"Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization
作者: Eldar Kurtic, Alexandre Marques, Shubhra Pandit, Mark Kurtz, Dan Alistarh
分类: cs.LG, cs.AI
发布日期: 2024-11-04 (更新: 2025-05-30)
备注: Accepted to ACL 2025
💡 一句话要点
LLM量化精度-性能权衡研究:为Llama-3.1模型家族选择最优量化方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 量化 模型压缩 推理加速 精度-性能权衡
📋 核心要点
- 现有LLM量化方案在精度和性能之间存在权衡,缺乏针对不同部署场景的明确指导。
- 该论文通过大规模实验评估FP8、INT8和INT4量化在Llama-3.1模型家族上的表现,并分析推理性能。
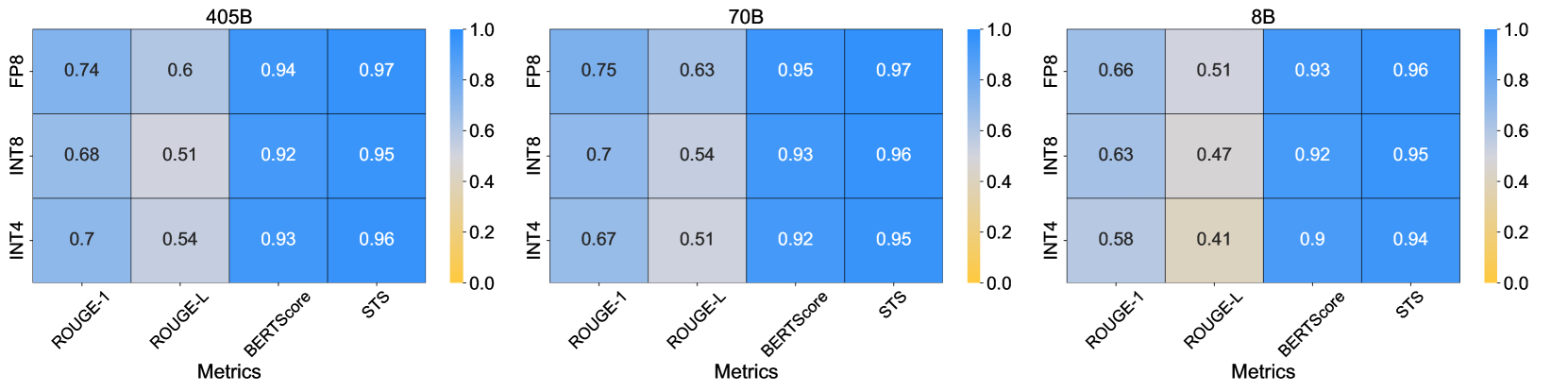
- 实验结果表明,FP8近乎无损,INT8精度损失可控,INT4在特定场景下具有竞争力,并给出了部署建议。
📝 摘要(中文)
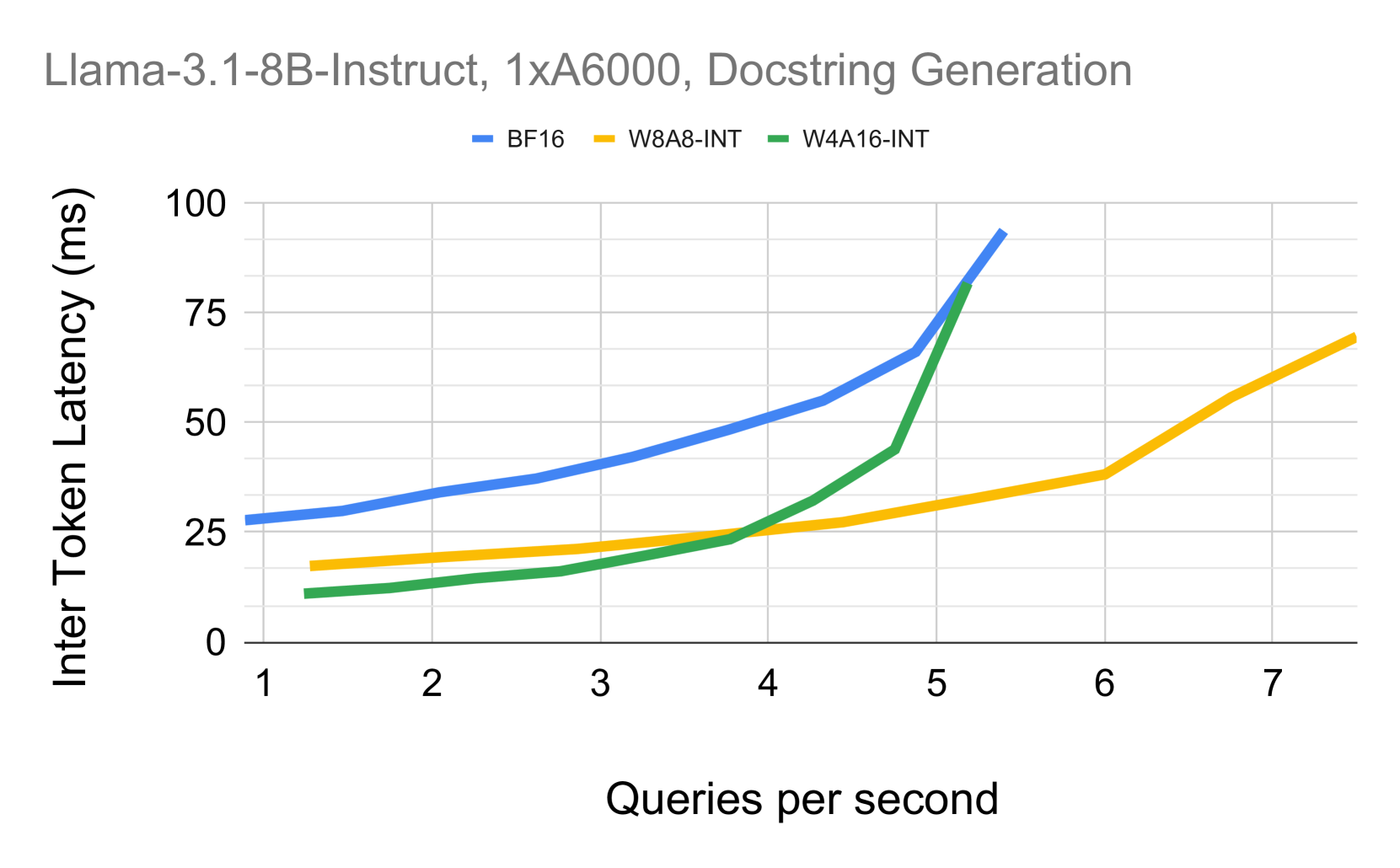
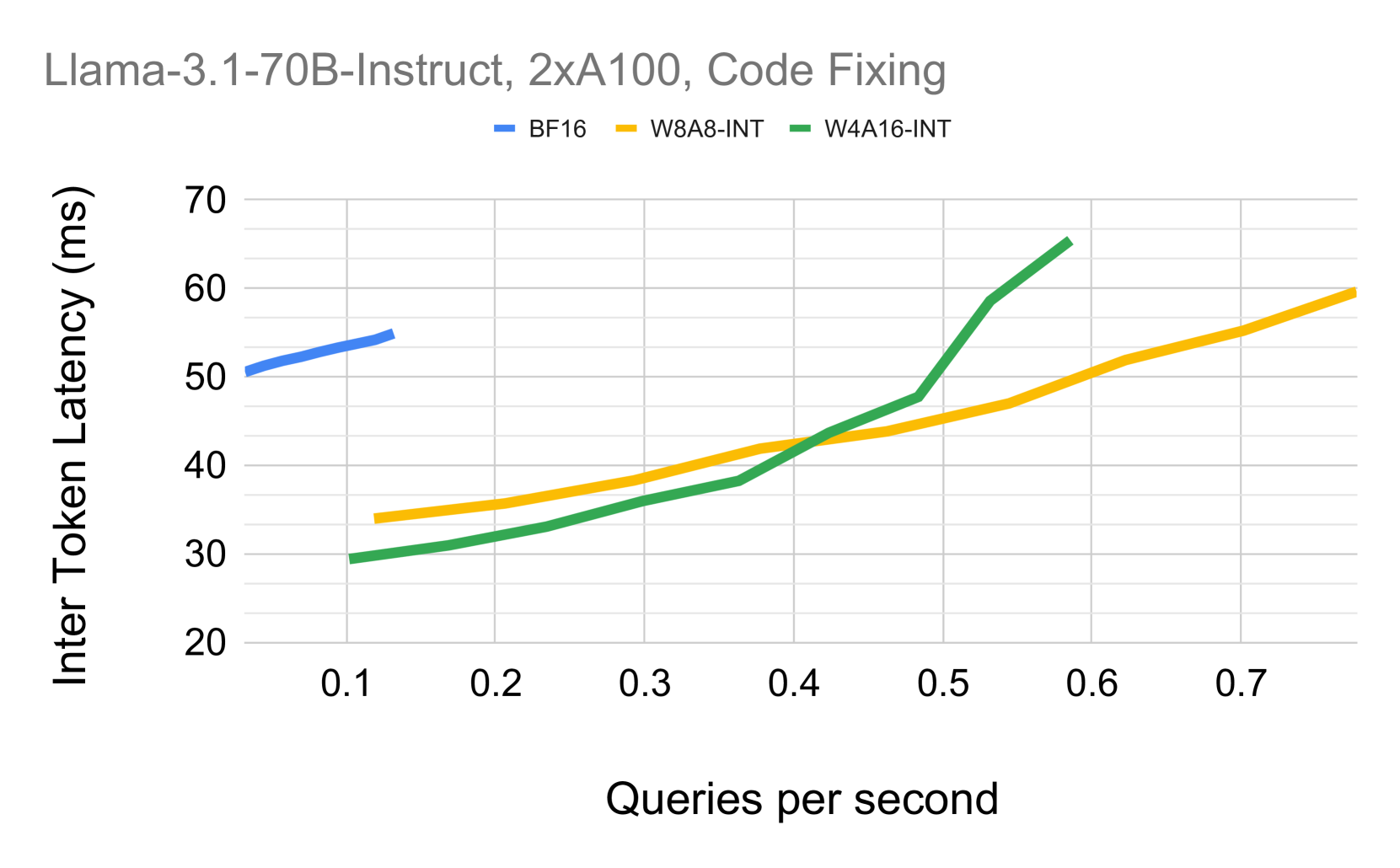
量化是加速大型语言模型(LLM)推理的有效工具,但不同格式之间的精度-性能权衡尚不明确。本文对FP8、INT8和INT4量化在整个Llama-3.1模型家族的学术基准和实际任务上进行了迄今为止最全面的实证研究。通过超过50万次的评估,我们的研究得出几个关键发现:(1)FP8(W8A8-FP)在所有模型规模上都是有效的无损量化;(2)经过良好调优的INT8(W8A8-INT)实现了令人惊讶的低精度下降(1-3%);(3)仅INT4权重(W4A16-INT)比预期的更具竞争力,可与8位量化相媲美。此外,我们通过流行的vLLM框架分析了推理性能,从而研究了不同部署的最佳量化格式。我们的分析提供了明确的部署建议:W4A16是同步设置中最具成本效益的,而W8A8在异步连续批处理中占主导地位。对于混合工作负载,最佳选择取决于具体的用例。我们的发现为大规模部署量化LLM提供了实用的、数据驱动的指导,从而确保了速度、效率和准确性之间的最佳平衡。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)量化过程中,如何在精度、性能和部署成本之间进行权衡的问题。现有方法缺乏对不同量化格式(如FP8、INT8、INT4)在不同模型规模和部署场景下的全面评估,导致难以选择最优的量化方案。
