BLAST: Block-Level Adaptive Structured Matrices for Efficient Deep Neural Network Inference
作者: Changwoo Lee, Soo Min Kwon, Qing Qu, Hun-Seok Kim
分类: cs.LG, cs.AI, stat.ML
发布日期: 2024-10-28 (更新: 2024-10-30)
🔗 代码/项目: GITHUB
💡 一句话要点
BLAST:用于高效深度神经网络推理的块级自适应结构化矩阵
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型压缩 结构化矩阵 深度学习 高效推理 自适应学习
📋 核心要点
- 大型深度学习模型推理计算量巨大,现有方法难以兼顾效率与性能。
- 提出BLAST矩阵,自适应学习权重矩阵中的结构,实现高效压缩。
- 实验表明,BLAST在多种模型上实现了显著的压缩率,同时保持了良好的性能。
📝 摘要(中文)
大规模基础模型在语言和视觉任务中表现出卓越的性能。然而,这些大型网络中涉及的大量密集矩阵-向量运算在推理过程中带来了巨大的计算挑战。为了应对这些挑战,我们引入了块级自适应结构化(BLAST)矩阵,旨在学习和利用深度学习模型中线性层权重矩阵中普遍存在的有效结构。与现有的结构化矩阵相比,BLAST矩阵提供了极大的灵活性,因为它可以表示从数据中学习或从预先存在的权重矩阵计算的各种类型的结构。我们证明了使用BLAST矩阵压缩语言和视觉任务的效率,表明:(i)对于ViT和GPT-2等中型模型,使用BLAST权重进行训练可提高性能,同时分别降低70%和40%的复杂度;(ii)对于Llama-7B和DiT-XL等大型基础模型,BLAST矩阵实现了2倍的压缩,同时在所有测试的结构化矩阵中表现出最低的性能下降。
🔬 方法详解
问题定义:论文旨在解决大型深度神经网络在推理过程中计算量过大的问题。现有方法,如传统的矩阵分解或稀疏化方法,可能无法充分利用权重矩阵中存在的结构信息,导致压缩率不高或性能下降。此外,不同的模型和任务可能具有不同的权重结构,现有方法缺乏足够的灵活性来适应这些差异。
核心思路:论文的核心思路是设计一种块级自适应的结构化矩阵(BLAST),使其能够学习并利用权重矩阵中存在的各种结构。通过将权重矩阵划分为块,并为每个块自适应地选择合适的结构,BLAST矩阵可以在压缩模型的同时,尽可能地保留原始模型的性能。这种自适应性使得BLAST矩阵能够更好地适应不同模型和任务的需求。
技术框架:BLAST矩阵的整体框架包括以下几个主要步骤:1. 将权重矩阵划分为多个块;2. 对于每个块,学习或计算其结构;3. 使用学习到的结构来压缩权重矩阵;4. 在推理过程中,利用压缩后的权重矩阵进行计算。具体的结构学习方法可以根据不同的任务和模型进行选择,例如,可以使用低秩分解、Toeplitz结构或循环结构等。
关键创新:BLAST矩阵的关键创新在于其块级自适应性。与传统的结构化矩阵方法相比,BLAST矩阵可以为不同的块选择不同的结构,从而更好地适应权重矩阵中存在的复杂结构。此外,BLAST矩阵还可以学习权重矩阵的结构,而不需要手动指定,从而提高了其灵活性和易用性。
关键设计:BLAST矩阵的关键设计包括:1. 块大小的选择:块大小的选择会影响压缩率和性能。较小的块大小可以更好地适应权重矩阵中的局部结构,但会增加计算复杂度。较大的块大小可以降低计算复杂度,但可能会损失一些局部结构信息。2. 结构学习方法:可以使用不同的结构学习方法,例如,可以使用低秩分解、Toeplitz结构或循环结构等。3. 损失函数:可以使用不同的损失函数来训练BLAST矩阵,例如,可以使用重构误差或分类误差等。
