Are Large-Language Models Graph Algorithmic Reasoners?
作者: Alexander K Taylor, Anthony Cuturrufo, Vishal Yathish, Mingyu Derek Ma, Wei Wang
分类: cs.LG, cs.AI
发布日期: 2024-10-29
备注: 9 pages, 13 Figures
💡 一句话要点
MAGMA基准测试揭示LLM在图算法推理上的不足,强调高级提示工程的必要性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 图算法推理 基准测试 算法评估 提示工程
📋 核心要点
- 现有LLM在许多任务中表现出色,但在显式图上的多步推理问题中仍然面临挑战。
- 论文提出MAGMA基准测试,评估LLM在执行经典图算法(如BFS、DFS、Dijkstra等)时的性能。
- 实验结果表明,LLM在图算法推理方面存在不足,需要更高级的提示技术和算法指导。
📝 摘要(中文)
本文旨在解决当前大型语言模型(LLM)面临的核心挑战:在需要多步骤推理的显式图结构上,LLM的推理能力仍然不足。为此,作者提出了一个新颖的基准测试,用于评估LLM在经典图算法推理任务上的性能。该基准测试涵盖了五个基本算法:用于连通性的广度优先搜索(BFS)和深度优先搜索(DFS),用于所有节点最短路径的Dijkstra算法和Floyd-Warshall算法,以及Prim最小生成树(MST-Prim)算法。通过广泛的实验,评估了最先进的LLM逐步执行这些算法的能力,并系统地评估了它们在每个阶段的性能。研究结果突显了LLM在该领域面临的持续挑战,并强调了需要先进的提示技术和算法指令来增强其图推理能力。这项工作提出了MAGMA,这是第一个专注于LLM完成经典图算法的综合基准测试,并为理解和提高其结构化问题解决能力提供了关键一步。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在显式图结构上进行算法推理时遇到的困难。现有方法,即直接应用LLM解决图算法问题,往往由于LLM缺乏对图结构的理解和多步推理能力而表现不佳。痛点在于LLM难以准确、高效地执行经典的图算法,如BFS、DFS、最短路径等。
核心思路:论文的核心思路是通过构建一个专门的基准测试(MAGMA)来系统地评估LLM在图算法推理方面的能力。MAGMA包含了一系列经典的图算法任务,并设计了详细的评估指标,以便深入分析LLM在不同算法步骤中的表现。通过分析LLM的错误模式,可以更好地理解其局限性,并为改进LLM的图推理能力提供指导。
技术框架:MAGMA基准测试主要包含以下几个阶段:1) 图数据生成:生成包含不同规模和结构的图数据。2) 算法任务定义:定义一系列经典的图算法任务,如BFS、DFS、Dijkstra、Floyd-Warshall和Prim算法。3) LLM推理:使用不同的LLM模型,并采用不同的提示策略,让LLM逐步执行算法任务。4) 结果评估:根据预定义的评估指标,评估LLM在每个算法步骤中的准确性和效率。5) 错误分析:分析LLM的错误模式,找出其在图推理方面的局限性。
关键创新:论文最重要的技术创新点在于提出了MAGMA基准测试,这是第一个专门用于评估LLM在经典图算法推理方面能力的综合性基准。与现有方法相比,MAGMA更加系统化和全面,可以更深入地了解LLM在图推理方面的优势和不足。此外,MAGMA还提供了一系列详细的评估指标和错误分析工具,方便研究人员进行深入分析。
关键设计:MAGMA的关键设计包括:1) 图数据的多样性:生成包含不同规模、密度和结构的图数据,以评估LLM在不同图结构上的泛化能力。2) 算法任务的代表性:选择了一系列经典的图算法,涵盖了连通性、最短路径和最小生成树等基本问题。3) 评估指标的细粒度:设计了细粒度的评估指标,可以评估LLM在每个算法步骤中的准确性和效率。4) 提示策略的灵活性:允许研究人员采用不同的提示策略,以探索如何提高LLM的图推理能力。
