Online Intrinsic Rewards for Decision Making Agents from Large Language Model Feedback
作者: Qinqing Zheng, Mikael Henaff, Amy Zhang, Aditya Grover, Brandon Amos
分类: cs.LG, cs.AI, cs.CL, cs.RO
发布日期: 2024-10-30 (更新: 2025-10-23)
备注: RLC 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出ONI:利用大语言模型反馈在线生成决策智能体的内在奖励
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 内在奖励 大语言模型 在线学习 分布式架构
📋 核心要点
- 现有强化学习方法在稀疏奖励、开放探索等任务中面临挑战,依赖大量标注或离线数据,限制了其应用。
- ONI通过分布式架构,利用异步LLM服务器对智能体经验进行标注,并提炼为内在奖励模型,实现策略和奖励函数的同步学习。
- ONI在NetHack等复杂任务中取得了领先性能,无需大型离线数据集,验证了其有效性和可扩展性。
📝 摘要(中文)
本文提出了一种利用大语言模型(LLM)反馈自动合成密集奖励的强化学习(RL)范式,旨在解决稀疏奖励问题、开放式探索和分层技能设计等挑战。现有方法虽然利用了LLM的先验知识,但要么因需要对每个观察进行LLM标注而无法扩展到需要数十亿环境样本的问题,要么需要多样化的离线数据集,而这些数据集可能不存在或无法收集。本文通过算法和系统层面的贡献解决了这些限制。我们提出了ONI,一种分布式架构,它使用LLM反馈同时学习RL策略和内在奖励函数。我们的方法通过异步LLM服务器标注智能体收集的经验,然后将其提炼成内在奖励模型。我们探索了一系列具有不同复杂度的奖励建模算法选择,包括哈希、分类和排序模型。我们的方法在NetHack学习环境中的一系列具有挑战性的任务中实现了最先进的性能,同时消除了先前工作所需的大型离线数据集。
🔬 方法详解
问题定义:现有强化学习方法在处理稀疏奖励环境时面临挑战。传统的强化学习算法依赖于明确定义的奖励函数,但在许多实际应用中,奖励信号非常稀疏甚至缺失,导致智能体难以学习有效的策略。此外,一些方法需要大量的离线数据集进行预训练,这限制了它们在数据收集成本高昂或无法收集到足够数据的场景中的应用。
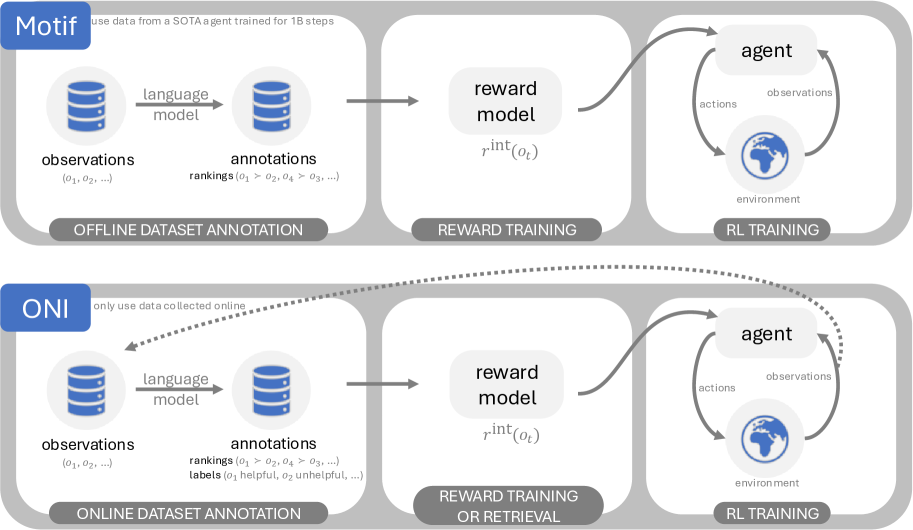
核心思路:本文的核心思路是利用大语言模型(LLM)的强大先验知识,自动生成内在奖励信号,引导智能体进行有效的探索和学习。通过将LLM作为奖励函数的来源,可以克服稀疏奖励问题,并减少对大量人工标注数据的依赖。ONI的关键在于在线学习,即在智能体与环境交互的过程中,动态地生成和更新奖励函数。
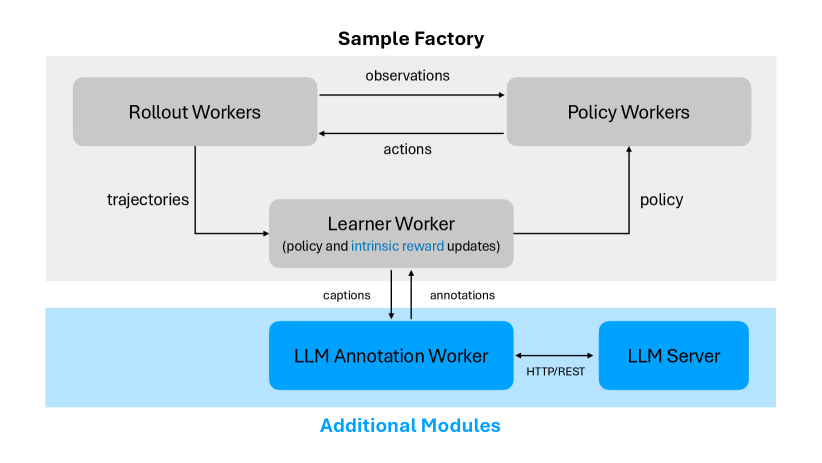
技术框架:ONI采用分布式架构,包含三个主要模块:智能体(Agent)、LLM服务器(LLM Server)和奖励模型(Reward Model)。智能体与环境交互,收集经验数据。LLM服务器异步地接收智能体的经验数据,并根据自然语言描述生成奖励信号。奖励模型则从LLM生成的奖励信号中学习,并将其提炼成一个可高效计算的内在奖励函数。整个过程是循环迭代的,智能体根据内在奖励函数学习策略,策略的改进又会影响智能体的探索行为,从而产生新的经验数据,进一步优化奖励模型。
关键创新:ONI的关键创新在于其在线学习和分布式架构。与以往需要离线数据集或对每个观察进行LLM标注的方法不同,ONI能够在线地从LLM反馈中学习奖励函数,从而实现更高效和可扩展的强化学习。此外,ONI的分布式架构允许异步地进行LLM标注和奖励模型训练,从而提高了整体的学习效率。
关键设计:ONI探索了多种奖励建模方法,包括哈希、分类和排序模型。哈希模型简单高效,但可能无法捕捉复杂的奖励信号。分类模型将奖励信号视为离散类别,可以学习更复杂的奖励函数,但需要更多的计算资源。排序模型则通过比较不同经验的优劣来学习奖励函数,可以更好地处理噪声和不确定性。此外,ONI还采用了异步更新机制,以避免LLM标注的延迟影响智能体的学习。
