Inducing Semi-Structured Sparsity by Masking for Efficient Model Inference in Convolutional Networks
作者: David A. Danhofer
分类: cs.LG, cs.AI, cs.CV, cs.NE, cs.PF
发布日期: 2024-11-01
备注: 15 pages, 3 figures; this work will be presented at the NeurIPS 2024 Workshop on Fine-Tuning in Modern Machine Learning: Principles and Scalability (FITML)
💡 一句话要点
提出基于掩码的半结构化稀疏方法,加速卷积神经网络推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 卷积神经网络 模型加速 半结构化稀疏 掩码学习 模型推理 硬件加速 模型优化
📋 核心要点
- 卷积模型加速是关键,但现有方法难以兼顾效率、精度和易更新性。
- 通过学习卷积核的半结构化稀疏掩码,实现硬件友好的加速,同时保持模型结构不变。
- 实验表明,该方法在不损失性能的情况下,可将推理速度提高两倍以上,且模型易于更新。
📝 摘要(中文)
卷积模型在视觉任务和基础模型中扮演着关键角色,因此高效的加速技术至关重要。本文提出了一种新颖的方法,通过掩码学习卷积核的半结构化稀疏模式,从而能够利用现有的硬件加速。该方法在不降低模型性能的前提下,将卷积模型的推理速度提高了两倍以上。同时,原始模型权重和结构保持不变,使得模型易于更新。此外,掩码对预测的影响易于量化。因此,推导出了掩码下模型预测的保证,即使在更新原始底层模型后,也能显示学习到的掩码的稳定性界限。
🔬 方法详解
问题定义:论文旨在解决卷积神经网络在推理过程中计算量大、速度慢的问题。现有方法,如剪枝和量化,虽然可以减少计算量,但通常需要修改模型结构或权重,导致模型难以更新,并且可能引入精度损失。此外,非结构化稀疏难以有效利用现有硬件加速器。
核心思路:论文的核心思路是通过学习卷积核的半结构化稀疏掩码,在推理时屏蔽掉部分卷积核的计算,从而减少计算量,加速推理。这种方法不需要修改原始模型权重和结构,因此模型易于更新。半结构化稀疏模式的设计,使得可以更容易地利用现有硬件加速器。
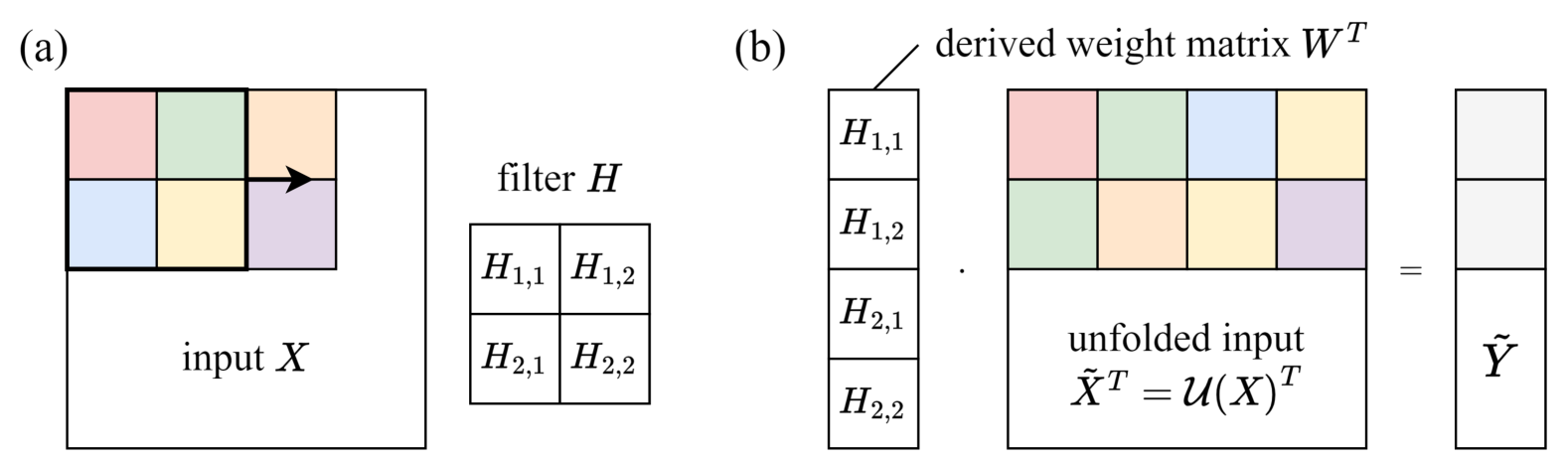
技术框架:该方法主要包含两个阶段:1) 掩码学习阶段:通过训练学习卷积核的半结构化稀疏掩码。2) 推理阶段:将学习到的掩码应用于卷积核,屏蔽掉部分计算,加速推理。在掩码学习阶段,可以使用各种优化算法来训练掩码,例如梯度下降。
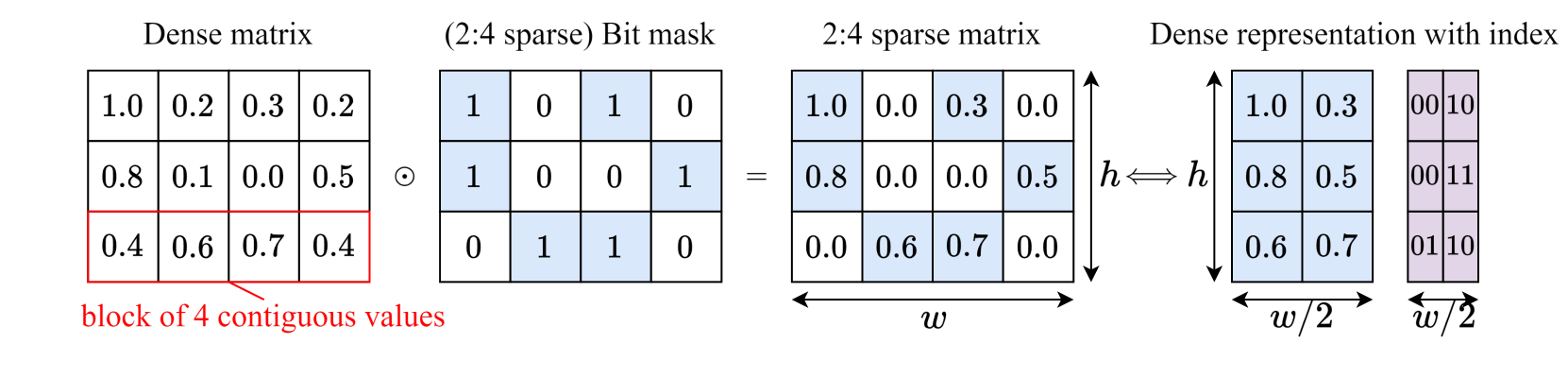
关键创新:该方法最重要的技术创新点在于提出了半结构化稀疏掩码的概念,并设计了一种学习半结构化稀疏掩码的方法。与传统的非结构化稀疏相比,半结构化稀疏更容易利用现有硬件加速器。与需要修改模型结构或权重的剪枝和量化方法相比,该方法不需要修改原始模型,因此模型易于更新。
