BenchAgents: Multi-Agent Systems for Structured Benchmark Creation
作者: Natasha Butt, Varun Chandrasekaran, Neel Joshi, Besmira Nushi, Vidhisha Balachandran
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-10-29 (更新: 2025-10-07)
💡 一句话要点
BenchAgents:利用多智能体系统自动创建结构化评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 基准测试 大型语言模型 自动化评估 生成模型
📋 核心要点
- 现有基准测试集构建缓慢且成本高昂,难以跟上快速发展的模型能力,限制了对模型性能的全面评估。
- BenchAgents 提出一种多智能体框架,利用大型语言模型自动生成高质量的评测基准,并确保数据和评估指标的质量。
- BenchAgents 被用于创建评估规划、约束满足和因果推理能力的基准,并用于分析现有模型的不足之处。
📝 摘要(中文)
评估洞察力受限于高质量基准的可用性。随着模型的发展,需要创建能够衡量新的和复杂的生成能力进展的基准。然而,手动创建新的基准既缓慢又昂贵,限制了对任何能力的全面评估。我们介绍了BenchAgents,一个多智能体框架,它有条不紊地利用大型语言模型(LLM)来自动化评估基准的创建,同时固有地确保数据和(评估)指标的质量。BenchAgents将基准创建过程分解为规划、生成、验证和评估,每个过程都通过LLM智能体进行协调。这些智能体相互交互,并利用来自基准开发人员的反馈来改进和灵活地控制数据的多样性和质量。我们使用BenchAgents创建基准来评估与规划、约束满足和因果推理相关的能力,涵盖语言和视觉模态。然后,我们使用这些基准来研究最先进的模型,并提取关于常见失败模式和模型差异的新见解。
🔬 方法详解
问题定义:现有评估基准的创建过程耗时且成本高昂,无法快速适应新型生成模型能力的评估需求。手动创建基准难以保证数据多样性和质量,限制了对模型性能的全面理解。现有方法缺乏自动化和可扩展性,难以满足日益增长的评估需求。
核心思路:BenchAgents 的核心思路是将基准创建过程分解为多个阶段,并为每个阶段设计专门的 LLM 智能体。这些智能体相互协作,利用反馈机制不断改进基准的质量和多样性。通过自动化基准创建过程,可以显著降低成本和时间,并提高基准的质量和覆盖范围。
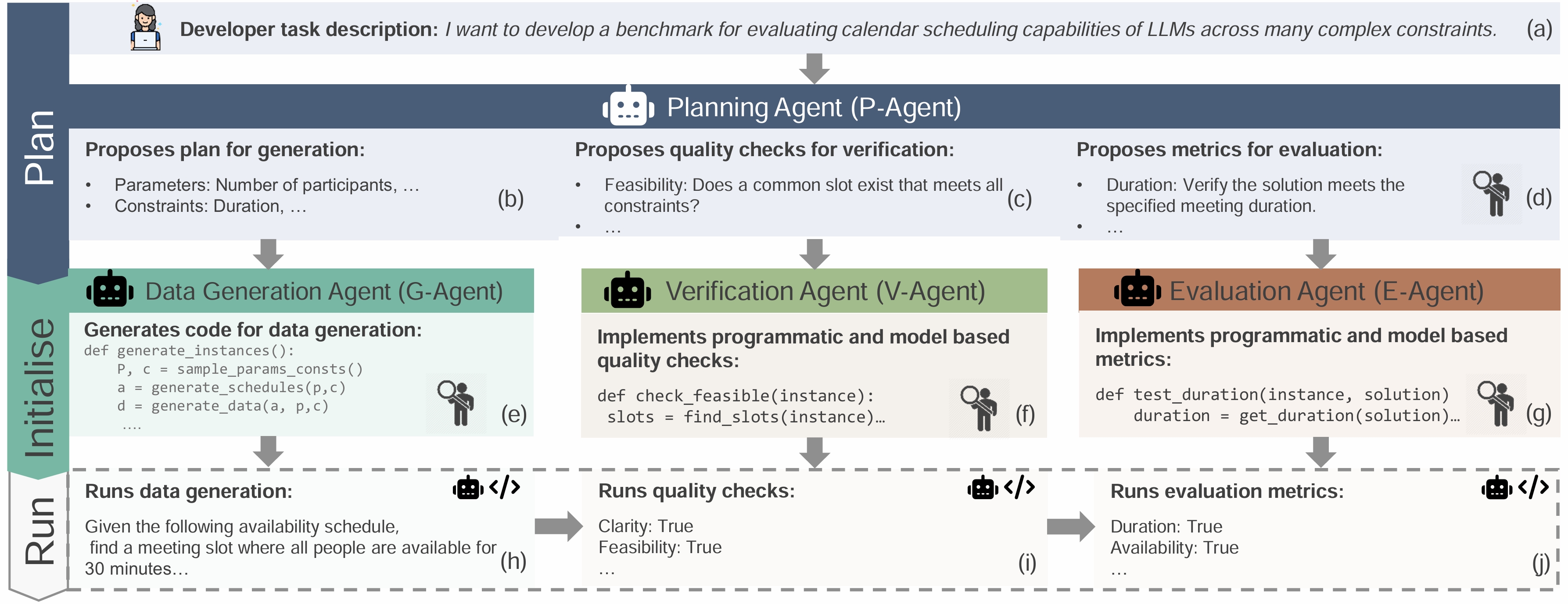
技术框架:BenchAgents 框架包含四个主要阶段:规划(Planning)、生成(Generation)、验证(Verification)和评估(Evaluation)。每个阶段都由一个或多个 LLM 智能体负责。规划阶段确定基准的目标和范围;生成阶段生成数据样本;验证阶段检查数据质量和一致性;评估阶段使用生成的基准评估模型性能。智能体之间通过消息传递进行通信和协作,并利用来自基准开发人员的反馈进行改进。
关键创新:BenchAgents 的关键创新在于将多智能体系统应用于基准创建过程,实现了基准创建的自动化和可扩展性。通过分解任务和利用 LLM 的生成和推理能力,可以高效地创建高质量的基准。此外,BenchAgents 框架具有灵活性,可以根据不同的评估需求进行定制和扩展。
