LLM-Inference-Bench: Inference Benchmarking of Large Language Models on AI Accelerators
作者: Krishna Teja Chitty-Venkata, Siddhisanket Raskar, Bharat Kale, Farah Ferdaus, Aditya Tanikanti, Ken Raffenetti, Valerie Taylor, Murali Emani, Venkatram Vishwanath
分类: cs.LG
发布日期: 2024-10-31
💡 一句话要点
LLM-Inference-Bench:用于AI加速器上大语言模型推理的基准测试套件
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理性能 AI加速器 基准测试 硬件平台
📋 核心要点
- 现有大语言模型推理对算力需求高,缺乏系统性的硬件平台性能评估工具。
- LLM-Inference-Bench提供全面的基准测试,评估不同硬件平台上的LLM推理性能。
- 通过对多种硬件、模型和框架的分析,揭示了各自的优劣,并提供优化配置建议。
📝 摘要(中文)
大语言模型(LLMs)推动了多个领域的突破性进展,并广泛应用于文本生成。然而,这些复杂模型的计算需求带来了重大挑战,需要高效的硬件加速。对LLMs在不同硬件平台上的性能进行基准测试,对于理解其可扩展性和吞吐量特性至关重要。我们推出了LLM-Inference-Bench,这是一个全面的基准测试套件,用于评估LLMs的硬件推理性能。我们深入分析了包括Nvidia和AMD的GPU以及Intel Habana和SambaNova等专用AI加速器在内的多种硬件平台。我们的评估包括来自LLaMA、Mistral和Qwen系列的7B和70B参数的多个LLM推理框架和模型。