COMAL: A Convergent Meta-Algorithm for Aligning LLMs with General Preferences
作者: Yixin Liu, Argyris Oikonomou, Weiqiang Zheng, Yang Cai, Arman Cohan
分类: cs.LG, cs.AI, cs.CL, cs.GT
发布日期: 2024-10-30 (更新: 2025-10-13)
💡 一句话要点
COMAL:一种用于对齐LLM与通用偏好的收敛元算法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大型语言模型对齐 强化学习 人类反馈 博弈论 纳什均衡 偏好优化 元算法
📋 核心要点
- 现有RLHF方法依赖于Bradley-Terry奖励假设,难以捕捉复杂的人类偏好。
- COMAL将对齐问题建模为双人零和博弈,寻找保证50%胜率的纳什均衡策略。
- COMAL在合成和偏好优化数据集上表现出优越性能,胜率高于其他算法。
📝 摘要(中文)
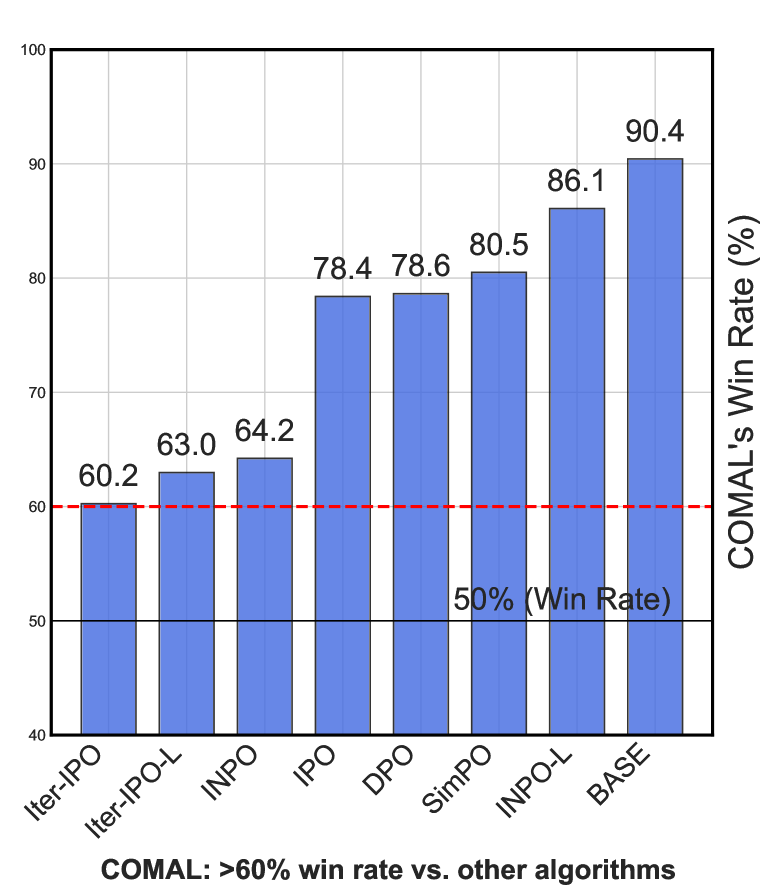
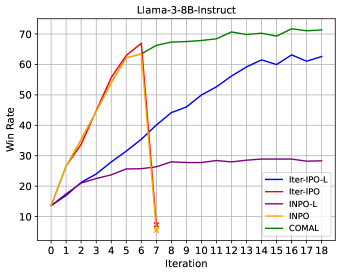
许多对齐方法,包括基于人类反馈的强化学习(RLHF),都依赖于Bradley-Terry奖励假设,但这并不总是足以捕捉通用人类偏好的全部范围和复杂性。本文通过在博弈论框架中将对齐问题建模为一个双人零和博弈,探索了通用偏好框架下的RLHF,其中纳什均衡策略保证了针对任何竞争策略的50%胜率。然而,先前用于寻找纳什策略的自博弈算法要么发散,要么仅收敛到修改后的博弈中的纳什策略,即使在简单的合成环境中也是如此,从而未能维持针对所有其他策略的50%胜率保证。本文提出了一种元算法,即收敛元对齐算法(COMAL),用于使用通用偏好对齐语言模型,其灵感来自博弈论中的收敛算法。本文提供了理论分析,表明该元算法在最后一次迭代中收敛到精确的纳什策略,并在一系列合成和偏好优化数据集上证明了其有效性。COMAL很简单,可以与许多现有的偏好优化方法集成,只需进行最小的更改,并且在受控评估中,当应用于Llama-3-8B-Instruct和Qwen2.5-7B时,经验证始终保持高于60.2%和56.8%的胜率,优于所有比较算法。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习(RLHF)方法在对齐大型语言模型(LLM)时,通常依赖于Bradley-Terry奖励模型。该模型假设人类偏好可以用成对比较的概率来表示,但这种假设可能过于简化,无法捕捉人类偏好的复杂性和多样性。因此,现有的RLHF方法可能无法有效地将LLM与通用的人类偏好对齐。
核心思路:COMAL的核心思路是将LLM的对齐问题建模为一个双人零和博弈。在这个博弈中,一个玩家(例如,LLM)试图最大化其奖励,而另一个玩家(例如,对抗策略)试图最小化该奖励。通过寻找这个博弈的纳什均衡,可以找到一个策略,该策略能够保证针对任何其他策略的50%胜率。这种方法不依赖于Bradley-Terry奖励模型,因此可以更好地处理复杂的人类偏好。
技术框架:COMAL的整体框架包括以下几个主要步骤:1) 使用现有的偏好优化方法(例如,RLHF)训练一个初始策略。2) 使用自博弈算法生成对抗策略。3) 使用收敛元算法更新策略,使其更接近纳什均衡。4) 重复步骤2和3,直到策略收敛。该框架可以与许多现有的偏好优化方法集成,只需进行最小的更改。
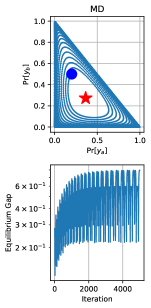
关键创新:COMAL的关键创新在于其使用收敛元算法来寻找纳什均衡。传统的自博弈算法通常无法保证收敛到纳什均衡,或者只能收敛到修改后的博弈中的纳什均衡。COMAL使用一种新的元算法,该算法基于博弈论中的收敛算法,可以保证在最后一次迭代中收敛到精确的纳什策略。
关键设计:COMAL的关键设计包括:1) 使用一种新的损失函数,该损失函数鼓励策略接近纳什均衡。2) 使用一种新的更新规则,该更新规则可以保证策略的收敛性。3) 使用一种新的对抗策略生成方法,该方法可以生成更有效的对抗策略。具体的参数设置和网络结构取决于所使用的偏好优化方法和LLM的架构。