关键设计:BenchAgents 的关键设计包括智能体的角色分配、消息传递机制、反馈机制和数据验证策略。智能体的角色分配需要根据任务的特点进行优化,以实现最佳的协作效果。消息传递机制需要保证信息的准确性和及时性。反馈机制需要有效地收集和利用来自基准开发人员的反馈。数据验证策略需要确保数据的质量和一致性。
🖼️ 关键图片


📊 实验亮点
BenchAgents 被用于创建评估规划、约束满足和因果推理能力的基准,涵盖语言和视觉模态。实验结果表明,使用 BenchAgents 创建的基准能够有效地揭示现有模型的不足之处,并区分不同模型之间的性能差异。具体性能数据和提升幅度在论文中进行了详细描述(未知)。
🎯 应用场景
BenchAgents 可应用于各种需要评估生成模型能力的领域,例如自然语言处理、计算机视觉和机器人技术。它可以用于创建评估模型在规划、推理、约束满足等方面能力的基准。该研究的实际价值在于降低了基准创建的成本和时间,提高了基准的质量和覆盖范围,从而促进了模型评估和改进。未来,BenchAgents 可以扩展到支持更复杂的评估场景和更广泛的模型类型。
📄 摘要(原文)
Evaluation insights are limited by the availability of high-quality benchmarks. As models evolve, there is a need to create benchmarks that can measure progress on new and complex generative capabilities. However, manually creating new benchmarks is slow and expensive, restricting comprehensive evaluations for any capability. We introduce BenchAgents, a multi-agent framework that methodically leverages large language models (LLMs) to automate evaluation benchmark creation while inherently ensuring data and (evaluation) metric quality. BenchAgents decomposes the benchmark creation process into planning, generation, verification, and evaluation, each of which is ] orchestrated via LLM agents. These agents interact with each other and utilize feedback from benchmark developers to improve and flexibly control data diversity and quality. We use BenchAgents to create benchmarks to evaluate capabilities related to planning, constraint satisfaction, and causal reasoning spanning both language and vision modalities. We then use these benchmarks to study state-of-the-art models and extract new insights into common failure modes and model differences.