Dynamic Weight Adjusting Deep Q-Networks for Real-Time Environmental Adaptation
作者: Xinhao Zhang, Jinghan Zhang, Wujun Si, Kunpeng Liu
分类: cs.LG
发布日期: 2024-11-04
备注: Accepted by ICKG2024
💡 一句话要点
提出交互式动态评估DQN,解决DQN在动态环境中适应性不足的问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 动态环境 经验回放 重要性采样 DQN
📋 核心要点
- 传统DQN在动态环境中适应性差,依赖大量稳定环境数据,难以应对环境的快速变化。
- 提出交互式动态评估方法(IDEM),通过动态调整经验回放的采样概率,使DQN更关注关键转移。
- 实验表明,IDEM-DQN在动态环境中比标准DQN表现更好,泛化能力和学习稳定性更强。
📝 摘要(中文)
深度强化学习在解决复杂任务方面表现出色,但其有效性常受限于静态训练模式和对稳定环境大量数据的依赖。为了解决这些缺点,本研究探索将动态权重调整融入深度Q网络(DQN)以增强其适应性。通过修改经验回放中的采样概率,使模型更加关注由实时环境反馈和性能指标指示的关键转移。我们设计了一种新颖的交互式动态评估方法(IDEM),用于DQN,通过优先考虑基于环境反馈和学习进度的重要转移,成功地在动态环境中导航。此外,当面临环境条件的快速变化时,IDEM-DQN相比基线方法表现出改进的性能。结果表明,在需要快速适应的情况下,IDEM-DQN可以更有效地泛化和稳定学习。在各种设置下进行的大量实验证实,IDEM-DQN优于标准DQN模型,尤其是在以频繁和不可预测的变化为特征的环境中。
🔬 方法详解
问题定义:DQN在动态环境中难以适应,主要原因是其静态的训练方式无法有效利用环境的实时反馈,导致模型难以快速捕捉环境变化的关键信息。此外,DQN对稳定环境的大量数据依赖性强,在环境快速变化时,旧数据会干扰学习,降低模型的泛化能力。
核心思路:论文的核心思路是通过动态调整经验回放的采样概率,使DQN能够更加关注那些对学习有重要影响的转移样本。具体来说,根据环境的实时反馈和模型的学习进度,对不同的转移样本赋予不同的权重,从而让模型能够更加有效地利用环境信息,快速适应环境变化。
