Sparsing Law: Towards Large Language Models with Greater Activation Sparsity
作者: Yuqi Luo, Chenyang Song, Xu Han, Yingfa Chen, Chaojun Xiao, Xiaojun Meng, Liqun Deng, Jiansheng Wei, Zhiyuan Liu, Maosong Sun
分类: cs.LG, cs.CL, stat.ML
发布日期: 2024-11-04 (更新: 2025-06-30)
备注: 23 pages, 13 figures, 6 tables
💡 一句话要点
提出PPL-$p\%$稀疏度以提高大语言模型的激活稀疏性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 激活稀疏性 大语言模型 Transformer ReLU SiLU 定量分析 模型效率 深度学习
📋 核心要点
- 现有方法对激活稀疏性与影响因素之间的关系缺乏全面的定量研究,限制了大语言模型的效率提升。
- 论文提出PPL-$p\%$稀疏度指标,旨在精确衡量激活稀疏性,并探讨不同激活函数的表现及其训练时间稀疏趋势。
- 实验结果表明,ReLU激活函数在利用训练数据提升激活稀疏性方面更为高效,且激活稀疏性与参数规模的关系较弱。
📝 摘要(中文)
激活稀疏性指的是激活输出中存在大量弱贡献元素,这些元素可以被消除,从而使大语言模型(LLMs)在多个重要应用中受益。尽管提升LLMs的激活稀疏性值得深入研究,但现有工作缺乏对激活稀疏性与潜在影响因素之间关系的全面定量研究。本文对基于解码器的Transformer LLMs中的激活稀疏性进行了全面研究,提出了PPL-$p\%$稀疏度这一精确且关注性能的激活稀疏度指标,并通过大量实验发现了多个重要现象。
🔬 方法详解
问题定义:本文旨在解决大语言模型中激活稀疏性不足的问题,现有方法未能充分探讨激活稀疏性与影响因素之间的关系,导致模型效率低下。
核心思路:提出PPL-$p\%$稀疏度作为激活稀疏性的度量标准,通过定量分析不同激活函数的表现,探索其与训练数据量及网络结构的关系。
技术框架:研究主要包括激活稀疏度的定义、不同激活函数的比较、训练数据量对激活稀疏性的影响分析,以及宽度-深度比对激活稀疏性的影响。
关键创新:提出的PPL-$p\%$稀疏度指标为激活稀疏性提供了新的定量分析工具,揭示了不同激活函数在训练过程中的稀疏趋势差异,尤其是ReLU在数据利用效率上的优势。
关键设计:研究中对激活函数的选择、训练数据量的变化及网络的宽度-深度比进行了系统的实验设计,确保了结果的可靠性和可重复性。通过对比SiLU和ReLU的表现,明确了激活稀疏性与参数规模的关系。
🖼️ 关键图片
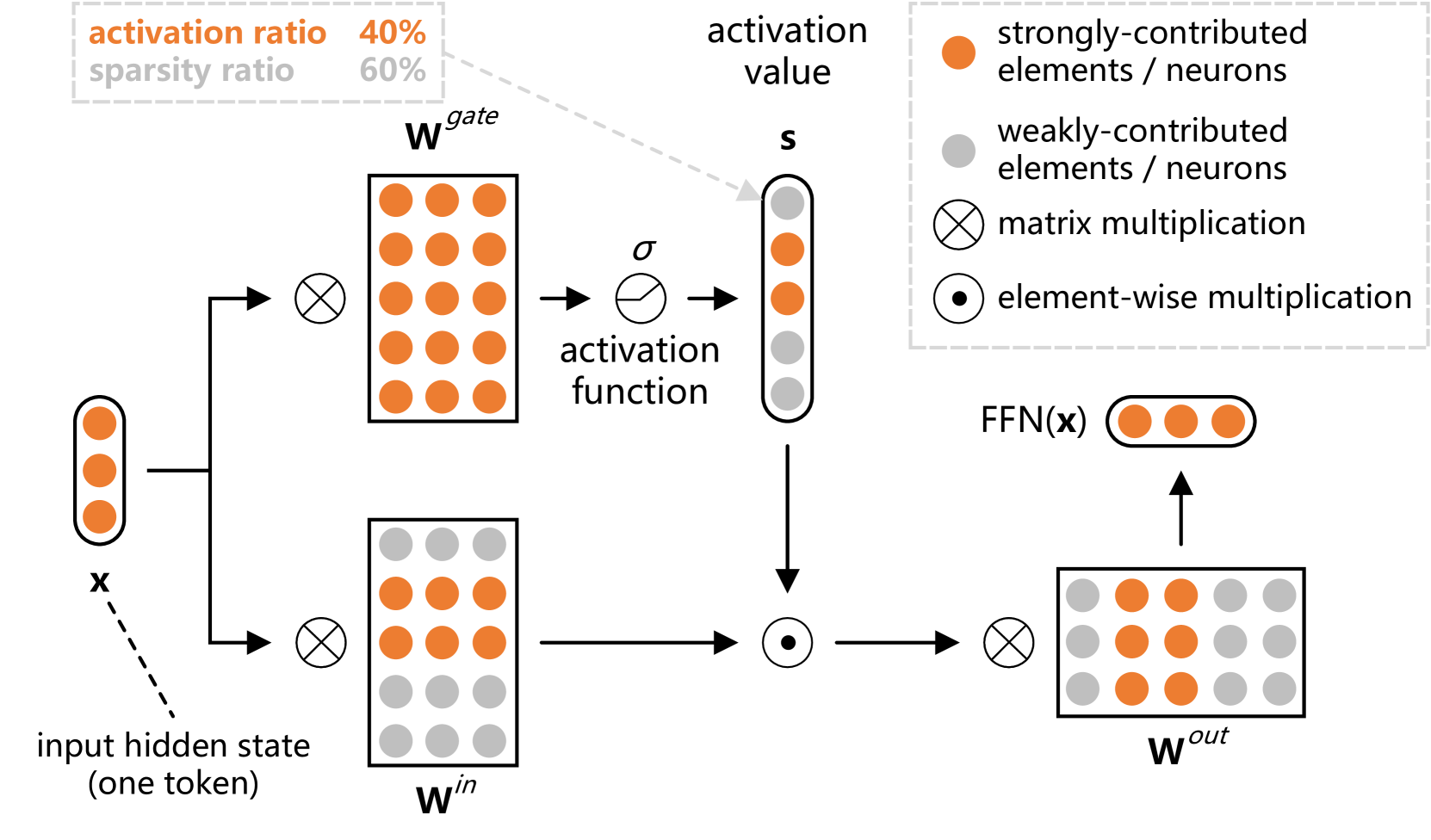
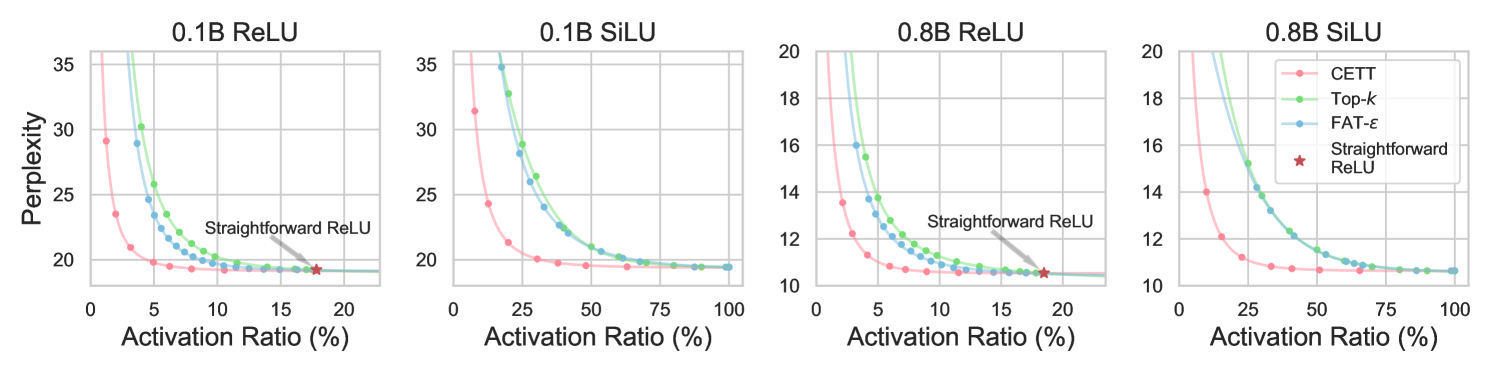

📊 实验亮点
实验结果显示,ReLU激活函数在激活稀疏性提升方面表现优于SiLU,且在训练数据量增加时,激活比率呈现出收敛的幂律增长趋势。此外,激活稀疏性与参数规模的关系较弱,表明模型架构设计的灵活性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和文本生成等,能够帮助提升大语言模型的效率和可解释性,进而推动智能助手、自动翻译等技术的发展。未来,随着激活稀疏性研究的深入,可能会对模型设计和训练方法产生深远影响。
📄 摘要(原文)