🖼️ 关键图片

📊 实验亮点
ONI在NetHack学习环境中取得了显著的性能提升,超越了现有的强化学习算法。实验结果表明,ONI能够有效地利用LLM反馈生成内在奖励信号,引导智能体学习复杂的策略。与需要大型离线数据集的方法相比,ONI在性能上取得了显著提升,同时降低了对数据的依赖。
🎯 应用场景
ONI具有广泛的应用前景,可用于解决机器人控制、游戏AI、自动驾驶等领域的稀疏奖励问题。通过利用LLM的知识,ONI可以帮助智能体在复杂环境中进行有效的探索和学习,从而实现更智能、更自主的决策。此外,ONI还可以用于设计分层技能,将复杂的任务分解为多个子任务,并为每个子任务生成相应的奖励函数。
📄 摘要(原文)
Automatically synthesizing dense rewards from natural language descriptions is a promising paradigm in reinforcement learning (RL), with applications to sparse reward problems, open-ended exploration, and hierarchical skill design. Recent works have made promising steps by exploiting the prior knowledge of large language models (LLMs). However, these approaches suffer from important limitations: they are either not scalable to problems requiring billions of environment samples, due to requiring LLM annotations for each observation, or they require a diverse offline dataset, which may not exist or be impossible to collect. In this work, we address these limitations through a combination of algorithmic and systems-level contributions. We propose ONI, a distributed architecture that simultaneously learns an RL policy and an intrinsic reward function using LLM feedback. Our approach annotates the agent's collected experience via an asynchronous LLM server, which is then distilled into an intrinsic reward model. We explore a range of algorithmic choices for reward modeling with varying complexity, including hashing, classification, and ranking models. Our approach achieves state-of-the-art performance across a range of challenging tasks from the NetHack Learning Environment, while removing the need for large offline datasets required by prior work. We make our code available at https://github.com/facebookresearch/oni.