Not All LLM-Generated Data Are Equal: Rethinking Data Weighting in Text Classification
作者: Hsun-Yu Kuo, Yin-Hsiang Liao, Yu-Chieh Chao, Wei-Yun Ma, Pu-Jen Cheng
分类: cs.LG, cs.CL
发布日期: 2024-10-28 (更新: 2025-03-22)
备注: ICLR 2025 camera ready
💡 一句话要点
提出加权损失方法,提升LLM生成数据在文本分类中的利用率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本分类 数据增强 大型语言模型 加权损失 合成数据 BERT 数据偏差 模型训练
📋 核心要点
- 现有方法在利用LLM生成的合成数据进行文本分类时,由于数据偏差导致模型性能下降。
- 论文提出一种加权损失方法,通过赋予高质量和多样化的合成数据更高的权重,来对齐合成数据与真实数据分布。
- 实验结果表明,该方法在多个文本分类任务中,显著优于标准交叉熵和其他数据加权方法。
📝 摘要(中文)
本文提出了一种有效的加权损失方法,旨在通过强调由大型语言模型(LLMs)生成的高质量和多样化数据,来使合成数据与真实世界的数据分布对齐,从而解决合成数据与真实数据偏差的问题。该方法仅需少量真实数据,即可提升下游任务的性能,尤其是在真实数据稀缺的情况下。我们在多个文本分类任务上进行了实验评估,结果表明,在BERT模型上应用我们的方法,能够稳健地优于标准交叉熵和其他数据加权方法。这为有效利用来自任何合适数据生成器的合成数据进行模型训练提供了潜在的解决方案。
🔬 方法详解
问题定义:论文旨在解决利用大型语言模型(LLMs)生成的合成数据增强文本分类任务时,由于合成数据与真实数据分布存在偏差,导致模型性能下降的问题。现有方法通常直接使用合成数据进行训练,或者采用简单的数据加权策略,无法有效解决数据偏差带来的负面影响。
核心思路:论文的核心思路是通过加权损失函数,对LLM生成的合成数据进行差异化处理。高质量和多样化的合成数据被赋予更高的权重,从而在训练过程中更加重视这些数据,使模型更好地学习真实数据分布。这种方法旨在缓解合成数据与真实数据之间的偏差,提升模型泛化能力。
技术框架:整体框架包括三个主要步骤:1)使用LLM生成合成数据;2)利用少量真实数据,评估合成数据的质量和多样性;3)使用加权损失函数,结合真实数据和加权后的合成数据进行模型训练。加权损失函数的设计是关键,它根据合成数据的质量和多样性,动态调整其在损失函数中的权重。
关键创新:论文的关键创新在于提出了一种高效的加权损失方法,该方法能够根据合成数据的质量和多样性,自适应地调整其权重。与现有方法相比,该方法能够更有效地利用LLM生成的合成数据,提升模型在真实数据上的性能。
关键设计:论文提出了具体的加权损失函数形式,例如,可以基于合成数据的置信度或与真实数据的相似度来确定权重。此外,论文还可能探索了不同的损失函数组合方式,以及针对特定文本分类任务的参数调整策略。具体的网络结构采用BERT模型,并在其基础上进行微调。
🖼️ 关键图片
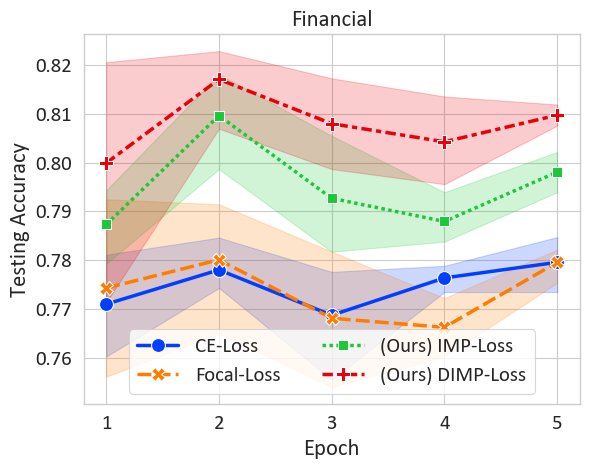
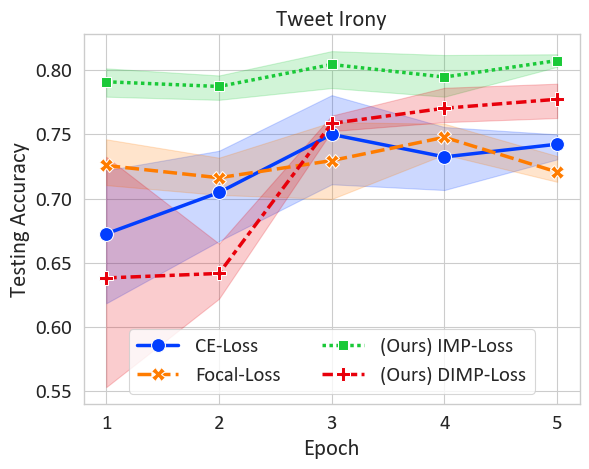
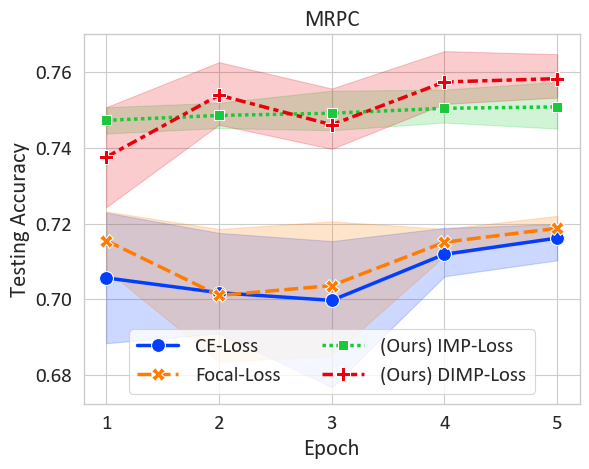
📊 实验亮点
实验结果表明,在多个文本分类任务中,使用该方法训练的BERT模型显著优于标准交叉熵和其他数据加权方法。具体的性能提升幅度取决于数据集和任务,但总体趋势是该方法能够稳定地提升模型性能,尤其是在真实数据较少的情况下,提升效果更为明显。
🎯 应用场景
该研究成果可广泛应用于各种文本分类任务,尤其是在数据稀缺的场景下,例如情感分析、主题分类、垃圾邮件检测等。通过利用LLM生成高质量的合成数据,并结合本文提出的加权损失方法,可以有效提升模型的性能和泛化能力,降低对大规模标注数据的依赖,具有重要的实际应用价值。
📄 摘要(原文)
Synthetic data augmentation via large language models (LLMs) allows researchers to leverage additional training data, thus enhancing the performance of downstream tasks, especially when real-world data is scarce. However, the generated data can deviate from the real-world data, and this misalignment can bring deficient outcomes while applying the trained model to applications. Therefore, we proposed efficient weighted-loss approaches to align synthetic data with real-world distribution by emphasizing high-quality and diversified data generated by LLMs with using merely a little real-world data. We empirically assessed the effectiveness of our method on multiple text classification tasks, and the results showed leveraging our approaches on a BERT-level model robustly outperformed standard cross-entropy and other data weighting approaches, providing potential solutions to effectively leveraging synthetic data from any suitable data generator for model training.