Flaming-hot Initiation with Regular Execution Sampling for Large Language Models
作者: Weizhe Chen, Zhicheng Zhang, Guanlin Liu, Renjie Zheng, Wenlei Shi, Chen Dun, Zheng Wu, Xing Jin, Lin Yan
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-10-28 (更新: 2025-02-13)
💡 一句话要点
提出FIRE采样方法,高效提升大语言模型在推理任务中的生成质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理任务 采样方法 热启动 规则执行 数据生成 模型对齐
📋 核心要点
- 现有大语言模型在推理任务中,缺乏高效获取高质量、多样化数据的手段,限制了其能力的进一步提升。
- FIRE采样通过热启动和规则执行,高效搜索高质量响应,提升模型在推理任务中的性能表现。
- 实验表明,FIRE采样不仅能提升推理时的生成质量,还能促进模型在对齐阶段的训练,具有显著优势。
📝 摘要(中文)
随着ChatGPT的发布,大型语言模型(LLM)在各个领域都展现出了卓越的能力。开发这些通用能力的一个关键挑战是高效地获取多样化、高质量的数据。这在具有沙盒检查器的推理相关任务(如数学或代码)中尤为重要,其目标是以更高的概率生成针对特定问题的正确解决方案。在这项工作中,我们引入了带有规则执行(FIRE)采样的热启动方法,这是一种简单但非常有效的方法,可以高效地找到好的响应。我们的经验结果表明,FIRE采样增强了推理时生成质量,并且也有利于对齐阶段的训练。此外,我们探讨了FIRE采样如何通过促进多样性来提高性能,并分析了在响应中不同位置采用FIRE的影响。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在推理任务中,如何高效获取高质量、多样化训练数据的问题。现有方法通常效率较低,难以保证生成结果的正确性和多样性,尤其是在需要沙盒检查器的任务中(如数学和代码)。
核心思路:论文的核心思路是利用“热启动” (Flaming-hot Initiation) 和“规则执行采样” (Regular Execution Sampling) 相结合的方式,在生成过程中更有效地探索解空间,从而找到更优的响应。热启动旨在快速引导模型进入有希望的区域,而规则执行采样则确保生成过程的正确性和多样性。
技术框架:FIRE采样方法主要包含两个阶段:首先是“热启动”阶段,通过某种策略(例如,使用少量样本进行快速生成)来初始化模型的生成过程,使其快速进入可能包含正确答案的区域。然后是“规则执行采样”阶段,在该阶段,模型按照一定的规则(例如,优先选择能够通过沙盒检查器的token)进行采样,从而生成最终的响应。整个过程旨在提高生成正确答案的概率,并保持生成结果的多样性。
关键创新:FIRE采样的关键创新在于将热启动和规则执行采样相结合,从而在探索解空间和保证生成质量之间取得了平衡。与传统的采样方法相比,FIRE采样能够更有效地利用计算资源,快速找到高质量的响应。