🖼️ 关键图片


📊 实验亮点
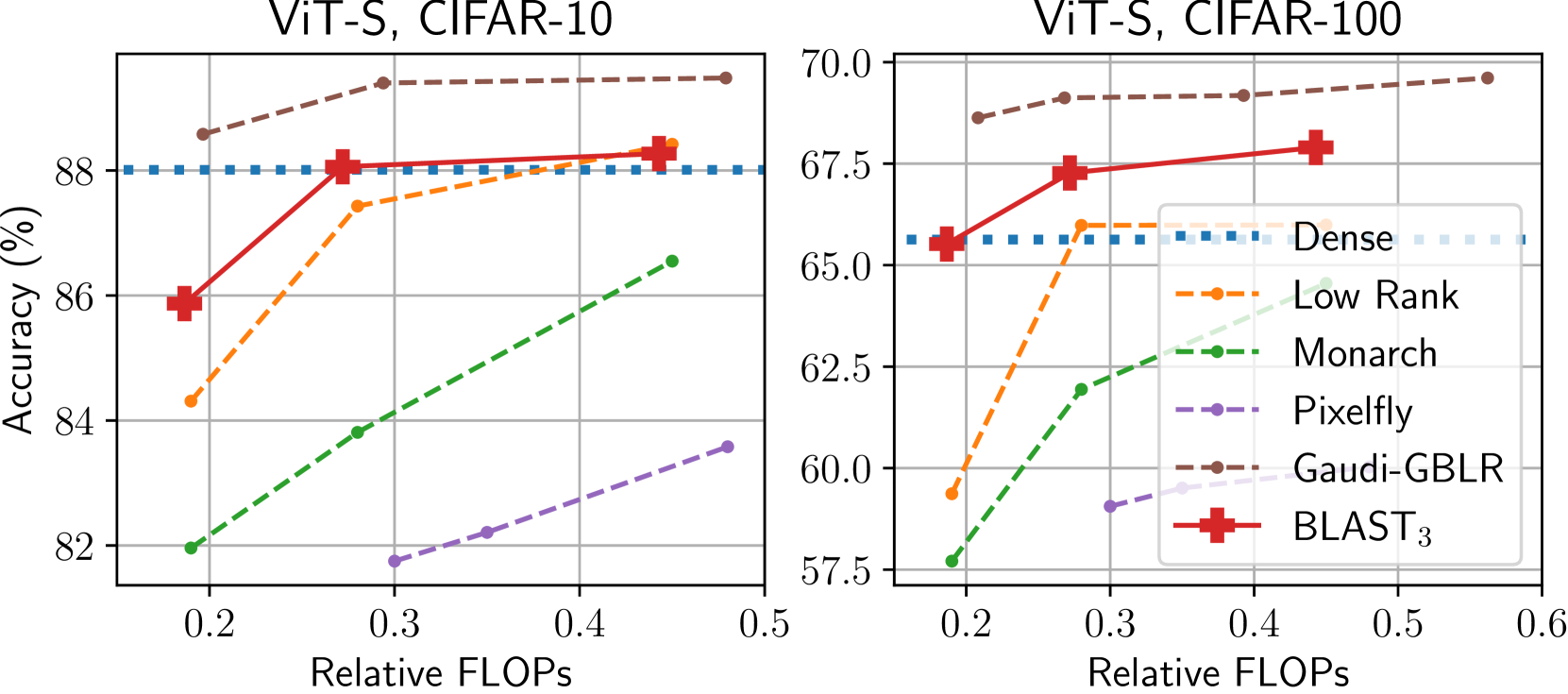
BLAST矩阵在ViT和GPT-2等中型模型上,训练时在降低70%和40%的复杂度的同时,提升了模型性能。在Llama-7B和DiT-XL等大型基础模型上,BLAST矩阵实现了2倍的压缩,并且在所有测试的结构化矩阵中,性能下降最小。这些结果表明,BLAST矩阵是一种高效且有效的模型压缩方法。
🎯 应用场景
BLAST矩阵可广泛应用于各种需要高效深度学习模型推理的场景,如移动设备、边缘计算设备和资源受限的环境。通过降低模型大小和计算复杂度,BLAST矩阵可以提高推理速度,降低功耗,并使得大型深度学习模型能够在这些设备上部署。此外,BLAST矩阵还可以用于模型压缩和知识蒸馏等任务。
📄 摘要(原文)
Large-scale foundation models have demonstrated exceptional performance in language and vision tasks. However, the numerous dense matrix-vector operations involved in these large networks pose significant computational challenges during inference. To address these challenges, we introduce the Block-Level Adaptive STructured (BLAST) matrix, designed to learn and leverage efficient structures prevalent in the weight matrices of linear layers within deep learning models. Compared to existing structured matrices, the BLAST matrix offers substantial flexibility, as it can represent various types of structures that are either learned from data or computed from pre-existing weight matrices. We demonstrate the efficiency of using the BLAST matrix for compressing both language and vision tasks, showing that (i) for medium-sized models such as ViT and GPT-2, training with BLAST weights boosts performance while reducing complexity by 70% and 40%, respectively; and (ii) for large foundation models such as Llama-7B and DiT-XL, the BLAST matrix achieves a 2x compression while exhibiting the lowest performance degradation among all tested structured matrices. Our code is available at https://github.com/changwoolee/BLAST.