关键设计:论文的关键设计包括:1) 半结构化稀疏模式的选择:论文选择了一种适合现有硬件加速器的半结构化稀疏模式。2) 掩码学习的损失函数设计:论文设计了一种损失函数,用于学习能够有效减少计算量并保持模型精度的掩码。3) 掩码更新策略:论文提出了一种掩码更新策略,即使在更新原始底层模型后,也能保证学习到的掩码的稳定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在不降低模型性能的前提下,可以将卷积模型的推理速度提高两倍以上。与传统的剪枝和量化方法相比,该方法不需要修改原始模型权重和结构,因此模型易于更新。此外,论文还推导出了掩码下模型预测的保证,即使在更新原始底层模型后,也能显示学习到的掩码的稳定性界限。
🎯 应用场景
该研究成果可广泛应用于各种需要加速卷积神经网络推理的场景,例如移动设备、嵌入式系统和云计算平台。通过加速卷积神经网络的推理,可以提高这些场景下的应用性能,例如图像识别、目标检测和语义分割。此外,该方法还可以应用于基础模型,提高其推理效率,从而降低计算成本。
📄 摘要(原文)
The crucial role of convolutional models, both as standalone vision models and backbones in foundation models, necessitates effective acceleration techniques. This paper proposes a novel method to learn semi-structured sparsity patterns for convolution kernels in the form of maskings enabling the utilization of readily available hardware accelerations. The approach accelerates convolutional models more than two-fold during inference without decreasing model performance. At the same time, the original model weights and structure remain unchanged keeping the model thus easily updatable. Beyond the immediate practical use, the effect of maskings on prediction is easily quantifiable. Therefore, guarantees on model predictions under maskings are derived showing stability bounds for learned maskings even after updating the original underlying model.