A Multi-Agent Reinforcement Learning Testbed for Cognitive Radio Applications
作者: Sriniketh Vangaru, Daniel Rosen, Dylan Green, Raphael Rodriguez, Maxwell Wiecek, Amos Johnson, Alyse M. Jones, William C. Headley
分类: cs.LG, cs.AI, cs.MA, cs.NI
发布日期: 2024-10-28 (更新: 2024-12-02)
备注: Accepted to IEEE CCNC 2025. Added revisions from paper reviews
💡 一句话要点
扩展RFRL Gym,实现多智能体强化学习在认知无线电应用中的测试与评估。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 认知无线电 无线通信 射频频谱 仿真环境
📋 核心要点
- 现有RFRL Gym仅支持单智能体训练,无法模拟实际频谱拥塞场景下多智能体的交互。
- 通过集成Ray RLlib,RFRL Gym扩展了多智能体强化学习功能,支持合作、竞争和混合环境的训练与评估。
- 更新后的RFRL Gym在射频频谱仿真方面更加强大,为无线通信领域的算法开发和测试提供了更完善的工具。
📝 摘要(中文)
本文介绍了一种针对认知无线电应用的多智能体强化学习(MARL)测试平台,即RFRL Gym的升级版本。无线电频率强化学习(RFRL)在未来的无线通信系统中将扮演重要角色,其应用范围广泛,从军事通信干扰到增强WiFi网络。为了确保算法性能,必须在部署前进行仿真训练。RFRL Gym最初是一个用于开发和测试无线通信领域强化学习算法的标准化工具,但仅限于训练单个智能体。为了解决实际场景中多智能体共存的问题,本文通过集成Ray RLlib,为RFRL Gym添加了MARL功能,使其成为更强大的射频频谱仿真工具。本文概述了更新后的RFRL Gym环境,描述了该工具的总体框架,并与现有资源进行了比较,重点介绍了所做的重大改进和重构。最后,讨论了在MARL环境中测试各种射频场景的结果以及未来的改进方向。
🔬 方法详解
问题定义:论文旨在解决现有RFRL Gym只能进行单智能体强化学习训练的问题。在实际的无线通信环境中,通常存在多个智能体,它们之间可能存在合作、竞争或混合的关系。因此,需要一个能够支持多智能体强化学习的仿真环境,以便更好地评估和训练算法。现有方法的痛点在于无法模拟真实场景中多智能体的交互,限制了算法的泛化能力和实际应用效果。
核心思路:论文的核心思路是将Ray RLlib集成到现有的RFRL Gym中,从而扩展其多智能体强化学习功能。Ray RLlib是一个流行的强化学习库,提供了丰富的多智能体算法和工具。通过集成Ray RLlib,RFRL Gym可以支持各种多智能体场景的仿真和训练,从而更好地满足实际应用的需求。
