In-Context Fine-Tuning for Time-Series Foundation Models
作者: Abhimanyu Das, Matthew Faw, Rajat Sen, Yichen Zhou
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-10-31
💡 一句话要点
提出时间序列基础模型的上下文微调方法,提升零样本预测性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 基础模型 上下文学习 零样本学习 Transformer
📋 核心要点
- 现有时间序列预测方法难以适应新领域,零样本预测能力不足,泛化性受限。
- 设计可利用上下文信息的时间序列基础模型,通过多个相关时间序列示例进行提示,适应目标领域。
- 实验表明,该方法在预测精度上优于传统方法和现有基础模型,接近显式微调的效果。
📝 摘要(中文)
本文提出了一种时间序列基础模型的上下文微调方法,旨在提升零样本预测能力。该方法设计了一个预训练的基础模型,该模型可以在推理时通过多个时间序列示例进行提示,从而预测目标时间序列的未来值。该基础模型经过专门训练,可以利用上下文窗口中的多个相关时间序列示例(以及目标时间序列的历史记录),以便在推理时适应目标领域的特定分布。实验结果表明,与监督深度学习方法、统计模型以及其他时间序列基础模型相比,使用上下文示例的基础模型在流行的预测基准测试中可以获得更好的性能。有趣的是,本文提出的上下文微调方法甚至可以与在目标领域上进行显式微调的基础模型的性能相媲美。
🔬 方法详解
问题定义:现有的时间序列预测方法,包括传统的统计模型和深度学习模型,通常需要大量的目标领域数据进行训练才能获得良好的性能。当面对新的领域或数据集时,这些模型往往表现不佳,泛化能力有限。时间序列基础模型旨在通过预训练学习通用的时间序列表示,从而实现零样本或少样本预测,但如何有效地利用上下文信息来提升其在特定领域的预测精度仍然是一个挑战。
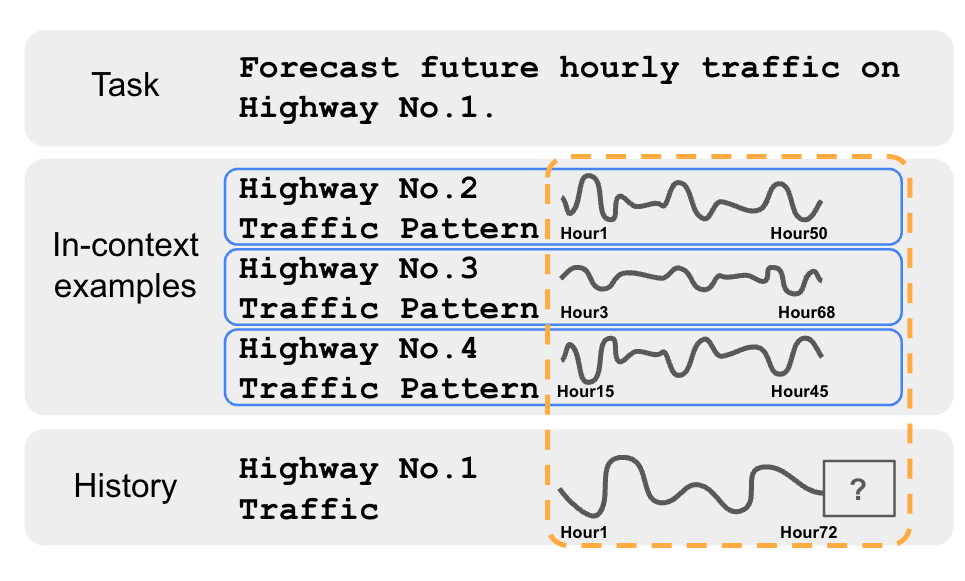
核心思路:本文的核心思路是利用上下文学习(In-Context Learning)的思想,设计一个可以接受多个时间序列作为上下文输入的基础模型。该模型通过学习如何利用这些上下文信息,来更好地适应目标时间序列的特定分布,从而提高预测精度。这种方法避免了在目标领域进行显式微调,降低了对目标领域数据的依赖。
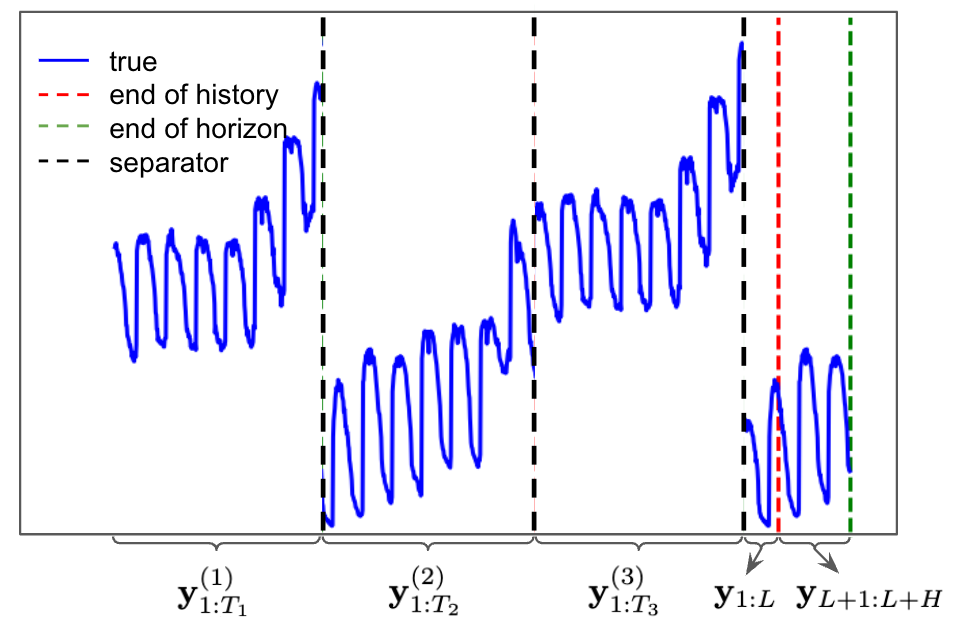
技术框架:该方法包含两个主要阶段:预训练阶段和推理阶段。在预训练阶段,模型在一个大规模的时间序列数据集上进行训练,学习通用的时间序列表示和上下文学习能力。在推理阶段,模型接收目标时间序列的历史数据以及若干个相关时间序列作为上下文输入,然后预测目标时间序列的未来值。模型的整体架构基于Transformer,利用自注意力机制来捕捉时间序列之间的依赖关系和上下文信息。
关键创新:本文的关键创新在于将上下文学习的思想引入到时间序列基础模型中,并设计了一种有效的上下文微调方法。与传统的微调方法相比,该方法不需要在目标领域进行显式训练,而是通过在推理时利用上下文信息来实现模型的自适应。这种方法可以显著提高模型的泛化能力和零样本预测性能。
