LoRA vs Full Fine-tuning: An Illusion of Equivalence
作者: Reece Shuttleworth, Jacob Andreas, Antonio Torralba, Pratyusha Sharma
分类: cs.LG, cs.CL
发布日期: 2024-10-28 (更新: 2025-10-22)
💡 一句话要点
揭示LoRA与全参数微调的差异:通过奇异值分解发现“入侵维度”
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LoRA 参数高效微调 奇异值分解 入侵维度 持续学习 大型语言模型 模型遗忘
📋 核心要点
- 现有方法如LoRA虽然能高效微调LLM,但其与全参数微调的等价性尚不明确,需要深入研究。
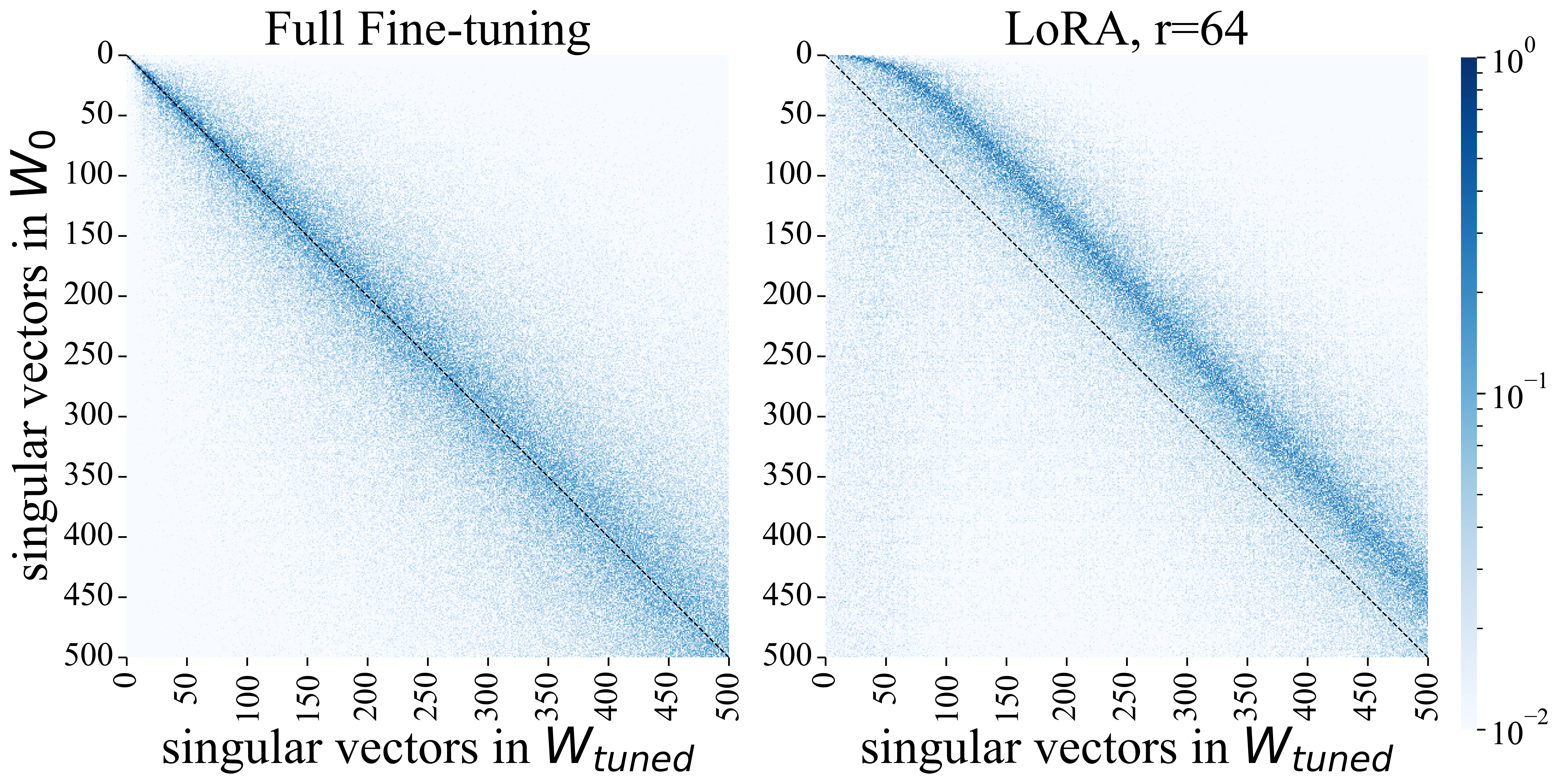
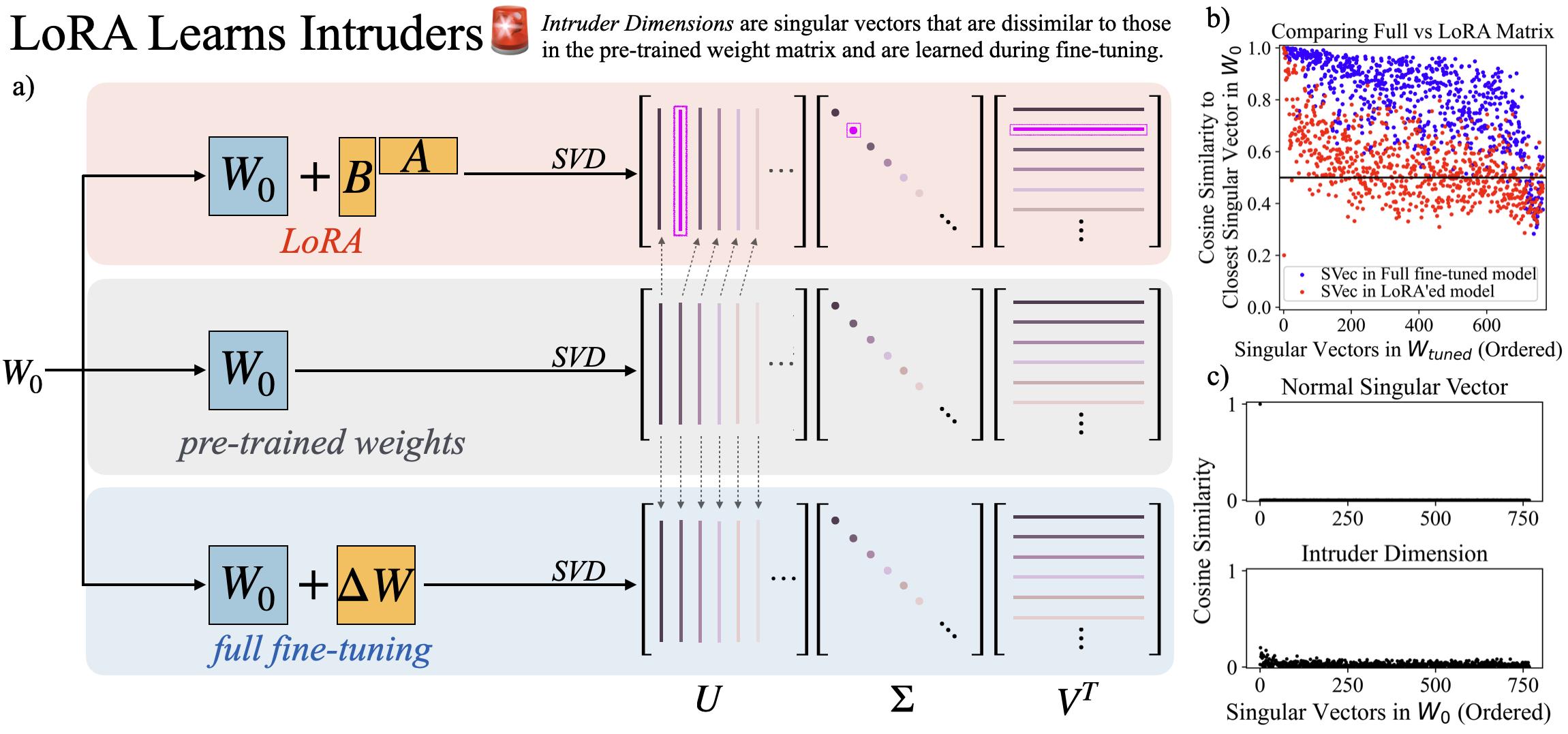
- 论文通过分析权重矩阵的奇异值分解,揭示LoRA引入了“入侵维度”,这是与全参数微调的关键差异。
- 实验表明,干预“入侵维度”会影响模型遗忘,且LoRA在持续学习中易累积“入侵维度”导致性能下降。
📝 摘要(中文)
微调是将预训练大型语言模型适配到下游任务的关键范式。最近,像LoRA这样的方法通过极大地减少可训练参数,有效地微调LLM。但是,它们学习到的解决方案真的等价吗?我们通过分析模型的权重矩阵的谱特性,研究LoRA和全参数微调如何改变预训练模型。我们发现,LoRA和全参数微调产生的权重矩阵的奇异值分解表现出非常不同的结构:用LoRA训练的权重矩阵具有新的、高秩的奇异向量,我们称之为“入侵维度”,而用全参数微调训练的权重矩阵则没有。此外,我们扩展了LoRA比全参数微调遗忘更少的发现,并发现其遗忘主要集中在入侵维度上——通过因果干预入侵维度,改变微调后与其相关的奇异值,我们表明它们会导致遗忘。而且,显著缩小它们可以显著改善预训练分布的建模,同时下游任务性能的下降很小。鉴于此,我们应该预期累积的入侵维度是有害的,并导致更多的遗忘。这将在持续学习期间因顺序微调而被放大,我们表明LoRA模型在这里确实会累积入侵维度,并且往往在这种设置中表现更差,强调了我们发现的实用性。
🔬 方法详解
问题定义:论文旨在研究LoRA(Low-Rank Adaptation)和全参数微调在适配预训练大型语言模型到下游任务时,其学习到的模型参数是否真正等价。现有方法,特别是LoRA,虽然参数效率高,但其对模型权重的影响机制尚不明确,可能导致一些未知的副作用,例如灾难性遗忘等。
核心思路:论文的核心思路是通过分析微调后模型权重矩阵的谱特性,特别是奇异值分解(SVD),来揭示LoRA和全参数微调对模型参数的不同影响。LoRA可能引入新的、高秩的奇异向量(即“入侵维度”),而全参数微调则不会。通过干预这些“入侵维度”,可以研究它们对模型性能和遗忘行为的影响。
