P-MOSS: Scheduling Main-Memory Indexes Over NUMA Servers Using Next Token Prediction
作者: Yeasir Rayhan, Walid G. Aref
分类: cs.DB, cs.LG, cs.PF
发布日期: 2024-11-05 (更新: 2026-01-21)
备注: Accepted to SIGMOD'26
DOI: 10.1145/3786675
💡 一句话要点
P-MOSS:利用下一令牌预测在NUMA服务器上调度主存索引,提升查询吞吐量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: NUMA架构 查询调度 数据放置 机器学习 大型语言模型 决策Transformer B+树索引
📋 核心要点
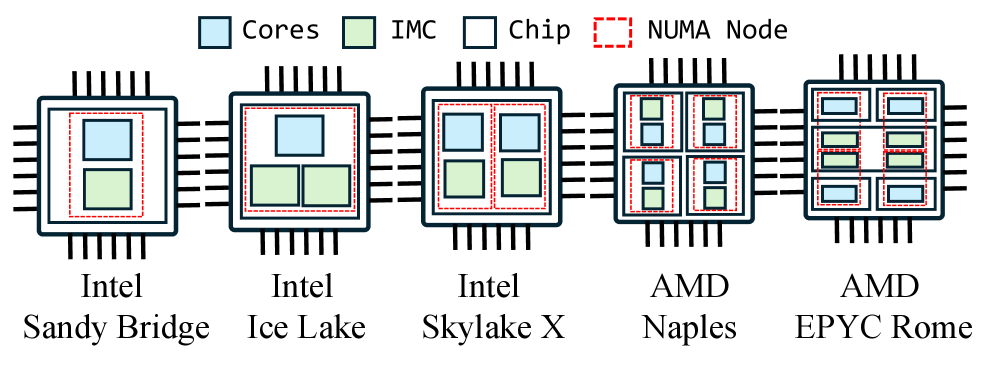
- 现代NUMA架构下,DBMS查询性能受逻辑核心和数据位置影响显著,传统调度策略难以适应硬件异构性。
- P-MOSS利用LLM的下一令牌预测等技术,学习硬件统计信息,实现查询调度和数据共置优化。
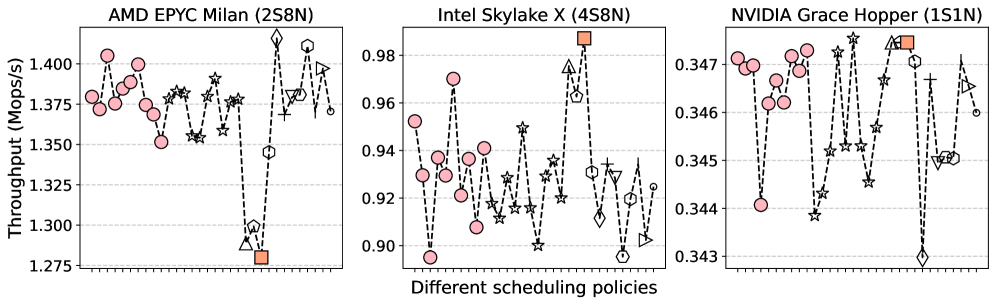
- 实验表明,P-MOSS在B$^+$-Tree索引场景下,查询吞吐量相比传统调度策略提升高达6倍。
📝 摘要(中文)
自2000年代初Dennard scaling失效以来,CPU频率停滞,厂商开始增加每个CPU芯片中的核心数量,但也引入了异构性,从而开启了NUMA和Chiplet处理器时代。硬件设计空间的异构性日益增加,导致DBMS性能在现代服务器上可能出现高达一个数量级的显著差异。影响性能的一个重要因素包括DBMS查询执行的逻辑核心的位置以及数据驻留的位置。本文介绍了P-MOSS,一个学习型的空间调度框架,它将查询执行调度到特定的逻辑核心,并将数据共置于相应的NUMA节点上。为了实现跨硬件和工作负载的适应性,P-MOSS利用了大型语言模型的核心原则,例如下一令牌预测、生成式预训练和微调。秉承软硬件协同的精神,P-MOSS仅基于从硬件性能监控单元收集的底层硬件统计信息,借助决策Transformer来指导其调度决策。在B$^+$-Tree索引的背景下进行了实验评估。性能结果表明,P-MOSS在查询吞吐量方面比传统调度方案提高了高达6倍。
🔬 方法详解
问题定义:论文旨在解决NUMA架构下,数据库管理系统(DBMS)查询性能受限于数据和计算资源位置不匹配的问题。传统调度策略无法有效利用NUMA架构的局部性优势,导致跨NUMA节点的数据访问延迟增加,降低整体查询吞吐量。现有方法通常依赖于人工规则或简单的启发式算法,难以适应不同硬件配置和工作负载的变化。
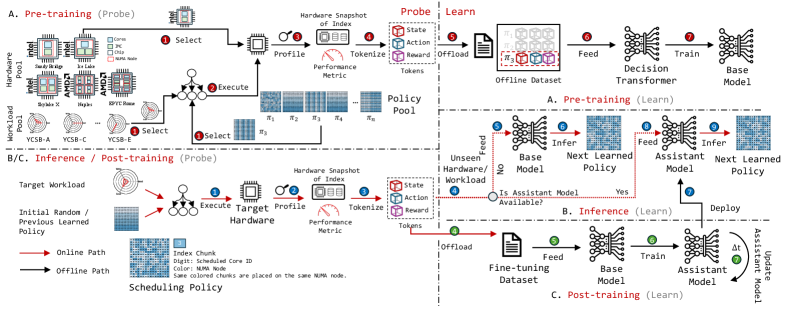
核心思路:P-MOSS的核心思路是利用机器学习方法,特别是借鉴大型语言模型(LLM)的思路,学习硬件性能特征与查询性能之间的关系,从而实现智能化的查询调度和数据放置。通过预测下一个“令牌”(即下一个要访问的数据或计算资源),P-MOSS能够将查询调度到最佳的逻辑核心,并将数据放置在相应的NUMA节点上,从而最大程度地减少跨NUMA节点的数据访问。
技术框架:P-MOSS的技术框架主要包括以下几个模块:1) 硬件性能监控单元(PMU):负责收集底层硬件统计信息,例如CPU利用率、缓存命中率、内存带宽等。2) 决策Transformer:一个基于Transformer的深度学习模型,用于学习硬件统计信息与查询性能之间的关系,并预测最佳的查询调度方案。3) 调度器:根据决策Transformer的预测结果,将查询调度到特定的逻辑核心,并将数据放置在相应的NUMA节点上。4) 生成式预训练和微调:借鉴LLM的训练方法,首先使用大量的硬件统计数据进行预训练,然后在特定工作负载下进行微调,以提高模型的泛化能力。
关键创新:P-MOSS的关键创新在于将大型语言模型的思想应用于数据库查询调度和数据放置问题。与传统的基于规则或启发式算法的方法相比,P-MOSS能够自动学习硬件性能特征与查询性能之间的复杂关系,从而实现更智能化的调度决策。此外,P-MOSS还利用决策Transformer来建模调度策略,能够更好地捕捉硬件状态之间的依赖关系。