我们的基准测试结果揭示了各种模型、硬件平台和推理框架的优势和局限性。我们提供了一个交互式仪表板,以帮助识别给定硬件平台的最佳性能配置。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)在不同AI加速硬件平台上的推理性能评估问题。现有方法缺乏一个统一、全面的基准测试套件,难以有效比较不同硬件平台(如GPU、专用AI加速器)上不同LLM模型和推理框架的性能,从而阻碍了LLM在实际应用中的部署和优化。现有方法难以提供针对特定硬件平台的最佳配置建议。
核心思路:论文的核心思路是构建一个全面的基准测试套件LLM-Inference-Bench,该套件能够系统性地评估不同硬件平台上的LLM推理性能。通过对多种LLM模型、推理框架和硬件平台的组合进行测试,揭示它们的优势和局限性,并提供一个交互式仪表板,帮助用户找到针对特定硬件平台的最佳配置。
技术框架:LLM-Inference-Bench的整体框架包含以下几个主要模块:1) 模型库:包含来自LLaMA、Mistral和Qwen等系列的多种LLM模型,涵盖7B和70B参数规模。2) 硬件平台:支持多种硬件平台,包括Nvidia和AMD的GPU,以及Intel Habana和SambaNova等专用AI加速器。3) 推理框架:支持多种LLM推理框架。4) 基准测试:提供多种基准测试用例,用于评估LLM在不同硬件平台上的推理性能。5) 交互式仪表板:提供一个交互式仪表板,用于展示基准测试结果,并帮助用户找到针对特定硬件平台的最佳配置。
关键创新:该论文的关键创新在于构建了一个全面的、易于使用的LLM推理基准测试套件,能够系统性地评估不同硬件平台上的LLM推理性能。与现有方法相比,LLM-Inference-Bench覆盖了更广泛的LLM模型、推理框架和硬件平台,并提供了一个交互式仪表板,方便用户进行性能分析和优化。