🖼️ 关键图片
📊 实验亮点
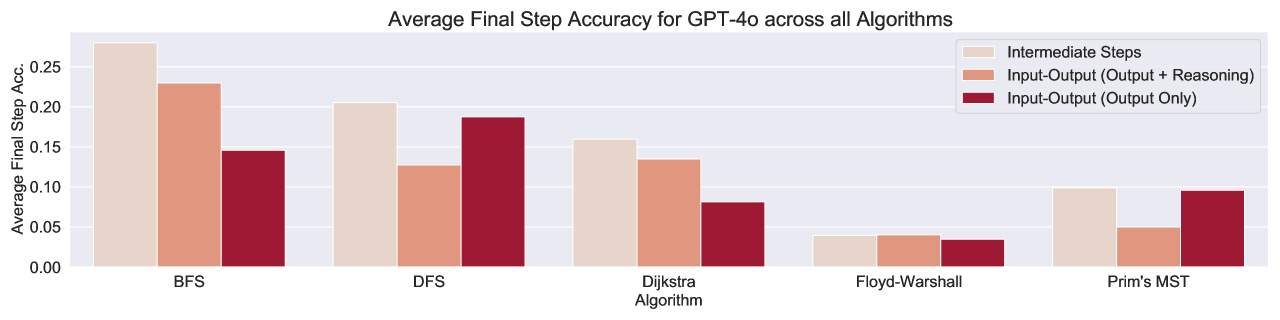
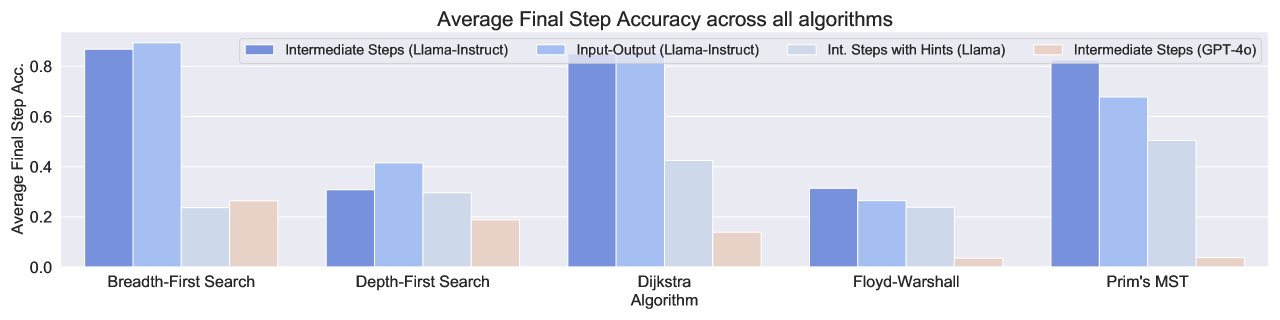
实验结果表明,即使是最先进的LLM在MAGMA基准测试上也表现出显著的局限性。例如,LLM在执行Dijkstra算法和Prim算法等复杂算法时,准确率远低于人类水平。通过对比不同提示策略,发现精心设计的提示可以显著提高LLM的性能,但仍然无法完全克服其在图推理方面的不足。这些结果强调了需要进一步研究和改进LLM的图推理能力。
🎯 应用场景
该研究成果可应用于提升LLM在知识图谱推理、推荐系统、路径规划、网络安全分析等领域的性能。通过MAGMA基准测试,可以系统性地评估和改进LLM的图推理能力,从而推动LLM在更广泛的实际应用中发挥作用。未来的研究可以探索更有效的提示工程方法,以及如何将图神经网络等技术与LLM相结合,以进一步提升其图推理能力。
📄 摘要(原文)
We seek to address a core challenge facing current Large Language Models (LLMs). LLMs have demonstrated superior performance in many tasks, yet continue to struggle with reasoning problems on explicit graphs that require multiple steps. To address this gap, we introduce a novel benchmark designed to evaluate LLM performance on classical algorithmic reasoning tasks on explicit graphs. Our benchmark encompasses five fundamental algorithms: Breadth-First Search (BFS) and Depth-First Search (DFS) for connectivity, Dijkstra's algorithm and Floyd-Warshall algorithm for all nodes shortest path, and Prim's Minimum Spanning Tree (MST-Prim's) algorithm. Through extensive experimentation, we assess the capabilities of state-of-the-art LLMs in executing these algorithms step-by-step and systematically evaluate their performance at each stage. Our findings highlight the persistent challenges LLMs face in this domain and underscore the necessity for advanced prompting techniques and algorithmic instruction to enhance their graph reasoning abilities. This work presents MAGMA, the first comprehensive benchmark focused on LLMs completing classical graph algorithms, and provides a critical step toward understanding and improving their structured problem-solving skills.