Activation sparsity denotes the existence of substantial weakly-contributed elements within activation outputs that can be eliminated, benefiting many important applications concerned with large language models (LLMs). Although promoting greater activation sparsity within LLMs deserves deep studies, existing works lack comprehensive and quantitative research on the correlation between activation sparsity and potentially influential factors. In this paper, we present a comprehensive study on the quantitative scaling properties and influential factors of the activation sparsity within decoder-only Transformer-based LLMs. Specifically, we propose PPL-$p\%$ sparsity, a precise and performance-aware activation sparsity metric that is applicable to any activation function. Through extensive experiments, we find several important phenomena. Firstly, different activation functions exhibit comparable performance but opposite training-time sparsity trends. The activation ratio (i.e., $1-\mathrm{sparsity\ ratio}$) evolves as a convergent increasing power-law and decreasing logspace power-law with the amount of training data for SiLU-activated and ReLU-activated LLMs, respectively. These demonstrate that ReLU is more efficient as the activation function than SiLU and can leverage more training data to improve activation sparsity. Secondly, the activation ratio linearly increases with the width-depth ratio below a certain bottleneck point, indicating the potential advantage of a deeper architecture at a fixed parameter scale. Finally, at similar width-depth ratios, we surprisingly find that the limit value of activation sparsity varies weakly with the parameter scale, i.e., the activation patterns within LLMs are insensitive to the parameter scale. These empirical laws towards LLMs with greater activation sparsity have important implications for making LLMs more efficient and interpretable.