关键设计:P-MOSS的关键设计包括:1) 使用硬件性能监控单元(PMU)收集底层硬件统计信息,作为模型输入。2) 使用决策Transformer作为调度策略模型,该模型能够捕捉硬件状态之间的依赖关系。3) 借鉴LLM的训练方法,使用生成式预训练和微调来提高模型的泛化能力。4) 使用下一令牌预测作为优化目标,即预测下一个要访问的数据或计算资源,从而实现智能化的查询调度和数据放置。
🖼️ 关键图片
📊 实验亮点
实验结果表明,P-MOSS在B$^+$-Tree索引场景下,相比传统的调度策略,查询吞吐量提升高达6倍。这一显著的性能提升证明了P-MOSS在NUMA架构下优化查询性能的有效性。此外,P-MOSS还展现出良好的跨硬件和工作负载适应性,能够在不同的硬件配置和工作负载下实现稳定的性能提升。
🎯 应用场景
P-MOSS可应用于各种需要高性能数据访问的场景,例如内存数据库、图数据库、实时分析系统等。通过智能化的查询调度和数据放置,P-MOSS能够显著提高查询吞吐量,降低查询延迟,从而提升整体系统性能。未来,P-MOSS有望应用于更复杂的异构计算环境,例如CPU-GPU混合架构、云原生数据库等。
📄 摘要(原文)
Ever since the Dennard scaling broke down in the early 2000s and the frequency of the CPUs stalled, vendors have started to increase the core count in each CPU chip at the expense of introducing heterogeneity, thus ushering the era of NUMA and Chiplet processors. Since then, the heterogeneity in the design space of hardware has only increased to the point that DBMS performance may vary significantly up to an order of magnitude in modern servers. An important factor that affects performance includes the location of the logical cores where the DBMS queries execute, and the location where the data resides. This paper introduces P-MOSS, a learned spatial scheduling framework that schedules query execution to specific logical cores, and co-locates data on the corresponding NUMA node. For cross-hardware and workload adaptability, P-MOSS leverages core principles from Large Language Models, such as Next Token prediction, Generative Pre-training, and Fine-tuning. In the spirit of hardware-software synergy, P-MOSS guides its scheduling decision solely based on the low-level hardware statistics collected from the hardware Performance Monitoring Unit with the aid of a Decision Transformer. Experimental evaluation is performed in the context of the B$^+$-Tree index. Performance results demonstrate that P-MOSS offers an improvement of up to $6\times$ over traditional schedules in terms of query throughput.