GITSR: Graph Interaction Transformer-based Scene Representation for Multi Vehicle Collaborative Decision-making
作者: Xingyu Hu, Lijun Zhang, Dejian Meng, Ye Han, Lisha Yuan
分类: cs.LG, cs.AI, cs.CV, cs.MA, cs.RO
发布日期: 2024-11-03
💡 一句话要点
提出基于图交互Transformer的场景表示框架GITSR,用于多车协同决策。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 多车协同决策 图交互Transformer 场景表示 智能交通系统 强化学习
📋 核心要点
- 现有方法难以有效建模混合交通环境中车辆间的复杂空间交互,限制了自动驾驶车辆的决策能力。
- GITSR框架利用图交互Transformer,从智能体中心视角进行场景表示,并建模车辆间的空间交互行为。
- 在高速公路匝道场景的仿真实验表明,GITSR方法能有效提升多车协同决策性能,优于基线方法。
📝 摘要(中文)
本研究提出了一种名为GITSR的有效框架,该框架基于图交互Transformer的场景表示,用于智能交通系统中多车辆协同决策。在互联自动驾驶车辆(CAV)和人工驾驶车辆(HDV)共存的混合交通环境中,为了增强CAV对环境的理解以提高决策能力,该框架侧重于高效的场景表示和交通状态空间交互行为的建模。首先,基于智能网络的背景提取驾驶环境的特征。随后,通过Transformer模块计算基于智能体中心和动态占用网格的局部场景表示。此外,通过多头注意力机制捕获地图的可行区域,以减少车辆的碰撞。值得注意的是,基于运动信息的空间交互行为被建模为图结构,并通过图神经网络(GNN)提取。最终,多个车辆之间的协同决策被形式化为马尔可夫决策过程(MDP),并通过强化学习(RL)算法输出驾驶动作。我们的算法验证在极具挑战性的高速公路匝道场景中执行,从而证实了以智能体为中心的场景表示方法的优越性。仿真结果表明,GITSR方法不仅可以有效地捕获场景表示,还可以提取空间交互数据,在各种比较指标上优于基线方法。
🔬 方法详解
问题定义:论文旨在解决混合交通环境中,互联自动驾驶车辆(CAV)如何有效理解周围环境并进行协同决策的问题。现有方法难以充分捕捉车辆间的复杂空间交互关系,导致决策效率和安全性受限。尤其是在高速公路匝道等复杂场景下,这一问题更为突出。
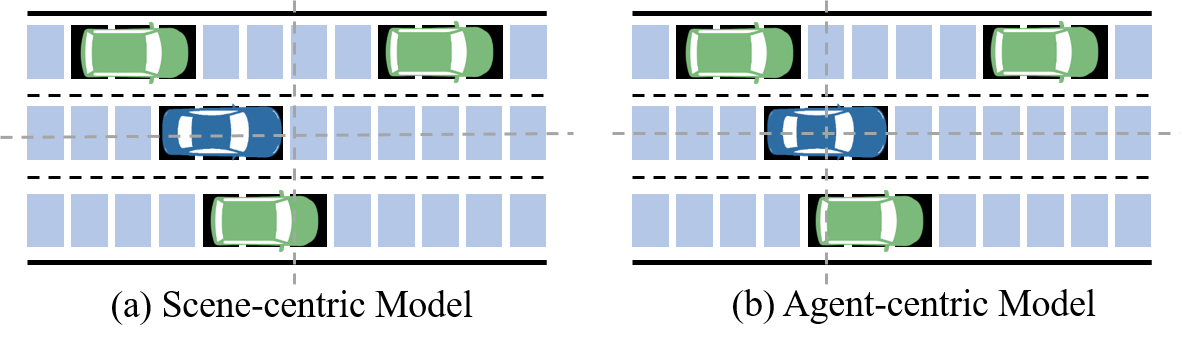
核心思路:论文的核心思路是利用图交互Transformer来构建场景表示,并显式地建模车辆间的空间交互行为。通过以智能体为中心的视角,结合Transformer的全局感知能力和图神经网络(GNN)的关系建模能力,更全面地理解交通场景。
