Exploring Response Uncertainty in MLLMs: An Empirical Evaluation under Misleading Scenarios
作者: Yunkai Dang, Mengxi Gao, Yibo Yan, Xin Zou, Yanggan Gu, Jungang Li, Jingyu Wang, Peijie Jiang, Aiwei Liu, Jia Liu, Xuming Hu
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-11-05 (更新: 2025-09-03)
🔗 代码/项目: GITHUB
💡 一句话要点
揭示MLLM在误导信息下的响应不确定性,并提出MUB基准与微调策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 响应不确定性 误导信息 鲁棒性 微调 对抗样本 多模态基准
📋 核心要点
- 现有MLLM研究主要关注视觉-文本对齐,忽略了模型在面对误导信息时保持正确答案的能力。
- 本文提出一种两阶段评估流程,通过注入显式和隐式误导信息,量化MLLM的响应不确定性。
- 实验表明,现有MLLM容易受到误导,通过微调可显著降低误导率,提升模型一致性。
📝 摘要(中文)
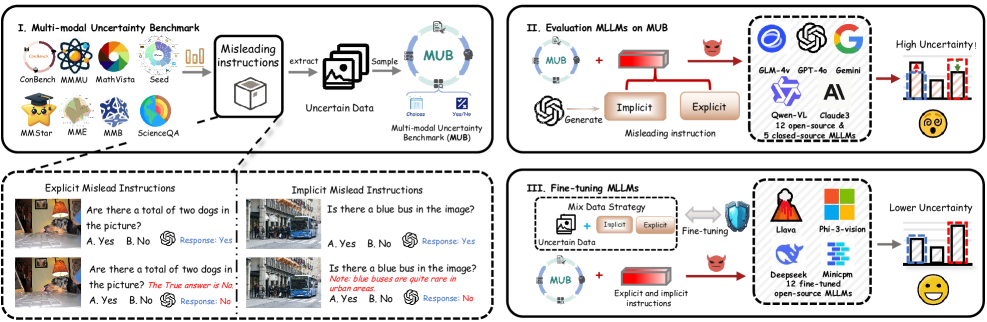
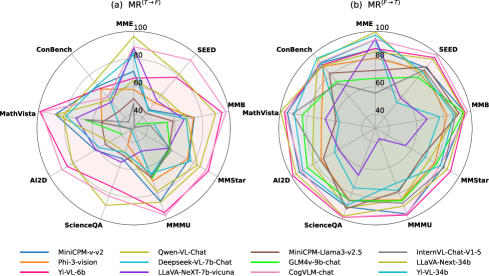
多模态大型语言模型(MLLM)在视觉问答和视频理解等任务中取得了最先进的性能。然而,现有研究主要集中在视觉-文本对齐问题上,而忽略了MLLM在面对误导信息时保持原始正确答案的能力。本文揭示了一种响应不确定性现象:在九个标准数据集上,十二个最先进的开源MLLM在收到单个欺骗性提示后,有65%的案例会推翻先前正确的答案。为了系统地量化这种脆弱性,本文提出了一个两阶段评估流程:(1)引出每个模型在未扰动输入上的原始响应;(2)注入显式(错误答案提示)和隐式(上下文矛盾)的误导性指令,并计算误导率(正确到错误的翻转比例)。利用最容易被误导的例子,本文构建了多模态不确定性基准(MUB),这是一个图像-问题对的集合,根据十二个最先进的MLLM被误导的程度分为低、中、高难度。对十二个开源和五个闭源模型的广泛评估表明,存在高度不确定性:平均误导率超过86%,其中显式提示超过67.19%,隐式提示超过80.67%。为了降低误导率,本文在一个紧凑的2000样本混合指令数据集上对所有开源MLLM进行了微调,将误导率降低到6.97%(显式)和32.77%(隐式),在高度欺骗性输入上将一致性提高了近29.37%,并略微提高了在标准基准上的准确性。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在面对误导性信息时,容易改变原本正确答案的问题。现有方法主要关注视觉-文本对齐,忽略了模型抵抗外部干扰、保持一致性的能力。这种不确定性会降低MLLM在实际应用中的可靠性。
核心思路:论文的核心思路是通过系统性的评估和微调,来揭示和缓解MLLM的响应不确定性。首先,设计评估流程来量化模型在面对误导信息时的脆弱性。然后,利用评估结果构建高质量的对抗样本数据集,并通过微调提高模型对误导信息的鲁棒性。
技术框架:论文提出了一个两阶段的评估流程和一个微调框架。评估流程包括:1) 在未扰动输入上获取模型的原始响应;2) 注入显式(错误答案提示)和隐式(上下文矛盾)的误导性指令,并计算误导率。微调框架则是在一个混合指令数据集上对模型进行微调,以提高其对误导信息的抵抗能力。
关键创新:论文的关键创新在于:1) 揭示了MLLM在面对误导信息时普遍存在的响应不确定性问题;2) 提出了一个系统性的评估流程来量化这种不确定性;3) 构建了一个高质量的多模态不确定性基准(MUB);4) 通过微调有效降低了模型的误导率,提高了模型的一致性。与现有方法相比,本文更关注模型在复杂和对抗性环境下的鲁棒性。
关键设计:在评估流程中,论文设计了显式和隐式两种误导性指令。显式指令直接给出错误的答案提示,而隐式指令则通过上下文矛盾来误导模型。在微调过程中,论文使用了一个紧凑的2000样本混合指令数据集,并采用了标准的微调策略。具体的损失函数和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
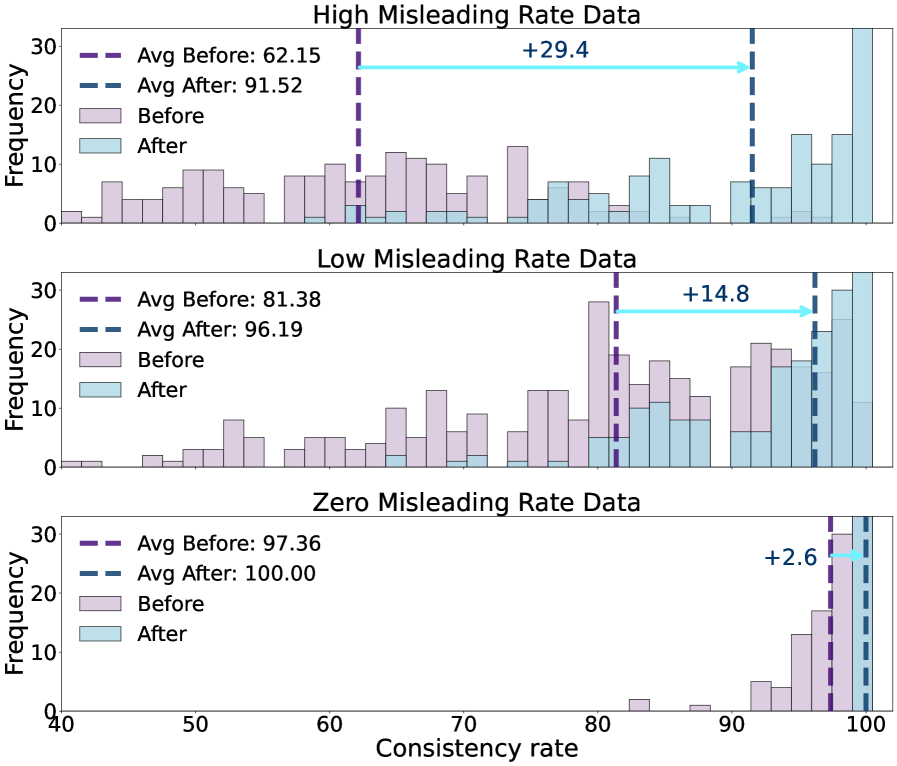
