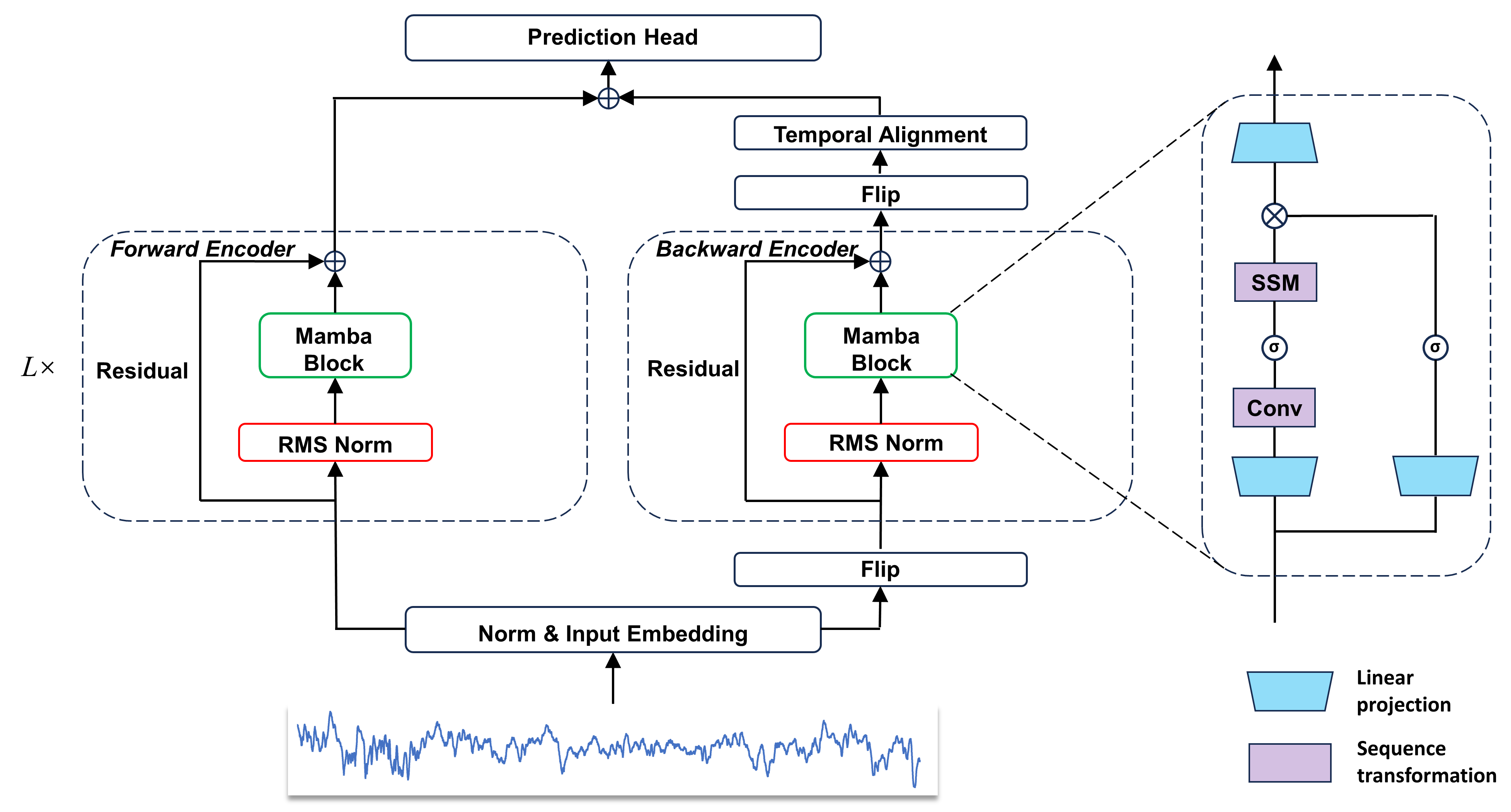
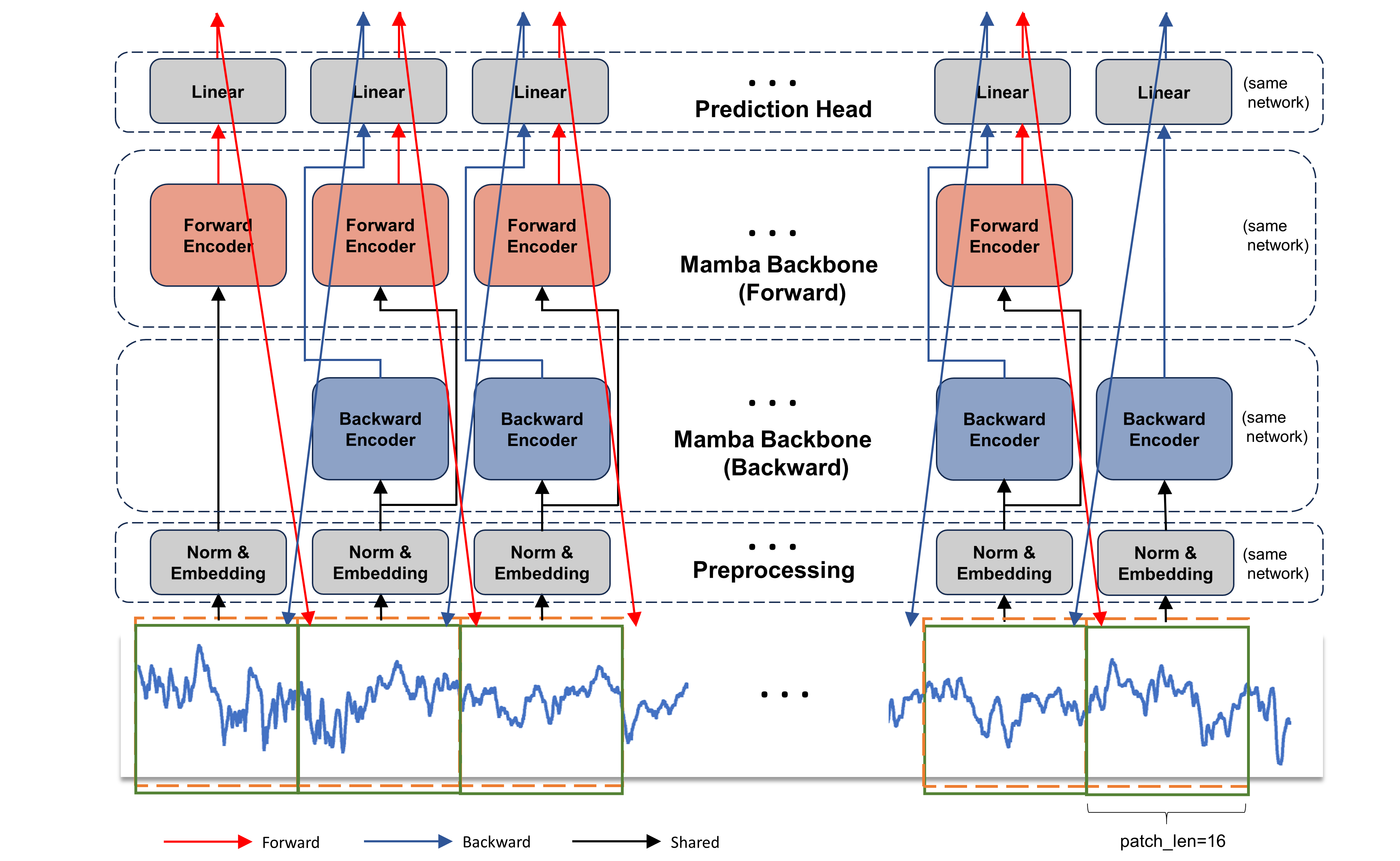
技术框架:TSMamba的整体框架包含以下几个主要模块:1) 前向Mamba编码器:用于捕获时间序列的前向依赖关系。2) 后向Mamba编码器:用于捕获时间序列的后向依赖关系。3) 两阶段迁移学习:第一阶段,通过分片自回归预测优化前向和后向骨干网络;第二阶段,训练预测头并细化其他组件。4) 通道压缩注意力模块:在微调阶段,用于捕获跨通道依赖关系。
关键创新:TSMamba的关键创新在于:1) 将Mamba架构引入时间序列预测领域,实现了线性复杂度的模型。2) 提出了前向和后向Mamba编码器,更全面地捕获时间依赖关系。3) 设计了两阶段迁移学习策略,有效利用预训练的Mamba LLM,降低了对大规模数据集的依赖。
关键设计:TSMamba的关键设计包括:1) 骨干网络假设通道独立性,以适应不同数据集的通道数量。2) 引入通道压缩注意力模块,在微调阶段捕获跨通道依赖关系。3) 两阶段迁移学习的具体实现方式,包括分片自回归预测和预测头的训练。
🖼️ 关键图片

📊 实验亮点
TSMamba在零样本学习中表现出与最先进的时间序列基础模型相当的性能,同时使用的训练数据明显更少。在全监督学习中,TSMamba也取得了与特定任务的预测模型相比具有竞争力的或更优越的性能。这些结果表明,TSMamba在时间序列预测领域具有显著的优势。
🎯 应用场景
TSMamba具有广泛的应用前景,包括但不限于:金融市场预测、能源消耗预测、交通流量预测、医疗健康监测等。其低计算复杂度和对小样本数据的适应性,使其特别适用于资源受限或数据稀缺的场景。未来,TSMamba有望成为时间序列预测领域的重要基础模型。
📄 摘要(原文)
Time series foundation models have demonstrated strong performance in zero-shot learning, making them well-suited for predicting rapidly evolving patterns in real-world applications where relevant training data are scarce. However, most of these models rely on the Transformer architecture, which incurs quadratic complexity as input length increases. To address this, we introduce TSMamba, a linear-complexity foundation model for time series forecasting built on the Mamba architecture. The model captures temporal dependencies through both forward and backward Mamba encoders, achieving high prediction accuracy. To reduce reliance on large datasets and lower training costs, TSMamba employs a two-stage transfer learning process that leverages pretrained Mamba LLMs, allowing effective time series modeling with a moderate training set. In the first stage, the forward and backward backbones are optimized via patch-wise autoregressive prediction; in the second stage, the model trains a prediction head and refines other components for long-term forecasting. While the backbone assumes channel independence to manage varying channel numbers across datasets, a channel-wise compressed attention module is introduced to capture cross-channel dependencies during fine-tuning on specific multivariate datasets. Experiments show that TSMamba's zero-shot performance is comparable to state-of-the-art time series foundation models, despite using significantly less training data. It also achieves competitive or superior full-shot performance compared to task-specific prediction models. The code will be made publicly available.