关键设计:在预训练阶段,作者设计了一个特殊的训练目标,鼓励模型学习如何利用上下文信息进行预测。具体来说,模型需要根据目标时间序列的历史数据和上下文时间序列,预测目标时间序列的未来值。在推理阶段,作者采用了一种基于相似度的上下文选择策略,选择与目标时间序列最相关的上下文时间序列作为输入。此外,作者还探索了不同的上下文窗口大小和Transformer的层数等超参数,以优化模型的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,本文提出的上下文微调方法在多个流行的预测基准测试中取得了显著的性能提升。例如,在M5数据集上,该方法优于传统的统计模型和深度学习模型,并且与在目标领域上进行显式微调的基础模型相比,性能相当甚至略有提升。此外,该方法在零样本预测任务中也表现出色,证明了其良好的泛化能力。
🎯 应用场景
该研究成果可广泛应用于各种时间序列预测场景,如金融市场预测、供应链管理、能源需求预测、医疗健康监测等。通过利用相关时间序列的上下文信息,可以提高预测精度,降低对目标领域数据的依赖,从而为决策提供更可靠的依据。该方法还有助于推动时间序列基础模型的发展,促进时间序列分析技术的普及应用。
📄 摘要(原文)
Motivated by the recent success of time-series foundation models for zero-shot forecasting, we present a methodology for $\textit{in-context fine-tuning}$ of a time-series foundation model. In particular, we design a pretrained foundation model that can be prompted (at inference time) with multiple time-series examples, in order to forecast a target time-series into the future. Our foundation model is specifically trained to utilize examples from multiple related time-series in its context window (in addition to the history of the target time-series) to help it adapt to the specific distribution of the target domain at inference time. We show that such a foundation model that uses in-context examples at inference time can obtain much better performance on popular forecasting benchmarks compared to supervised deep learning methods, statistical models, as well as other time-series foundation models. Interestingly, our in-context fine-tuning approach even rivals the performance of a foundation model that is explicitly fine-tuned on the target domain.