技术框架:更新后的RFRL Gym的整体架构包括以下几个主要模块:1) 环境建模:定义无线通信环境,包括信道模型、干扰模型、以及智能体的行为模型。2) 智能体建模:定义智能体的行为策略,包括强化学习算法的选择、奖励函数的设计等。3) Ray RLlib集成:利用Ray RLlib提供的多智能体算法和工具,进行智能体的训练和评估。4) 结果分析:对训练结果进行分析,评估算法的性能和效果。
关键创新:论文的最重要的技术创新点在于将Ray RLlib集成到现有的RFRL Gym中,从而扩展了其多智能体强化学习功能。与现有方法相比,该方法能够更好地模拟真实场景中多智能体的交互,从而提高算法的泛化能力和实际应用效果。此外,该方法还提供了一个标准化的测试平台,方便研究人员进行算法的开发和评估。
关键设计:论文中没有详细描述关键的参数设置、损失函数、网络结构等技术细节。这些细节取决于具体的强化学习算法和应用场景。然而,论文强调了Ray RLlib的灵活性和可扩展性,允许用户根据自己的需求进行定制和修改。
🖼️ 关键图片
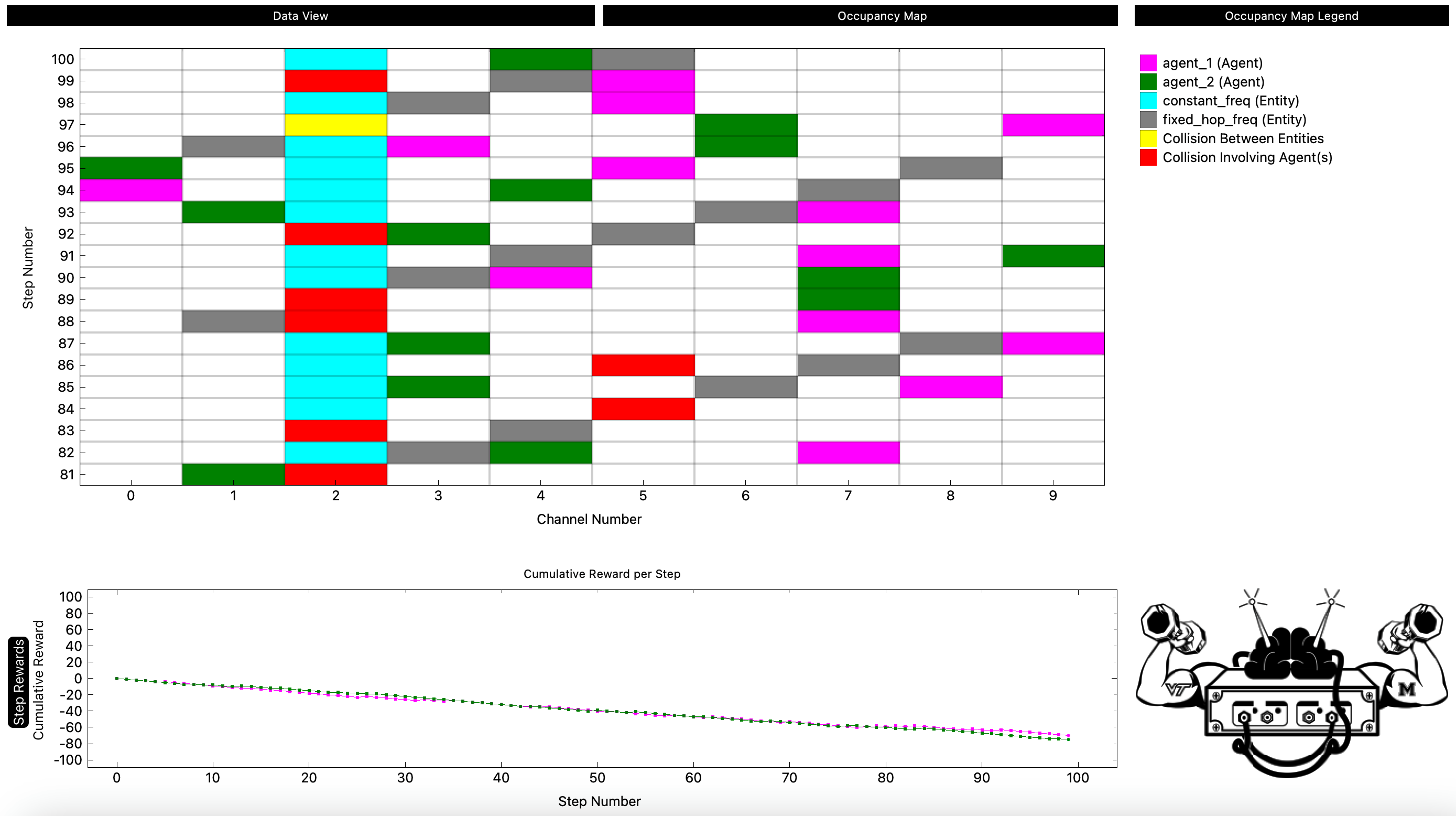
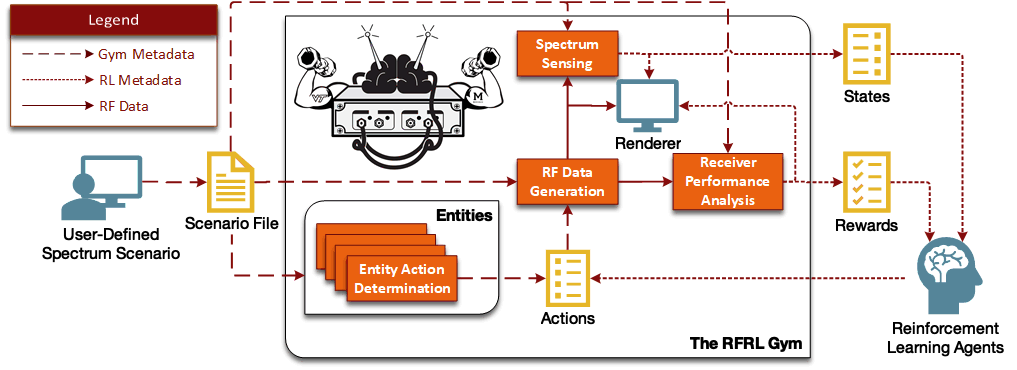
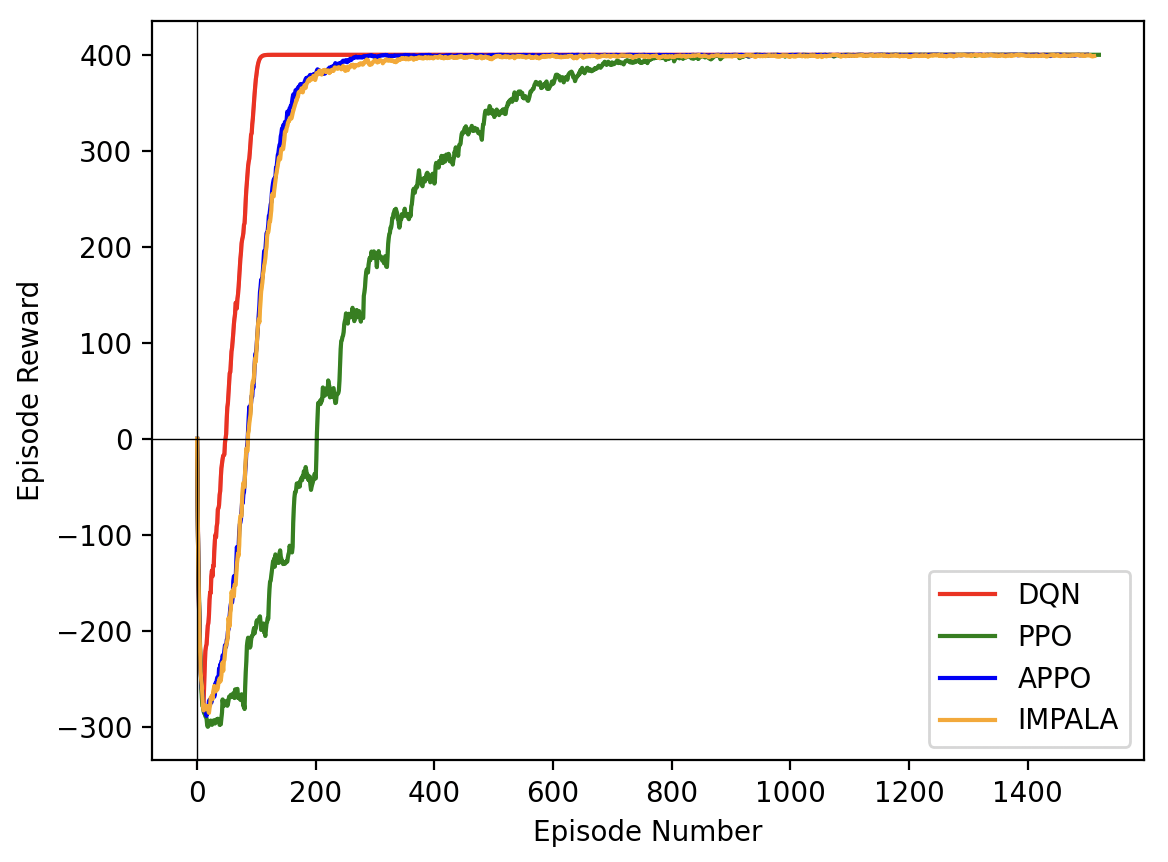
📊 实验亮点
论文主要介绍了RFRL Gym的更新和扩展,侧重于环境的搭建和功能的集成,并没有提供具体的实验结果和性能数据。文中提到在MARL环境中测试了各种射频场景,但没有给出详细的对比基线和提升幅度。未来的工作将包括对各种多智能体算法进行评估和比较,并提供更详细的实验结果。
🎯 应用场景
该研究成果可应用于各种无线通信场景,例如:认知无线电网络、无线电资源管理、频谱共享、军事通信干扰等。通过在RFRL Gym中进行仿真训练,可以有效地评估和优化多智能体强化学习算法,从而提高无线通信系统的性能和效率,并为未来的无线通信技术发展提供支持。
📄 摘要(原文)
Technological trends show that Radio Frequency Reinforcement Learning (RFRL) will play a prominent role in the wireless communication systems of the future. Applications of RFRL range from military communications jamming to enhancing WiFi networks. Before deploying algorithms for these purposes, they must be trained in a simulation environment to ensure adequate performance. For this reason, we previously created the RFRL Gym: a standardized, accessible tool for the development and testing of reinforcement learning (RL) algorithms in the wireless communications space. This environment leveraged the OpenAI Gym framework and featured customizable simulation scenarios within the RF spectrum. However, the RFRL Gym was limited to training a single RL agent per simulation; this is not ideal, as most real-world RF scenarios will contain multiple intelligent agents in cooperative, competitive, or mixed settings, which is a natural consequence of spectrum congestion. Therefore, through integration with Ray RLlib, multi-agent reinforcement learning (MARL) functionality for training and assessment has been added to the RFRL Gym, making it even more of a robust tool for RF spectrum simulation. This paper provides an overview of the updated RFRL Gym environment. In this work, the general framework of the tool is described relative to comparable existing resources, highlighting the significant additions and refactoring we have applied to the Gym. Afterward, results from testing various RF scenarios in the MARL environment and future additions are discussed.