技术框架:论文的技术框架主要包括以下几个步骤:1) 使用LoRA和全参数微调分别对预训练模型进行微调;2) 对微调后的模型权重矩阵进行奇异值分解;3) 分析LoRA和全参数微调得到的奇异值分解结果,识别“入侵维度”;4) 通过因果干预“入侵维度”(例如,改变其奇异值),研究其对模型性能和遗忘行为的影响;5) 在持续学习场景下,评估LoRA模型累积“入侵维度”的情况,并分析其对性能的影响。
关键创新:论文最重要的技术创新点在于发现了LoRA微调会在模型权重矩阵中引入新的、高秩的奇异向量,即“入侵维度”。这些“入侵维度”是LoRA和全参数微调之间的本质区别,并且与模型的遗忘行为密切相关。通过对“入侵维度”的分析和干预,可以更好地理解LoRA的工作机制,并指导其在实际应用中的优化。
关键设计:论文的关键设计包括:1) 使用奇异值分解来分析模型权重矩阵的谱特性;2) 定义“入侵维度”为LoRA微调引入的新的、高秩的奇异向量;3) 通过改变“入侵维度”的奇异值来进行因果干预,研究其对模型性能和遗忘行为的影响;4) 在持续学习场景下,评估LoRA模型累积“入侵维度”的情况。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LoRA微调后的模型权重矩阵存在“入侵维度”,而全参数微调则没有。通过干预这些“入侵维度”,可以显著影响模型的遗忘行为,并且缩小这些维度可以改善预训练分布的建模,同时下游任务性能下降很小。在持续学习中,LoRA模型会累积“入侵维度”,导致性能下降。
🎯 应用场景
该研究成果可应用于大型语言模型的微调策略优化,尤其是在资源受限或需要持续学习的场景下。通过理解LoRA引入的“入侵维度”的影响,可以设计更有效的微调方法,减少灾难性遗忘,提升模型在各种任务上的泛化能力。此外,该研究也为理解其他参数高效微调方法提供了新的视角。
📄 摘要(原文)
Fine-tuning is a crucial paradigm for adapting pre-trained large language models to downstream tasks. Recently, methods like Low-Rank Adaptation (LoRA) have been shown to effectively fine-tune LLMs with an extreme reduction in trainable parameters. But, \emph{are their learned solutions really equivalent?} We study how LoRA and full-finetuning change pre-trained models by analyzing the model's weight matrices through the lens of their spectral properties. We find that LoRA and full fine-tuning yield weight matrices whose singular value decompositions exhibit very different structure: weight matrices trained with LoRA have new, high-ranking singular vectors, which we call \emph{intruder dimensions}, while those trained with full fine-tuning do not. Further, we extend the finding that LoRA forgets less than full fine-tuning and find its forgetting is vastly localized to the intruder dimension -- by causally intervening on the intruder dimensions by changing their associated singular values post-fine-tuning, we show that they cause forgetting. Moreover, scaling them down significantly improves modeling of the pre-training distribution with a minimal drop in downstream task performance. Given this, we should expect accumulating intruder dimensions to be harmful and lead to more forgetting. This will be amplified during continual learning because of sequentially fine-tuning, and we show that LoRA models do accumulate intruder dimensions here tend to perform worse in this setting, emphasizing the practicality of our findings.