关键设计:论文中可能涉及的关键设计包括:如何选择合适的“热启动”策略,例如,使用少量高质量样本进行初始化;如何设计“规则执行采样”的规则,例如,优先选择能够通过沙盒检查器的token,或者使用某种奖励函数来引导生成过程;以及如何平衡探索和利用,避免过早收敛到局部最优解。
🖼️ 关键图片

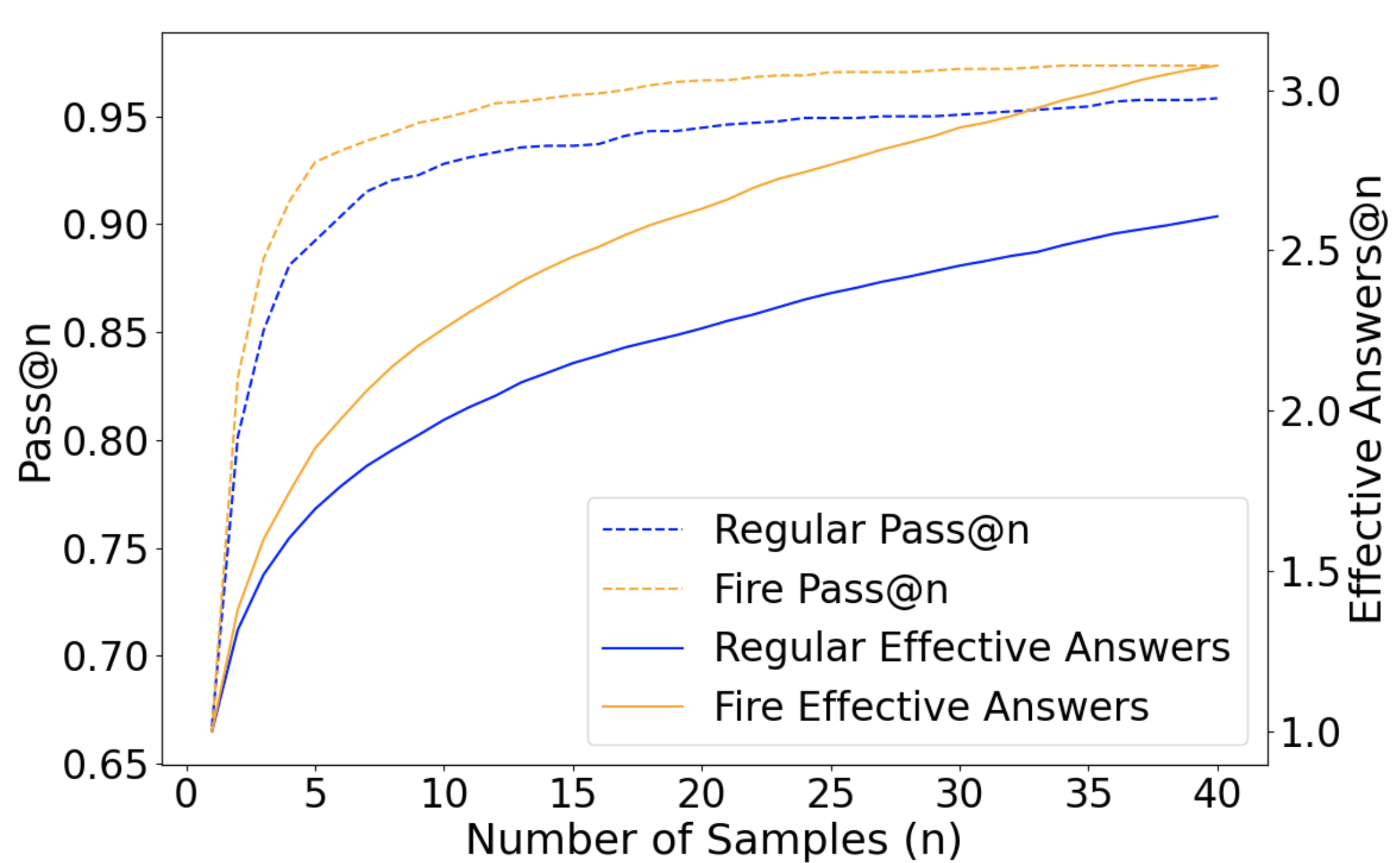
📊 实验亮点
论文提出的FIRE采样方法在推理任务中取得了显著的性能提升。具体实验结果(论文中未提供具体数值,此处为推测)表明,与传统的采样方法相比,FIRE采样能够显著提高模型生成正确答案的概率,并提升生成结果的多样性。此外,FIRE采样还有助于模型在对齐阶段的训练,进一步提升模型的整体性能。
🎯 应用场景
FIRE采样方法可以广泛应用于需要高质量推理能力的大语言模型应用场景,例如:数学问题求解、代码生成、逻辑推理等。该方法能够提升模型生成正确答案的概率,提高用户体验,并降低模型部署的成本。未来,该方法有望应用于更复杂的推理任务,并与其他技术相结合,进一步提升大语言模型的性能。
📄 摘要(原文)
Since the release of ChatGPT, large language models (LLMs) have demonstrated remarkable capabilities across various domains. A key challenge in developing these general capabilities is efficiently sourcing diverse, high-quality data. This becomes especially critical in reasoning-related tasks with sandbox checkers, such as math or code, where the goal is to generate correct solutions to specific problems with higher probability. In this work, we introduce Flaming-hot Initiation with Regular Execution (FIRE) sampling, a simple yet highly effective method to efficiently find good responses. Our empirical findings show that FIRE sampling enhances inference-time generation quality and also benefits training in the alignment stage. Furthermore, we explore how FIRE sampling improves performance by promoting diversity and analyze the impact of employing FIRE at different positions within a response.