关键设计:LLM-Inference-Bench的关键设计包括:1) 选择具有代表性的LLM模型,涵盖不同参数规模和架构。2) 支持多种主流的硬件平台和推理框架。3) 设计合理的基准测试用例,能够全面评估LLM在不同硬件平台上的推理性能。4) 开发交互式仪表板,方便用户进行性能分析和优化。具体的参数设置、损失函数、网络结构等技术细节取决于所使用的LLM模型和推理框架。
🖼️ 关键图片
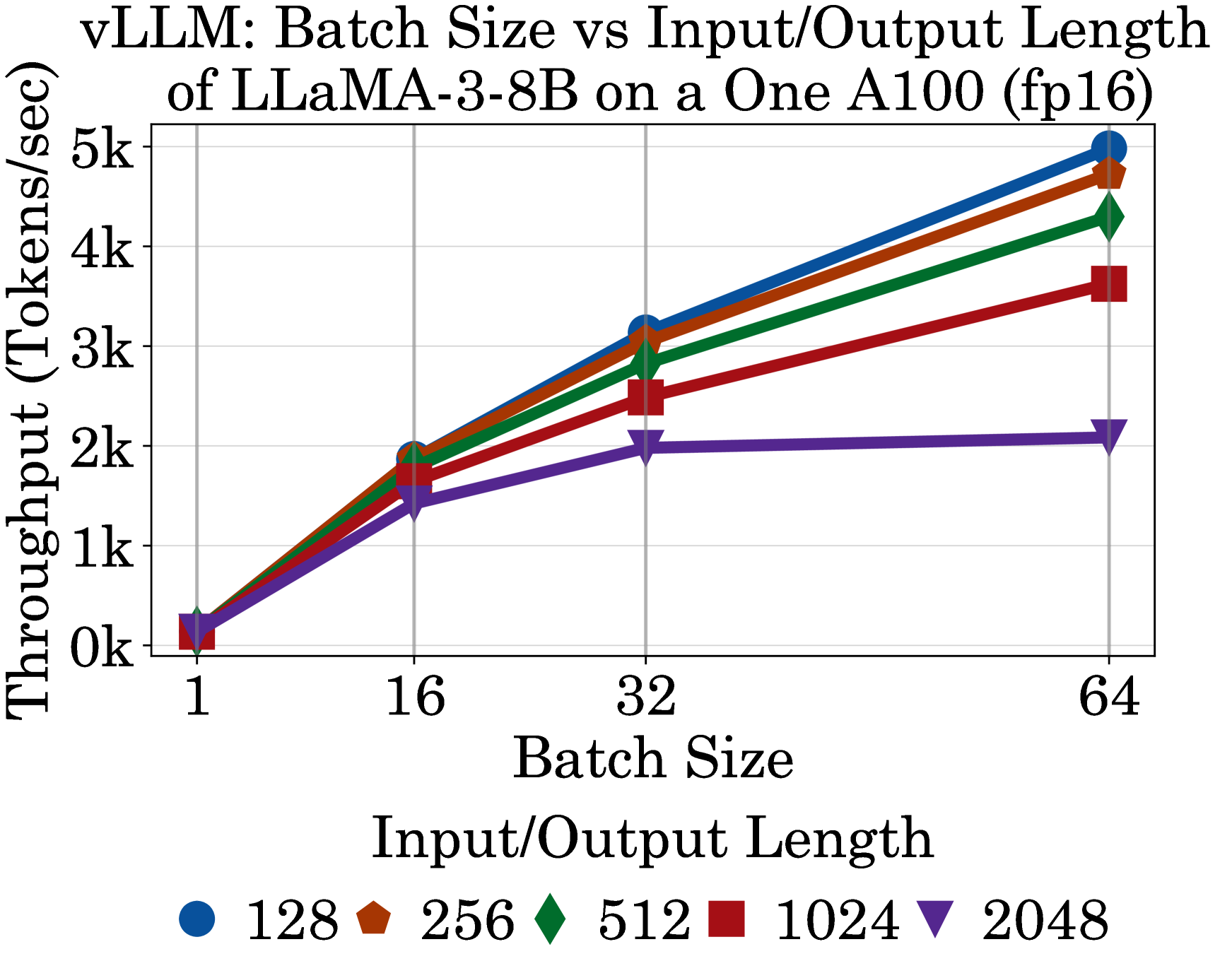
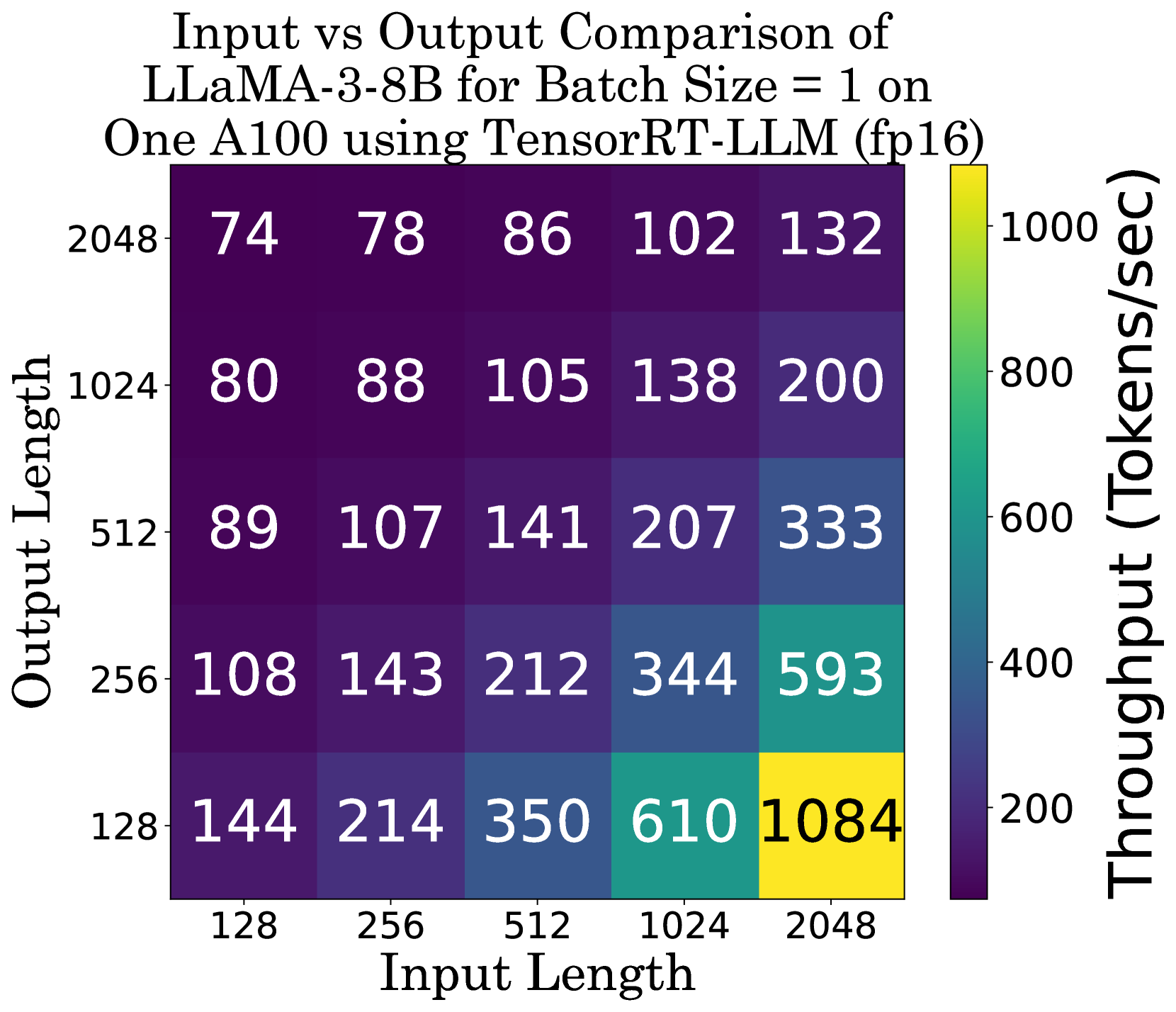
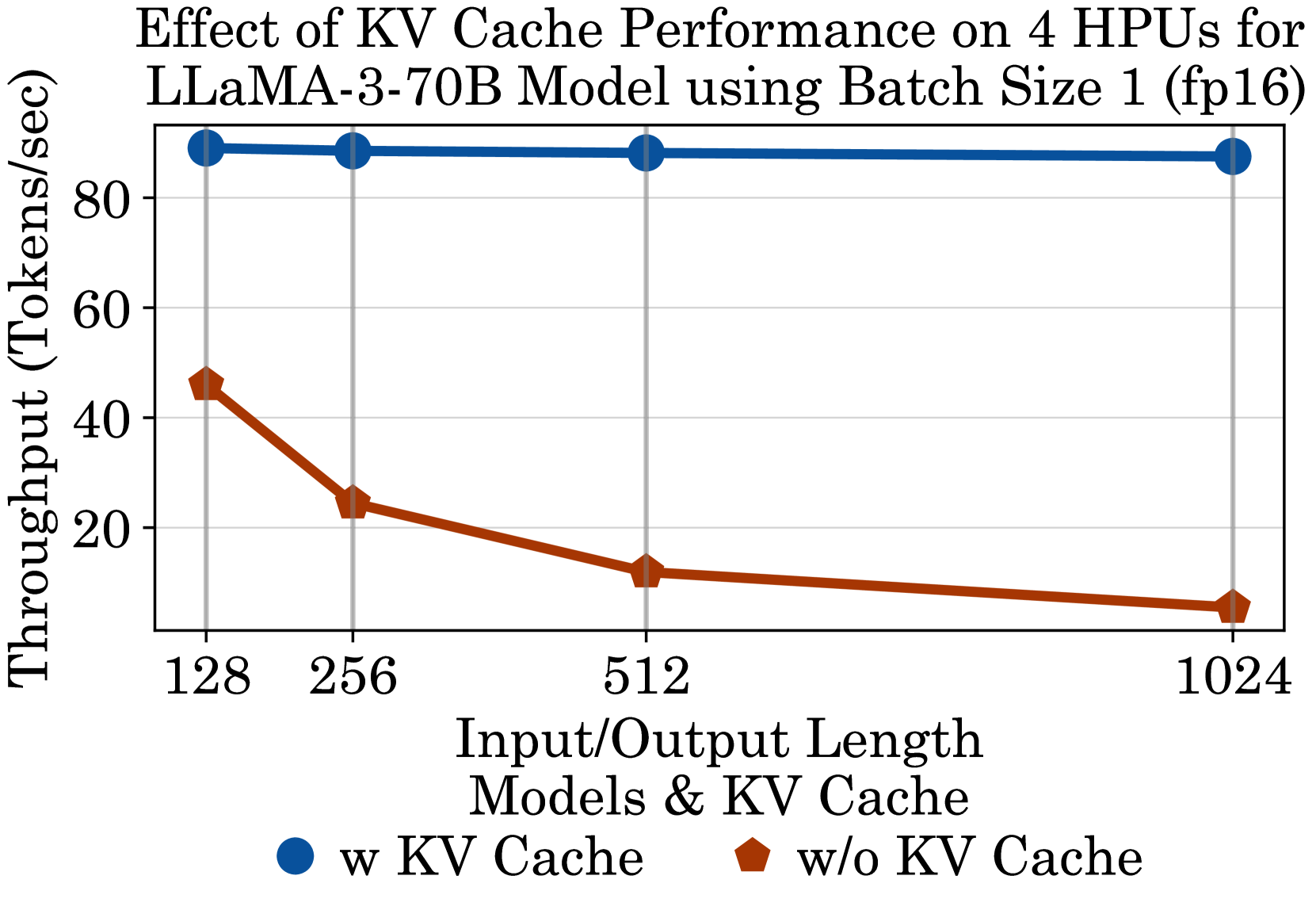
📊 实验亮点
实验结果表明,不同硬件平台在不同LLM模型和推理框架下的性能差异显著。例如,某些专用AI加速器在特定模型上的推理速度明显优于GPU,但可能在其他模型上表现不佳。该基准测试套件提供的数据可以帮助用户选择最适合其需求的硬件平台和推理框架,从而实现最佳的性能和效率。
🎯 应用场景
该研究成果可广泛应用于AI加速器设计、LLM部署优化、以及为用户选择合适的硬件平台提供参考。通过LLM-Inference-Bench,研究人员和工程师可以更好地理解不同硬件平台上的LLM推理性能,从而优化模型部署,降低计算成本,加速LLM在各个领域的应用,例如自然语言处理、智能客服、内容生成等。
📄 摘要(原文)
Large Language Models (LLMs) have propelled groundbreaking advancements across several domains and are commonly used for text generation applications. However, the computational demands of these complex models pose significant challenges, requiring efficient hardware acceleration. Benchmarking the performance of LLMs across diverse hardware platforms is crucial to understanding their scalability and throughput characteristics. We introduce LLM-Inference-Bench, a comprehensive benchmarking suite to evaluate the hardware inference performance of LLMs. We thoroughly analyze diverse hardware platforms, including GPUs from Nvidia and AMD and specialized AI accelerators, Intel Habana and SambaNova. Our evaluation includes several LLM inference frameworks and models from LLaMA, Mistral, and Qwen families with 7B and 70B parameters. Our benchmarking results reveal the strengths and limitations of various models, hardware platforms, and inference frameworks. We provide an interactive dashboard to help identify configurations for optimal performance for a given hardware platform.