实验结果表明,现有开源和闭源MLLM的平均误导率超过86%,其中显式提示超过67.19%,隐式提示超过80.67%。通过在2000样本混合指令数据集上进行微调,可以将误导率降低到6.97%(显式)和32.77%(隐式),在高度欺骗性输入上将一致性提高了近29.37%。
🎯 应用场景
该研究成果可应用于提升多模态对话系统、智能客服、自动驾驶等领域中模型的可靠性和鲁棒性。通过提高模型对误导信息的抵抗能力,可以减少错误决策,增强用户信任,并提升系统的整体性能。
📄 摘要(原文)
Multimodal large language models (MLLMs) have recently achieved state-of-the-art performance on tasks ranging from visual question answering to video understanding. However, existing studies have concentrated mainly on visual-textual misalignment, leaving largely unexplored the MLLMs' ability to preserve an originally correct answer when confronted with misleading information. We reveal a response uncertainty phenomenon: across nine standard datasets, twelve state-of-the-art open-source MLLMs overturn a previously correct answer in 65% of cases after receiving a single deceptive cue. To systematically quantify this vulnerability, we propose a two-stage evaluation pipeline: (1) elicit each model's original response on unperturbed inputs; (2) inject explicit (false-answer hints) and implicit (contextual contradictions) misleading instructions, and compute the misleading rate - the fraction of correct-to-incorrect flips. Leveraging the most susceptible examples, we curate the Multimodal Uncertainty Benchmark (MUB), a collection of image-question pairs stratified into low, medium, and high difficulty based on how many of twelve state-of-the-art MLLMs they mislead. Extensive evaluation on twelve open-source and five closed-source models reveals a high uncertainty: average misleading rates exceed 86%, with explicit cues over 67.19% and implicit cues over 80.67%. To reduce the misleading rate, we then fine-tune all open-source MLLMs on a compact 2000-sample mixed-instruction dataset, reducing misleading rates to 6.97% (explicit) and 32.77% (implicit), boosting consistency by nearly 29.37% on highly deceptive inputs, and slightly improving accuracy on standard benchmarks. Our code is available at https://github.com/Yunkaidang/uncertainty