技术框架:IDEM-DQN的整体框架仍然基于DQN,但引入了交互式动态评估模块(IDEM)。该模块负责根据环境反馈和学习进度,计算每个转移样本的重要性权重,并根据这些权重调整经验回放的采样概率。训练过程中,DQN从经验回放中采样样本,并利用这些样本更新Q函数。IDEM模块与DQN的训练过程相互作用,动态调整采样策略,从而提高模型的学习效率和适应性。
关键创新:IDEM-DQN的关键创新在于其动态权重调整机制。传统的DQN采用均匀采样或基于TD误差的采样,无法有效区分不同转移样本的重要性。IDEM通过综合考虑环境反馈和学习进度,能够更加准确地评估每个转移样本的价值,并根据这些价值动态调整采样概率。这种动态调整机制使得DQN能够更加有效地利用环境信息,快速适应环境变化。
关键设计:IDEM模块的设计是关键。具体如何定义环境反馈和学习进度,以及如何将它们转化为转移样本的权重,是需要仔细考虑的问题。论文中可能涉及具体的权重计算公式,以及如何平衡探索和利用的策略。此外,经验回放的容量和采样频率等参数也会影响IDEM-DQN的性能。
🖼️ 关键图片

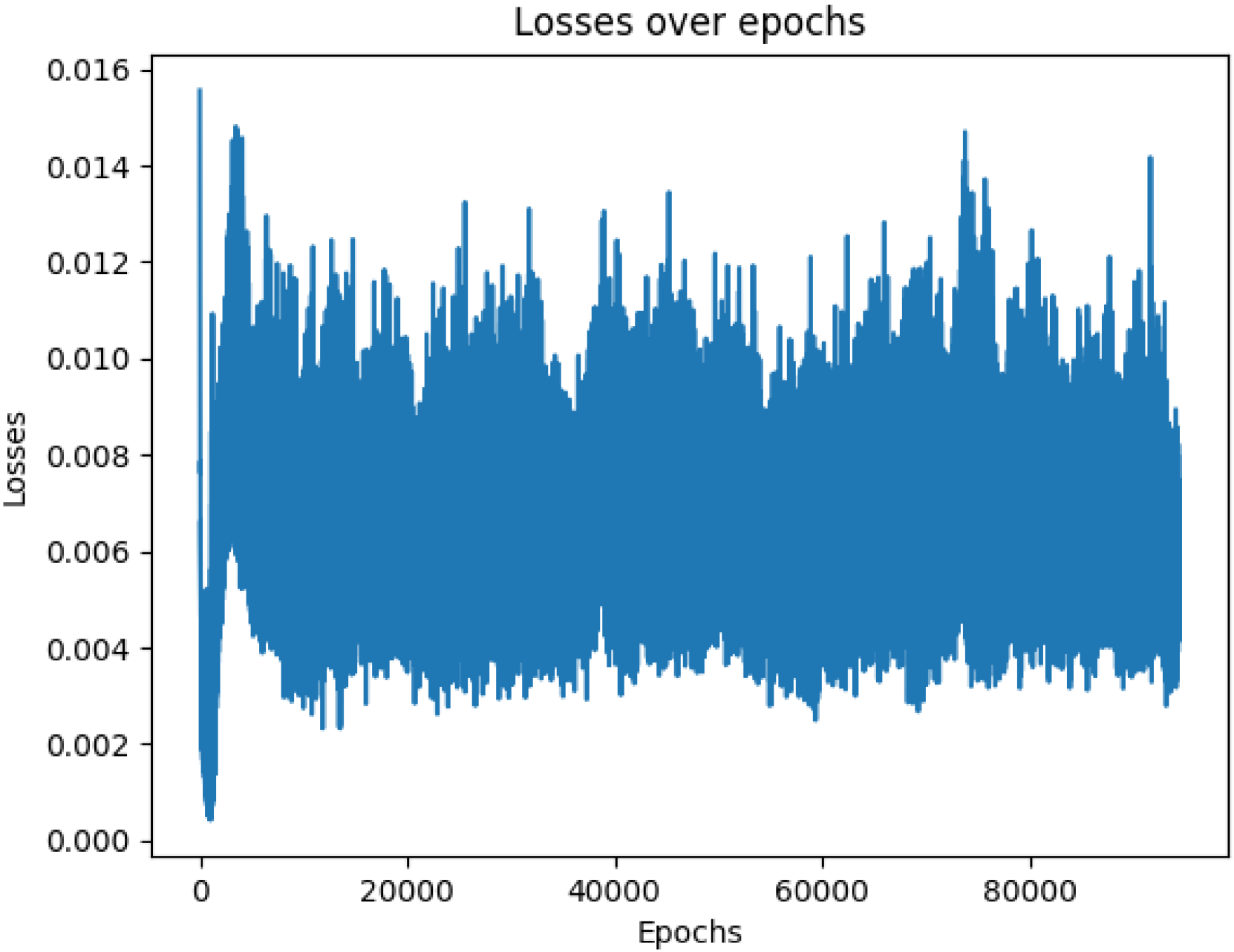
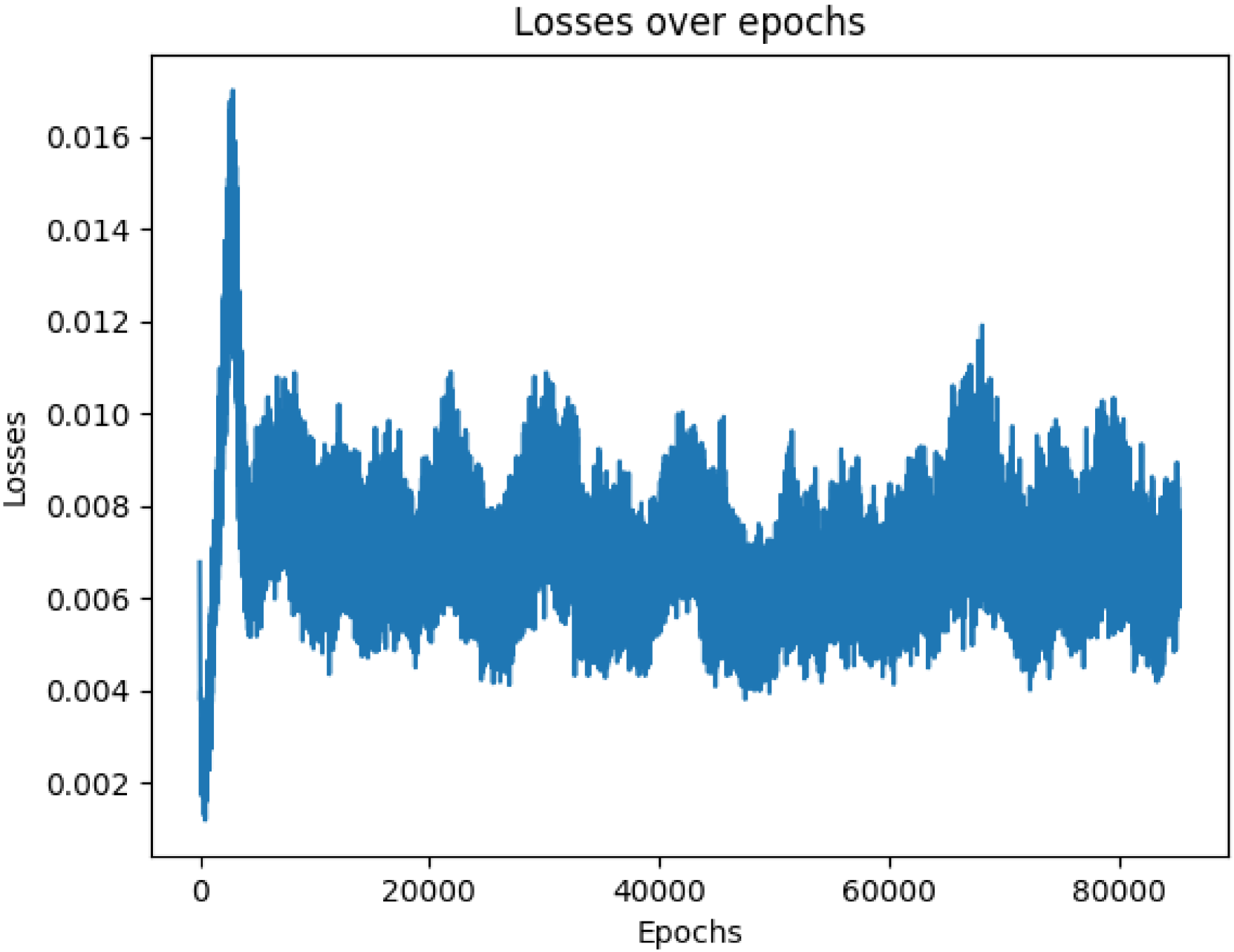
📊 实验亮点
论文通过在各种动态环境中进行实验,验证了IDEM-DQN的有效性。实验结果表明,IDEM-DQN在环境快速变化的情况下,比标准DQN模型表现更好,能够更快地适应环境变化,并取得更高的奖励。具体的性能提升幅度可能在论文中给出,例如,在特定环境下,IDEM-DQN的平均奖励比标准DQN提高了百分之多少。
🎯 应用场景
IDEM-DQN适用于需要快速适应环境变化的强化学习任务,例如机器人导航、自动驾驶、资源管理和游戏AI等。在这些场景中,环境条件经常发生变化,传统的强化学习方法难以取得良好的效果。IDEM-DQN通过动态调整学习策略,能够更好地适应环境变化,提高模型的性能和鲁棒性,具有重要的实际应用价值。
📄 摘要(原文)
Deep Reinforcement Learning has shown excellent performance in generating efficient solutions for complex tasks. However, its efficacy is often limited by static training modes and heavy reliance on vast data from stable environments. To address these shortcomings, this study explores integrating dynamic weight adjustments into Deep Q-Networks (DQN) to enhance their adaptability. We implement these adjustments by modifying the sampling probabilities in the experience replay to make the model focus more on pivotal transitions as indicated by real-time environmental feedback and performance metrics. We design a novel Interactive Dynamic Evaluation Method (IDEM) for DQN that successfully navigates dynamic environments by prioritizing significant transitions based on environmental feedback and learning progress. Additionally, when faced with rapid changes in environmental conditions, IDEM-DQN shows improved performance compared to baseline methods. Our results indicate that under circumstances requiring rapid adaptation, IDEM-DQN can more effectively generalize and stabilize learning. Extensive experiments across various settings confirm that IDEM-DQN outperforms standard DQN models, particularly in environments characterized by frequent and unpredictable changes.