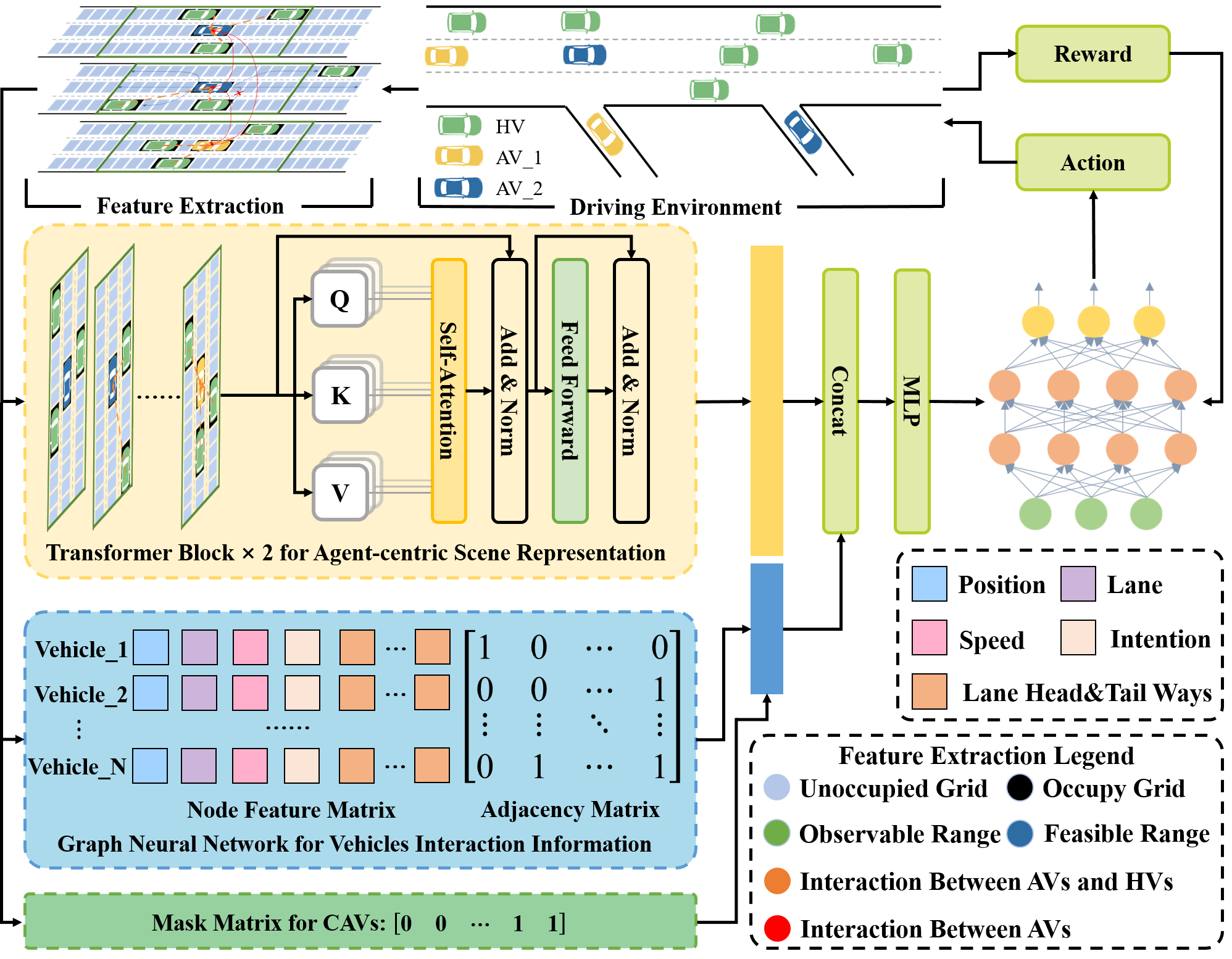
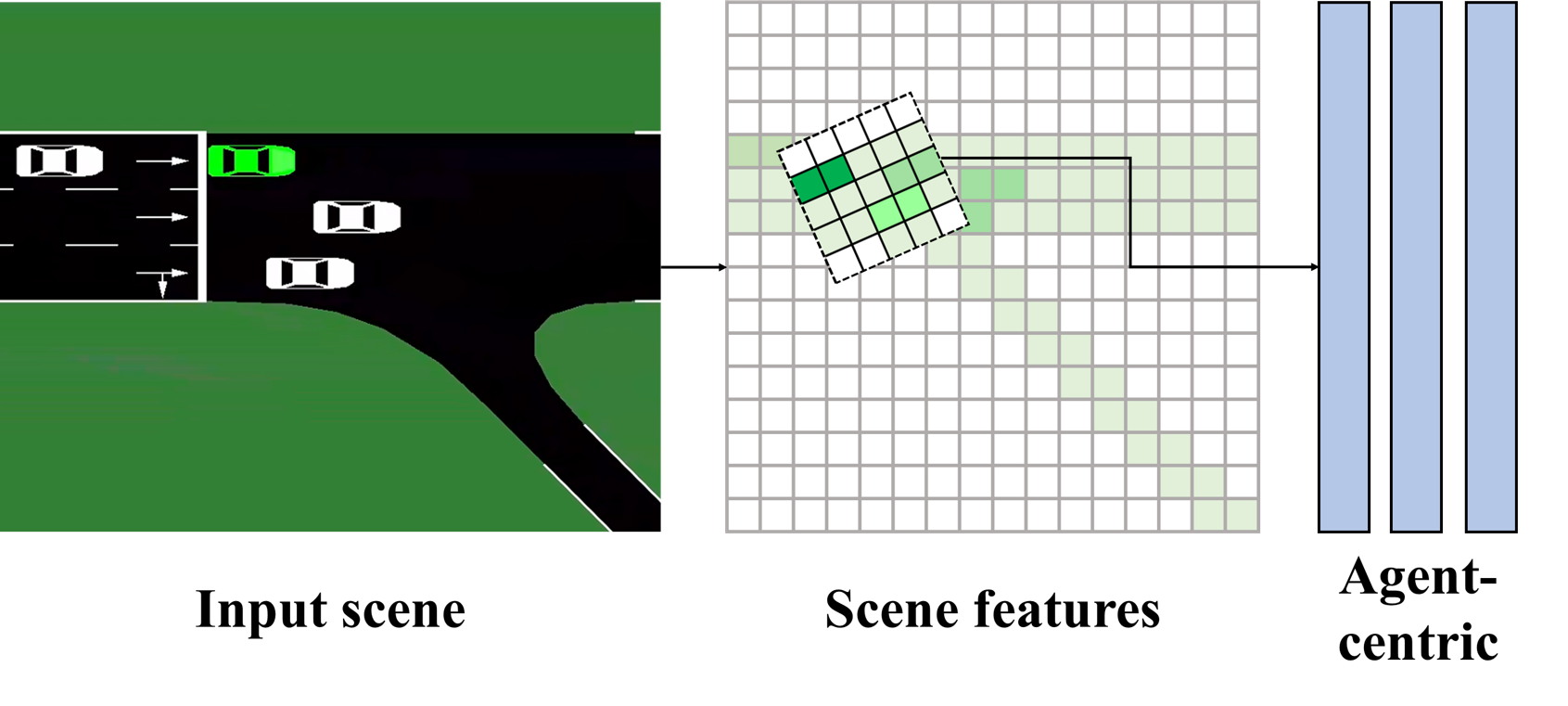
技术框架:GITSR框架主要包含以下几个模块:1) 特征提取模块:提取驾驶环境的特征,包括车辆状态、道路信息等。2) 局部场景表示模块:利用Transformer模块,基于智能体中心和动态占用网格,计算局部场景表示。3) 可行区域捕获模块:通过多头注意力机制,捕获地图的可行区域,避免碰撞。4) 空间交互建模模块:将车辆间的运动信息建模为图结构,利用GNN提取空间交互信息。5) 决策模块:将协同决策问题建模为马尔可夫决策过程(MDP),利用强化学习(RL)算法输出驾驶动作。
关键创新:GITSR的关键创新在于:1) 提出了基于图交互Transformer的场景表示方法,能够有效建模车辆间的空间交互行为。2) 采用智能体中心的视角,更符合自动驾驶车辆的感知方式。3) 利用多头注意力机制捕获可行区域,提高了决策的安全性。
关键设计:论文中一些关键设计包括:1) 使用动态占用网格来表示局部场景,能够适应不同场景的动态变化。2) 利用GNN建模车辆间的空间关系,能够捕捉复杂的交互模式。3) 将协同决策问题建模为MDP,并使用强化学习算法进行求解,能够实现自主学习和优化。
🖼️ 关键图片
📊 实验亮点
论文在高速公路匝道场景下进行了仿真实验,结果表明GITSR方法能够有效捕获场景表示并提取空间交互数据,在各项指标上均优于基线方法。具体性能提升数据未知,但结论表明了以智能体为中心的场景表示方法的优越性。
🎯 应用场景
该研究成果可应用于智能交通系统中的自动驾驶车辆协同决策,尤其是在复杂交通场景如高速公路、城市交叉口等。通过提升自动驾驶车辆对环境的理解和协同能力,可以提高交通效率、减少交通事故,并为未来的智能交通管理提供技术支撑。
📄 摘要(原文)
In this study, we propose GITSR, an effective framework for Graph Interaction Transformer-based Scene Representation for multi-vehicle collaborative decision-making in intelligent transportation system. In the context of mixed traffic where Connected Automated Vehicles (CAVs) and Human Driving Vehicles (HDVs) coexist, in order to enhance the understanding of the environment by CAVs to improve decision-making capabilities, this framework focuses on efficient scene representation and the modeling of spatial interaction behaviors of traffic states. We first extract features of the driving environment based on the background of intelligent networking. Subsequently, the local scene representation, which is based on the agent-centric and dynamic occupation grid, is calculated by the Transformer module. Besides, feasible region of the map is captured through the multi-head attention mechanism to reduce the collision of vehicles. Notably, spatial interaction behaviors, based on motion information, are modeled as graph structures and extracted via Graph Neural Network (GNN). Ultimately, the collaborative decision-making among multiple vehicles is formulated as a Markov Decision Process (MDP), with driving actions output by Reinforcement Learning (RL) algorithms. Our algorithmic validation is executed within the extremely challenging scenario of highway off-ramp task, thereby substantiating the superiority of agent-centric approach to scene representation. Simulation results demonstrate that the GITSR method can not only effectively capture scene representation but also extract spatial interaction data, outperforming the baseline method across various comparative metrics.