核心思路:论文的核心思路是通过大规模的实证研究,系统地评估不同量化格式在Llama-3.1模型家族上的精度和性能表现。通过分析推理性能,为不同的部署场景提供明确的量化方案选择建议,从而在精度、性能和成本之间取得最佳平衡。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择Llama-3.1模型家族作为研究对象;2) 采用FP8、INT8和INT4等不同的量化格式;3) 在学术基准和实际任务上进行大规模的评估实验,总计超过50万次评估;4) 使用vLLM框架分析不同量化格式的推理性能;5) 根据实验结果和性能分析,为不同的部署场景提供量化方案选择建议。
关键创新:论文的关键创新在于其对LLM量化进行了迄今为止最全面的实证研究。通过大规模的实验,揭示了不同量化格式在不同模型规模和部署场景下的精度-性能权衡关系。此外,论文还为不同的部署场景提供了明确的量化方案选择建议,具有很强的实践指导意义。
关键设计:论文的关键设计包括:1) 选择了Llama-3.1模型家族作为研究对象,保证了研究的代表性;2) 采用了多种量化格式,包括FP8、INT8和INT4,覆盖了不同的精度和性能范围;3) 在学术基准和实际任务上进行了大规模的评估实验,保证了研究结果的可靠性;4) 使用vLLM框架分析推理性能,为部署提供了参考。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FP8量化在所有模型规模上几乎没有精度损失;经过良好调优的INT8量化精度下降仅为1-3%;INT4权重量化在某些场景下可与8位量化相媲美。此外,研究还发现W4A16量化在同步设置中最具成本效益,而W8A8量化在异步连续批处理中表现最佳。
🎯 应用场景
该研究成果可广泛应用于LLM的部署和推理加速,尤其是在资源受限的边缘设备或对延迟敏感的在线服务中。通过选择合适的量化方案,可以在保证模型精度的前提下,显著降低计算成本和内存占用,提高推理速度,从而加速LLM的普及和应用。
📄 摘要(原文)
Quantization is a powerful tool for accelerating large language model (LLM) inference, but the accuracy-performance trade-offs across different formats remain unclear. In this paper, we conduct the most comprehensive empirical study to date, evaluating FP8, INT8, and INT4 quantization across academic benchmarks and real-world tasks on the entire Llama-3.1 model family. Through over 500,000 evaluations, our investigation yields several key findings: (1) FP8 (W8A8-FP) is effectively lossless across all model scales, (2) well-tuned INT8 (W8A8-INT) achieves surprisingly low (1-3\%) accuracy degradation, and (3) INT4 weight-only (W4A16-INT) is more competitive than expected, rivaling 8-bit quantization. Further, we investigate the optimal quantization format for different deployments by analyzing inference performance through the popular vLLM framework. Our analysis provides clear deployment recommendations: W4A16 is the most cost-efficient for synchronous setups, while W8A8 dominates in asynchronous continuous batching. For mixed workloads, the optimal choice depends on the specific use case. Our findings offer practical, data-driven guidelines for deploying quantized LLMs at scale -- ensuring the best balance between speed, efficiency, and accuracy.