🖼️ 关键图片
📊 实验亮点
COMAL在合成和偏好优化数据集上进行了广泛的实验。实验结果表明,COMAL可以有效地将LLM与通用偏好对齐,并且优于现有的RLHF方法。具体来说,当应用于Llama-3-8B-Instruct和Qwen2.5-7B时,COMAL始终保持高于60.2%和56.8%的胜率,优于所有比较算法。这些结果表明,COMAL是一种有效的LLM对齐方法。
🎯 应用场景
COMAL具有广泛的应用前景,可以用于对齐各种LLM,使其更好地满足人类的需求和偏好。例如,可以用于改进LLM的安全性、可靠性和有用性。此外,COMAL还可以应用于其他领域,例如机器人控制和推荐系统,以提高这些系统的性能和鲁棒性。该研究的未来影响在于推动LLM对齐技术的发展,使其能够更好地服务于人类社会。
📄 摘要(原文)
Many alignment methods, including reinforcement learning from human feedback (RLHF), rely on the Bradley-Terry reward assumption, which is not always sufficient to capture the full range and complexity of general human preferences. We explore RLHF under a general preference framework by modeling the alignment problem as a two-player zero-sum game in a game-theoretic framework, where the Nash equilibrium policy guarantees a 50% win rate against any competing policy. However, previous self-play algorithms for finding the Nash policy either diverge or only converge to a Nash policy in a modified game, even in a simple synthetic setting, thereby failing to maintain the 50% win rate guarantee against all other policies. We propose a meta-algorithm, Convergent Meta Alignment Algorithm (COMAL), for language model alignment with general preferences, inspired by convergent algorithms in game theory. We provide theoretical analysis that our meta-algorithm converges to an exact Nash policy in the last iterate and demonstrate its effectiveness on a range of synthetic and preference optimization datasets. COMAL is simple and can be integrated with many existing methods designed for preference optimization with minimal changes, and empirically it consistently maintains above 60.2% and 56.8% win rates, when applied to Llama-3-8B-Instruct and Qwen2.5-7B, against all compared algorithms under controlled evaluations.